 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident or Seek Stronger: Exploring Uncertainty-Based On-device LLM Routing From Benchmarking to Generalization
Feb 06, 2025Large language models (LLMs) are increasingly deployed and democratized on edge devices. To improve the efficiency of on-device deployment, small language models (SLMs) are often adopted due to their efficient decoding latency and reduced energy consumption. However, these SLMs often generate inaccurate responses when handling complex queries. One promising solution is uncertainty-based SLM routing, offloading high-stakes queries to stronger LLMs when resulting in low-confidence responses on SLM. This follows the principle of "If you lack confidence, seek stronger support" to enhance reliability. Relying on more powerful LLMs is yet effective but increases invocation costs. Therefore, striking a routing balance between efficiency and efficacy remains a critical challenge. Additionally, efficiently generalizing the routing strategy to new datasets remains under-explored. In this paper, we conduct a comprehensive investigation into benchmarking and generalization of uncertainty-driven routing strategies from SLMs to LLMs over 1500+ settings. Our findings highlight: First, uncertainty-correctness alignment in different uncertainty quantification (UQ) methods significantly impacts routing performance. Second, uncertainty distributions depend more on both the specific SLM and the chosen UQ method, rather than downstream data. Building on the insight, we propose a calibration data construction instruction pipeline and open-source a constructed hold-out set to enhance routing generalization on new downstream scenarios. The experimental results indicate calibration data effectively bootstraps routing performance without any new data.
Large Language Models As Faithful Explainers
Feb 07, 2024Large Language Models (LLMs) have recently become proficient in addressing complex tasks by utilizing their rich internal knowledge and reasoning ability. Consequently, this complexity hinders traditional input-focused explanation algorithms for explaining the complex decision-making processes of LLMs. Recent advancements have thus emerged for self-explaining their predictions through a single feed-forward inference in a natural language format. However, natural language explanations are often criticized for lack of faithfulness since these explanations may not accurately reflect the decision-making behaviors of the LLMs. In this work, we introduce a generative explanation framework, xLLM, to improve the faithfulness of the explanations provided in natural language formats for LLMs. Specifically, we propose an evaluator to quantify the faithfulness of natural language explanation and enhance the faithfulness by an iterative optimization process of xLLM, with the goal of maximizing the faithfulness scores. Experiments conducted on three NLU datasets demonstrate that xLLM can significantly improve the faithfulness of generated explanations, which are in alignment with the behaviors of LLMs.
LETA: Learning Transferable Attribution for Generic Vision Explainer
Dec 23, 2023Explainable machine learning significantly improves the transparency of deep neural networks~(DNN). However, existing work is constrained to explaining the behavior of individual model predictions, and lacks the ability to transfer the explanation across various models and tasks. This limitation results in explaining various tasks being time- and resource-consuming. To address this problem, we develop a pre-trained, DNN-based, generic explainer on large-scale image datasets, and leverage its transferability to explain various vision models for downstream tasks. In particular, the pre-training of generic explainer focuses on LEarning Transferable Attribution (LETA). The transferable attribution takes advantage of the versatile output of the target backbone encoders to comprehensively encode the essential attribution for explaining various downstream tasks. LETA guides the pre-training of the generic explainer towards the transferable attribution, and introduces a rule-based adaptation of the transferable attribution for explaining downstream tasks, without the need for additional training on downstream data. Theoretical analysis demonstrates that the pre-training of LETA enables minimizing the explanation error bound aligned with the conditional $\mathcal{V}$-information on downstream tasks. Empirical studies involve explaining three different architectures of vision models across three diverse downstream datasets. The experiment results indicate LETA is effective in explaining these tasks without the need for additional training on the data of downstream tasks.
CoRTX: Contrastive Framework for Real-time Explanation
Mar 05, 2023
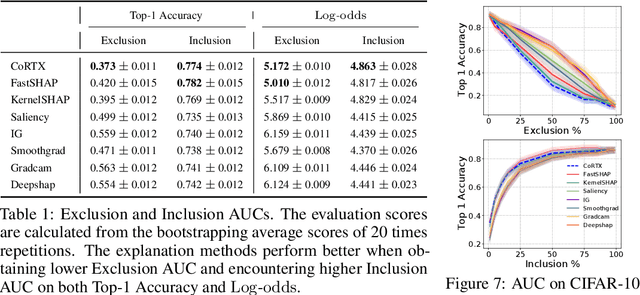


