 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Factorization Machines via Saliency-Guided Mixup
Paper and Code


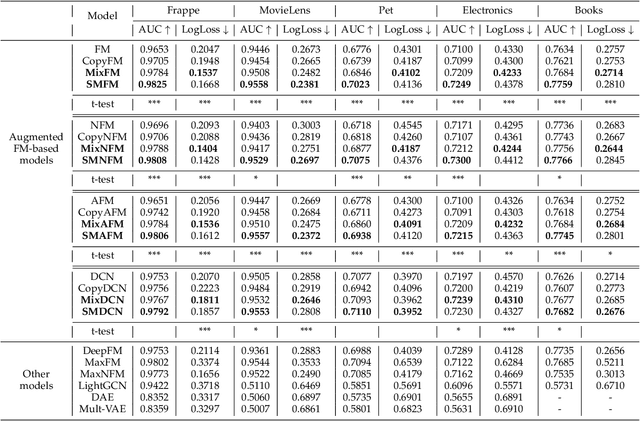

Factorization machines (FMs) are widely used in recommender systems due to their adaptability and ability to learn from sparse data. However, for the ubiquitous non-interactive features in sparse data, existing FMs can only estimate the parameters corresponding to these features via the inner product of their embeddings. Undeniably, they cannot learn the direct interactions of these features, which limits the model's expressive power. To this end, we first present MixFM, inspired by Mixup, to generate auxiliary training data to boost FMs. Unlike existing augmentation strategies that require labor costs and expertise to collect additional information such as position and fields, these extra data generated by MixFM only by the convex combination of the raw ones without any professional knowledge support. More importantly, if the parent samples to be mixed have non-interactive features, MixFM will establish their direct interactions. Second, considering that MixFM may generate redundant or even detrimental instances, we further put forward a novel Factorization Machine powered by Saliency-guided Mixup (denoted as SMFM). Guided by the customized saliency, SMFM can generate more informative neighbor data. Through theoretical analysis, we prove that the proposed methods minimize the upper bound of the generalization error, which hold a beneficial effect on enhancing FMs. Significantly, we give the first generalization bound of FM, implying the generalization requires more data and a smaller embedding size under the sufficient representation capability. Finally, extensive experiments on five datasets confirm that our approaches are superior to baselines. Besides, the results show that "poisoning" mixed data is likewise beneficial to the FM variants.