 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Local-Temporal Similarity Fusion for Continuous Sign Language Recognition
Jul 27, 2021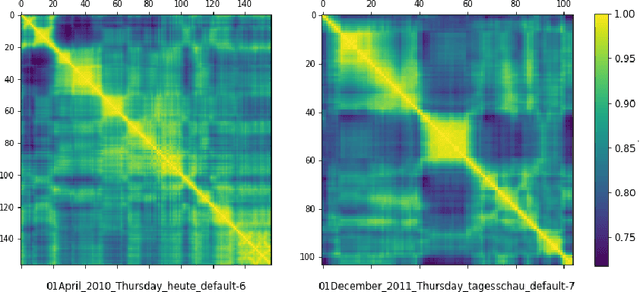

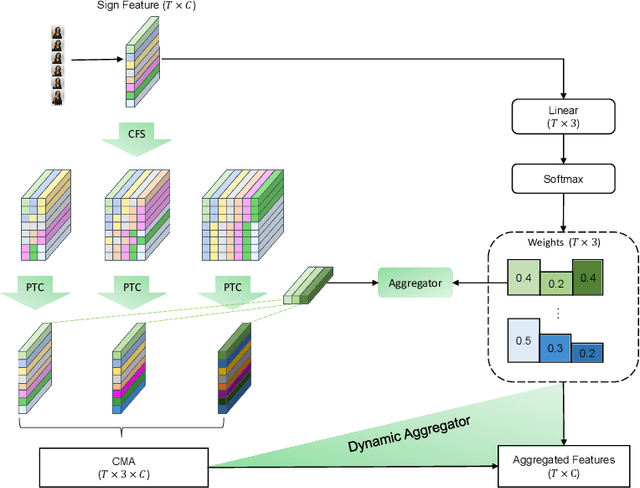

Continuous sign language recognition (cSLR) is a public significant task that transcribes a sign language video into an ordered gloss sequence. It is important to capture the fine-grained gloss-level details, since there is no explicit alignment between sign video frames and the corresponding glosses. Among the past works, one promising way is to adopt a one-dimensional convolutional network (1D-CNN) to temporally fuse the sequential frames. However, CNNs are agnostic to similarity or dissimilarity, and thus are unable to capture local consistent semantics within temporally neighboring frames. To address the issue, we propose to adaptively fuse local features via temporal similarity for this task. Specifically, we devise a Multi-scale Local-Temporal Similarity Fusion Network (mLTSF-Net) as follows: 1) In terms of a specific video frame, we firstly select its similar neighbours with multi-scale receptive regions to accommodate different lengths of glosses. 2) To ensure temporal consistency, we then use position-aware convolution to temporally convolve each scale of selected frames. 3) To obtain a local-temporally enhanced frame-wise representation, we finally fuse the results of different scales using a content-dependent aggregator. We train our model in an end-to-end fashion, and the experimental results on RWTH-PHOENIX-Weather 2014 datasets (RWTH) demonstrate that our model achieves competitive performance compared with several state-of-the-art models.
Writing Polishment with Simile: Task, Dataset and A Neural Approach
Dec 15, 2020
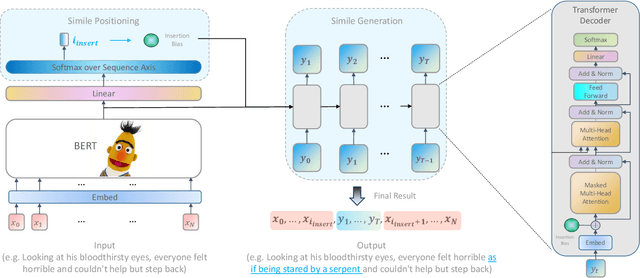
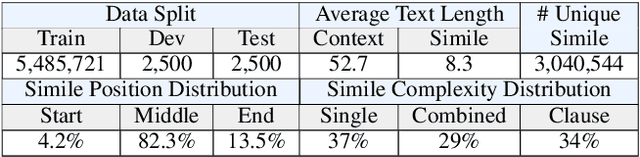

A simile is a figure of speech that directly makes a comparison, showing similarities between two different things, e.g. "Reading papers can be dull sometimes,like watching grass grow". Human writers often interpolate appropriate similes into proper locations of the plain text to vivify their writings. However, none of existing work has explored neural simile interpolation, including both locating and generation. In this paper, we propose a new task of Writing Polishment with Simile (WPS) to investigate whether machines are able to polish texts with similes as we human do. Accordingly, we design a two-staged Locate&Gen model based on transformer architecture. Our model firstly locates where the simile interpolation should happen, and then generates a location-specific simile. We also release a large-scale Chinese Simile (CS) dataset containing 5 million similes with context. The experimental results demonstrate the feasibility of WPS task and shed light on the future research directions towards better automatic text polishment.
