 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Pass$\mathtt{@}k$: A Bayesian Framework for Large Language Model Evaluation
Oct 05, 2025Pass$@k$ is widely used to report performance for LLM reasoning, but it often yields unstable, misleading rankings, especially when the number of trials (samples) is limited and compute is constrained. We present a principled Bayesian evaluation framework that replaces Pass$@k$ and average accuracy over $N$ trials (avg$@N$) with posterior estimates of a model's underlying success probability and credible intervals, yielding stable rankings and a transparent decision rule for differences. Evaluation outcomes are modeled as categorical (not just 0/1) with a Dirichlet prior, giving closed-form expressions for the posterior mean and uncertainty of any weighted rubric and enabling the use of prior evidence when appropriate. Theoretically, under a uniform prior, the Bayesian posterior mean is order-equivalent to average accuracy (Pass$@1$), explaining its empirical robustness while adding principled uncertainty. Empirically, in simulations with known ground-truth success rates and on AIME'24/'25, HMMT'25, and BrUMO'25, the Bayesian/avg procedure achieves faster convergence and greater rank stability than Pass$@k$ and recent variants, enabling reliable comparisons at far smaller sample counts. The framework clarifies when observed gaps are statistically meaningful (non-overlapping credible intervals) versus noise, and it naturally extends to graded, rubric-based evaluations. Together, these results recommend replacing Pass$@k$ for LLM evaluation and ranking with a posterior-based, compute-efficient protocol that unifies binary and non-binary evaluation while making uncertainty explicit. Code is available at https://mohsenhariri.github.io/bayes-kit
$K^4$: Online Log Anomaly Detection Via Unsupervised Typicality Learning
Jul 26, 2025Existing Log Anomaly Detection (LogAD) methods are often slow, dependent on error-prone parsing, and use unrealistic evaluation protocols. We introduce $K^4$, an unsupervised and parser-independent framework for high-performance online detection. $K^4$ transforms arbitrary log embeddings into compact four-dimensional descriptors (Precision, Recall, Density, Coverage) using efficient k-nearest neighbor (k-NN) statistics. These descriptors enable lightweight detectors to accurately score anomalies without retraining. Using a more realistic online evaluation protocol, $K^4$ sets a new state-of-the-art (AUROC: 0.995-0.999), outperforming baselines by large margins while being orders of magnitude faster, with training under 4 seconds and inference as low as 4 $\mu$s.
More for Keys, Less for Values: Adaptive KV Cache Quantization
Feb 20, 2025This paper introduces an information-aware quantization framework that adaptively compresses the key-value (KV) cache in large language models (LLMs). Although prior work has underscored the distinct roles of key and value cache during inference, our systematic analysis -- examining singular value distributions, spectral norms, and Frobenius norms -- reveals, for the first time, that key matrices consistently exhibit higher norm values and are more sensitive to quantization than value matrices. Furthermore, our theoretical analysis shows that matrices with higher spectral norms amplify quantization errors more significantly. Motivated by these insights, we propose a mixed-precision quantization strategy, KV-AdaQuant, which allocates more bit-width for keys and fewer for values since key matrices have higher norm values. With the same total KV bit budget, this approach effectively mitigates error propagation across transformer layers while achieving significant memory savings. Our extensive experiments on multiple LLMs (1B--70B) demonstrate that our mixed-precision quantization scheme maintains high model accuracy even under aggressive compression. For instance, using 4-bit for Key and 2-bit for Value achieves an accuracy of 75.2%, whereas reversing the assignment (2-bit for Key and 4-bit for Value) yields only 54.7% accuracy. The code is available at https://tinyurl.com/kv-adaquant
Novel adaptation of video segmentation to 3D MRI: efficient zero-shot knee segmentation with SAM2
Aug 08, 2024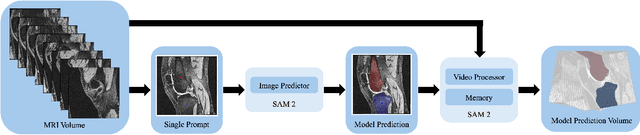
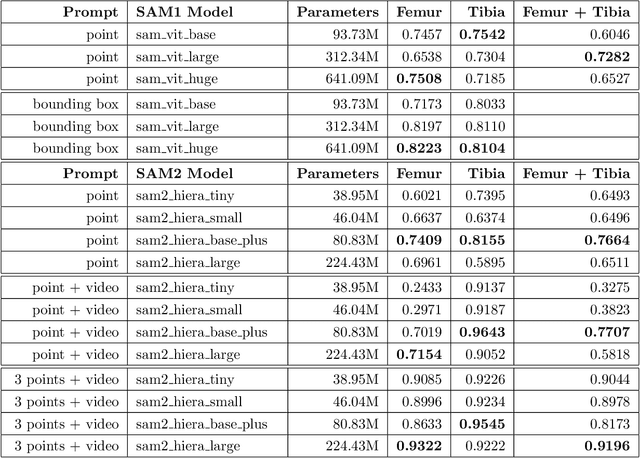
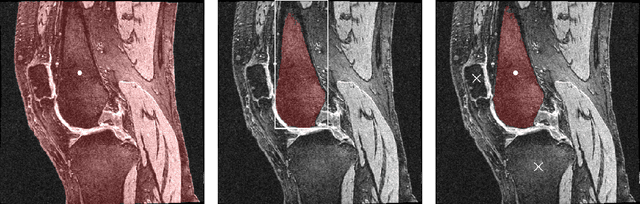
Intelligent medical image segmentation methods are rapidly evolving and being increasingly applied, yet they face the challenge of domain transfer, where algorithm performance degrades due to different data distributions between source and target domains. To address this, we introduce a method for zero-shot, single-prompt segmentation of 3D knee MRI by adapting Segment Anything Model 2 (SAM2), a general-purpose segmentation model designed to accept prompts and retain memory across frames of a video. By treating slices from 3D medical volumes as individual video frames, we leverage SAM2's advanced capabilities to generate motion- and spatially-aware predictions. We demonstrate that SAM2 can efficiently perform segmentation tasks in a zero-shot manner with no additional training or fine-tuning, accurately delineating structures in knee MRI scans using only a single prompt. Our experiments on the Osteoarthritis Initiative Zuse Institute Berlin (OAI-ZIB) dataset reveal that SAM2 achieves high accuracy on 3D knee bone segmentation, with a testing Dice similarity coefficient of 0.9643 on tibia. We also present results generated using different SAM2 model sizes, different prompt schemes, as well as comparative results from the SAM1 model deployed on the same dataset. This breakthrough has the potential to revolutionize medical image analysis by providing a scalable, cost-effective solution for automated segmentation, paving the way for broader clinical applications and streamlined workflows.