 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyGen: Audio-Driven 3D Depth-Aware Talking-Face Video Editing
Jan 03, 2025



Significant progress has been made in talking-face video generation research; however, precise lip-audio synchronization and high visual quality remain challenging in editing lip shapes based on input audio. This paper introduces JoyGen, a novel two-stage framework for talking-face generation, comprising audio-driven lip motion generation and visual appearance synthesis. In the first stage, a 3D reconstruction model and an audio2motion model predict identity and expression coefficients respectively. Next, by integrating audio features with a facial depth map, we provide comprehensive supervision for precise lip-audio synchronization in facial generation. Additionally, we constructed a Chinese talking-face dataset containing 130 hours of high-quality video. JoyGen is trained on the open-source HDTF dataset and our curated dataset. Experimental results demonstrate superior lip-audio synchronization and visual quality achieved by our method.
FILTRA: Rethinking Steerable CNN by Filter Transform
May 25, 2021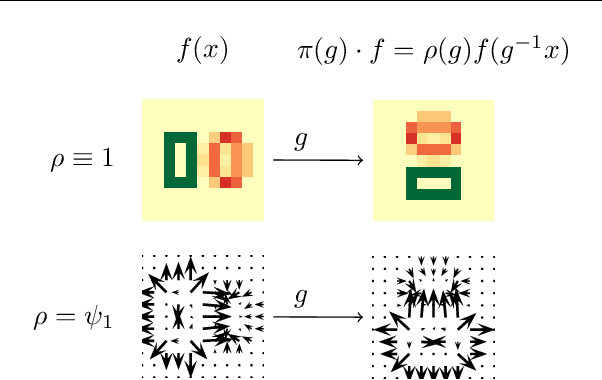
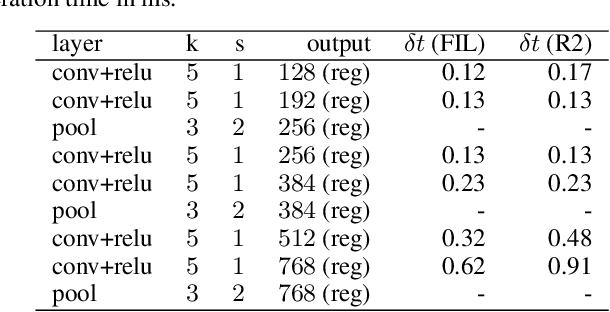
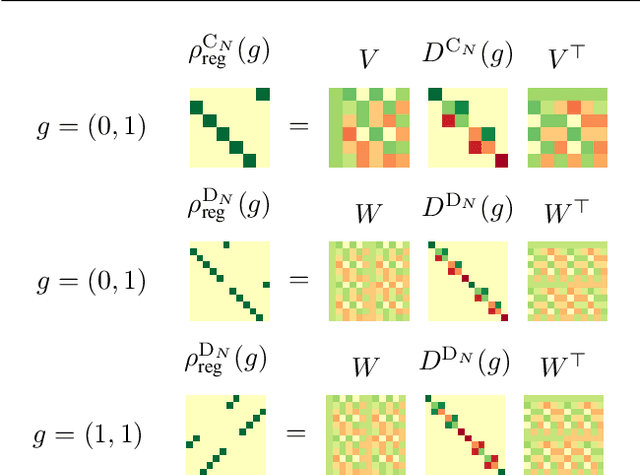
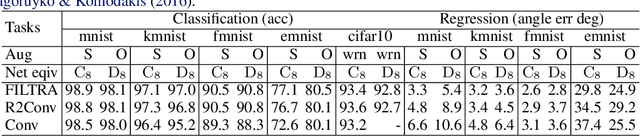
Steerable CNN imposes the prior knowledge of transformation invariance or equivariance in the network architecture to enhance the the network robustness on geometry transformation of data and reduce overfitting. It has been an intuitive and widely used technique to construct a steerable filter by augmenting a filter with its transformed copies in the past decades, which is named as filter transform in this paper. Recently, the problem of steerable CNN has been studied from aspect of group representation theory, which reveals the function space structure of a steerable kernel function. However, it is not yet clear on how this theory is related to the filter transform technique. In this paper, we show that kernel constructed by filter transform can also be interpreted in the group representation theory. This interpretation help complete the puzzle of steerable CNN theory and provides a novel and simple approach to implement steerable convolution operators. Experiments are executed on multiple datasets to verify the feasibility of the proposed approach.