Reasoning in Dialog: Improving Response Generation by Context Reading Comprehension
Dec 14, 2020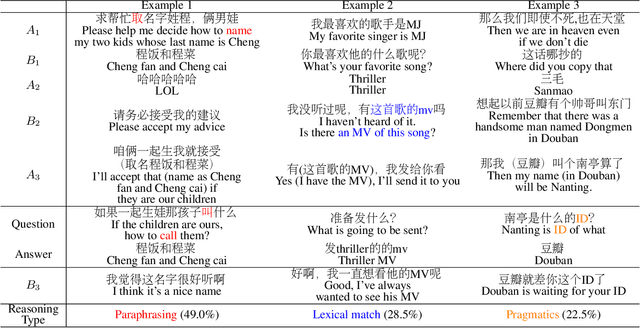
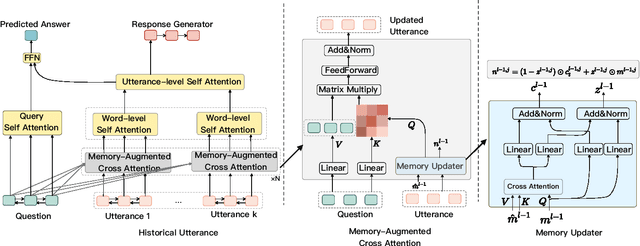
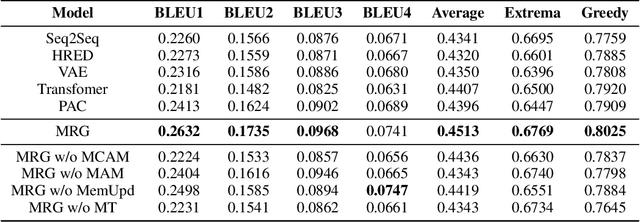
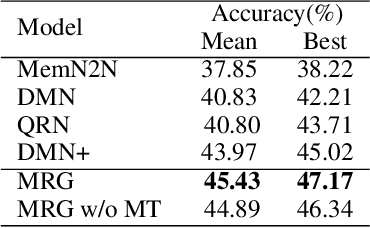
In multi-turn dialog, utterances do not always take the full form of sentences \cite{Carbonell1983DiscoursePA}, which naturally makes understanding the dialog context more difficult. However, it is essential to fully grasp the dialog context to generate a reasonable response. Hence, in this paper, we propose to improve the response generation performance by examining the model's ability to answer a reading comprehension question, where the question is focused on the omitted information in the dialog. Enlightened by the multi-task learning scheme, we propose a joint framework that unifies these two tasks, sharing the same encoder to extract the common and task-invariant features with different decoders to learn task-specific features. To better fusing information from the question and the dialog history in the encoding part, we propose to augment the Transformer architecture with a memory updater, which is designed to selectively store and update the history dialog information so as to support downstream tasks. For the experiment, we employ human annotators to write and examine a large-scale dialog reading comprehension dataset. Extensive experiments are conducted on this dataset, and the results show that the proposed model brings substantial improvements over several strong baselines on both tasks. In this way, we demonstrate that reasoning can indeed help better response generation and vice versa. We release our large-scale dataset for further research.
* 9 pages, 1 figure
Infusing Sequential Information into Conditional Masked Translation Model with Self-Review Mechanism
Oct 26, 2020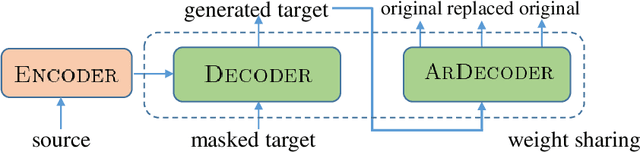
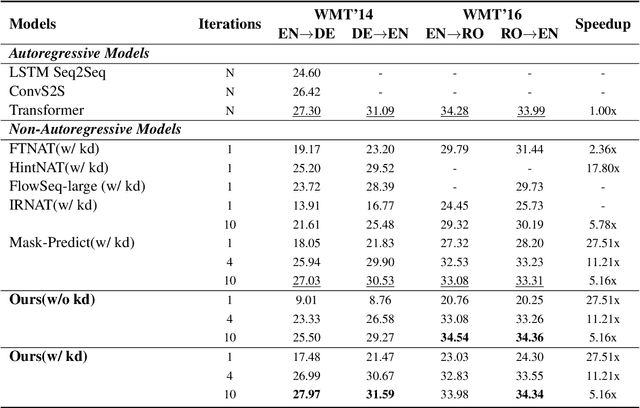
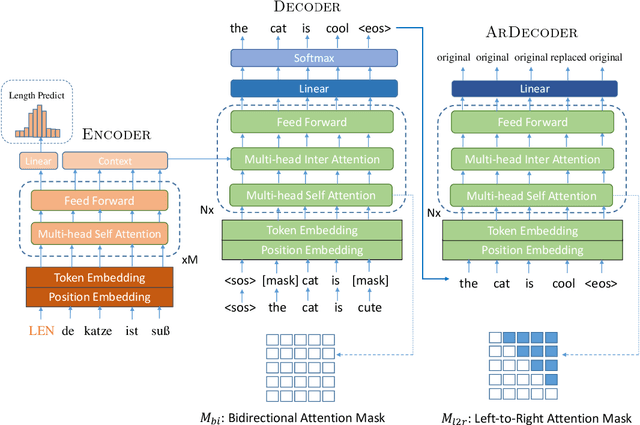
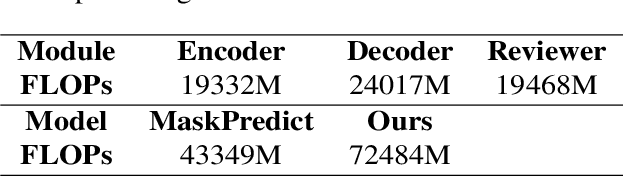