Recent advancements in explainable machine learning provide effective and faithful solutions for interpreting model behaviors. However, many explanation methods encounter efficiency issues, which largely limit their deployments in practical scenarios. Real-time explainer (RTX) frameworks have thus been proposed to accelerate the model explanation process by learning a one-feed-forward explainer. Existing RTX frameworks typically build the explainer under the supervised learning paradigm, which requires large amounts of explanation labels as the ground truth. Considering that accurate explanation labels are usually hard to obtain due to constrained computational resources and limited human efforts, effective explainer training is still challenging in practice. In this work, we propose a COntrastive Real-Time eXplanation (CoRTX) framework to learn the explanation-oriented representation and relieve the intensive dependence of explainer training on explanation labels. Specifically, we design a synthetic strategy to select positive and negative instances for the learning of explanation. Theoretical analysis show that our selection strategy can benefit the contrastive learning process on explanation tasks. Experimental results on three real-world datasets further demonstrate the efficiency and efficacy of our proposed CoRTX framework.
Efficient XAI Techniques: A Taxonomic Survey
Feb 16, 2023Recently, there has been a growing demand for the deployment of Explainable Artificial Intelligence (XAI) algorithms in real-world applications. However, traditional XAI methods typically suffer from a high computational complexity problem, which discourages the deployment of real-time systems to meet the time-demanding requirements of real-world scenarios. Although many approaches have been proposed to improve the efficiency of XAI methods, a comprehensive understanding of the achievements and challenges is still needed. To this end, in this paper we provide a review of efficient XAI. Specifically, we categorize existing techniques of XAI acceleration into efficient non-amortized and efficient amortized methods. The efficient non-amortized methods focus on data-centric or model-centric acceleration upon each individual instance. In contrast, amortized methods focus on learning a unified distribution of model explanations, following the predictive, generative, or reinforcement frameworks, to rapidly derive multiple model explanations. We also analyze the limitations of an efficient XAI pipeline from the perspectives of the training phase, the deployment phase, and the use scenarios. Finally, we summarize the challenges of deploying XAI acceleration methods to real-world scenarios, overcoming the trade-off between faithfulness and efficiency, and the selection of different acceleration methods.
Accelerating Shapley Explanation via Contributive Cooperator Selection
Jun 17, 2022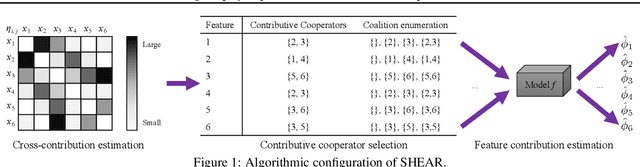
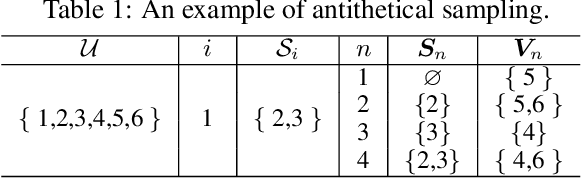
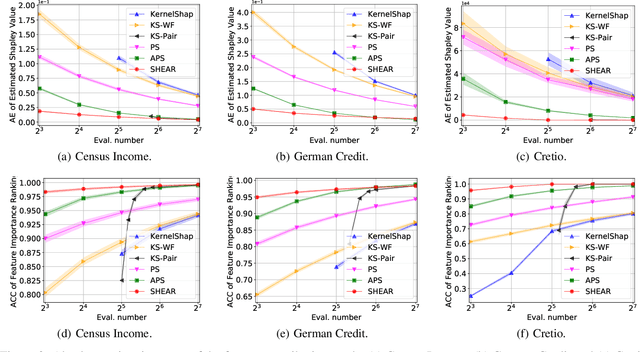

Even though Shapley value provides an effective explanation for a DNN model prediction, the computation relies on the enumeration of all possible input feature coalitions, which leads to the exponentially growing complexity. To address this problem, we propose a novel method SHEAR to significantly accelerate the Shapley explanation for DNN models, where only a few coalitions of input features are involved in the computation. The selection of the feature coalitions follows our proposed Shapley chain rule to minimize the absolute error from the ground-truth Shapley values, such that the computation can be both efficient and accurate. To demonstrate the effectiveness, we comprehensively evaluate SHEAR across multiple metrics including the absolute error from the ground-truth Shapley value, the faithfulness of the explanations, and running speed. The experimental results indicate SHEAR consistently outperforms state-of-the-art baseline methods across different evaluation metrics, which demonstrates its potentials in real-world applications where the computational resource is limited.
Simplicial Complex Representation Learning
Mar 09, 2021



Simplicial complexes form an important class of topological spaces that are frequently used to in many applications areas such as computer-aided design, computer graphics, and simulation. The representation learning on graphs, which are just 1-d simplicial complexes, has witnessed a great attention and success in the past few years. Due to the additional complexity higher dimensional simplicial hold, there has not been enough effort to extend representation learning to these objects especially when it comes to learn entire-simplicial complex representation. In this work, we propose a method for simplicial complex-level representation learning that embeds a simplicial complex to a universal embedding space in a way that complex-to-complex proximity is preserved. Our method utilizes a simplex-level embedding induced by a pre-trained simplicial autoencoder to learn an entire simplicial complex representation. To the best of our knowledge, this work presents the first method for learning simplicial complex-level representation.
Persistent Homology and Graphs Representation Learning
Mar 02, 2021
This article aims to study the topological invariant properties encoded in node graph representational embeddings by utilizing tools available in persistent homology. Specifically, given a node embedding representation algorithm, we consider the case when these embeddings are real-valued. By viewing these embeddings as scalar functions on a domain of interest, we can utilize the tools available in persistent homology to study the topological information encoded in these representations. Our construction effectively defines a unique persistence-based graph descriptor, on both the graph and node levels, for every node representation algorithm. To demonstrate the effectiveness of the proposed method, we study the topological descriptors induced by DeepWalk, Node2Vec and Diff2Vec.