Non-autoregressive models generate target words in a parallel way, which achieve a faster decoding speed but at the sacrifice of translation accuracy. To remedy a flawed translation by non-autoregressive models, a promising approach is to train a conditional masked translation model (CMTM), and refine the generated results within several iterations. Unfortunately, such approach hardly considers the \textit{sequential dependency} among target words, which inevitably results in a translation degradation. Hence, instead of solely training a Transformer-based CMTM, we propose a Self-Review Mechanism to infuse sequential information into it. Concretely, we insert a left-to-right mask to the same decoder of CMTM, and then induce it to autoregressively review whether each generated word from CMTM is supposed to be replaced or kept. The experimental results (WMT14 En$\leftrightarrow$De and WMT16 En$\leftrightarrow$Ro) demonstrate that our model uses dramatically less training computations than the typical CMTM, as well as outperforms several state-of-the-art non-autoregressive models by over 1 BLEU. Through knowledge distillation, our model even surpasses a typical left-to-right Transformer model, while significantly speeding up decoding.
Focus-Constrained Attention Mechanism for CVAE-based Response Generation
Sep 25, 2020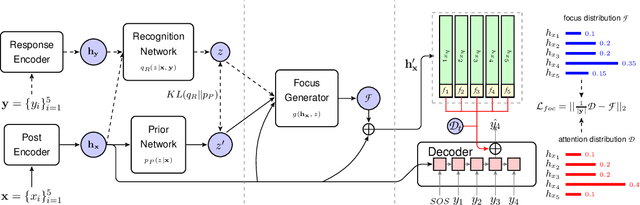
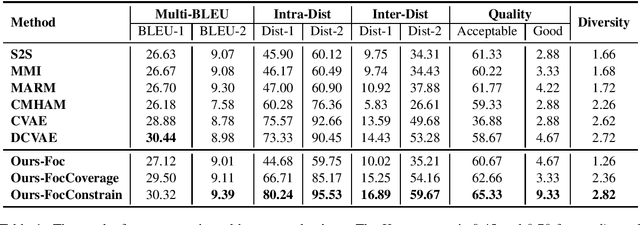
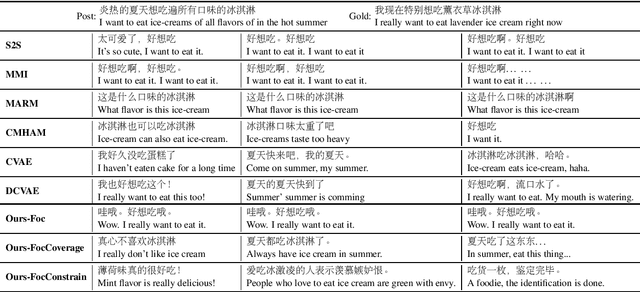
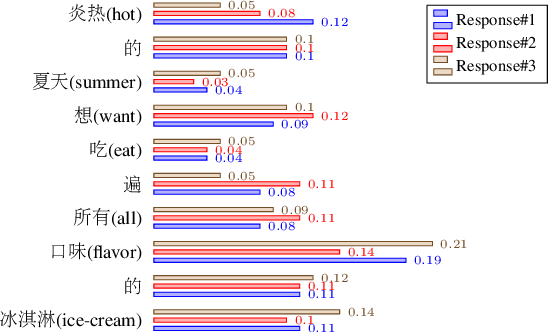
To model diverse responses for a given post, one promising way is to introduce a latent variable into Seq2Seq models. The latent variable is supposed to capture the discourse-level information and encourage the informativeness of target responses. However, such discourse-level information is often too coarse for the decoder to be utilized. To tackle it, our idea is to transform the coarse-grained discourse-level information into fine-grained word-level information. Specifically, we firstly measure the semantic concentration of corresponding target response on the post words by introducing a fine-grained focus signal. Then, we propose a focus-constrained attention mechanism to take full advantage of focus in well aligning the input to the target response. The experimental results demonstrate that by exploiting the fine-grained signal, our model can generate more diverse and informative responses compared with several state-of-the-art models.