 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deformable Medical Image Registration via Pyramidal Residual Deformation Fields Estimation
Apr 16, 2020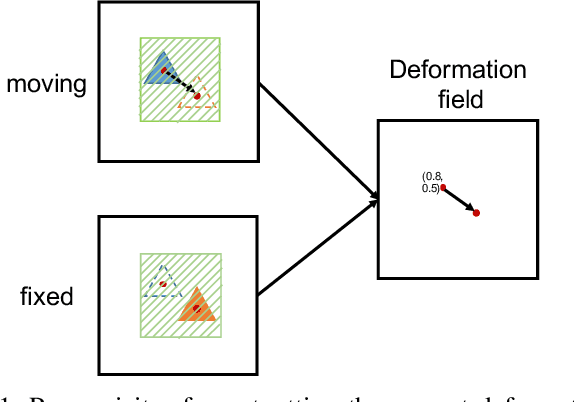
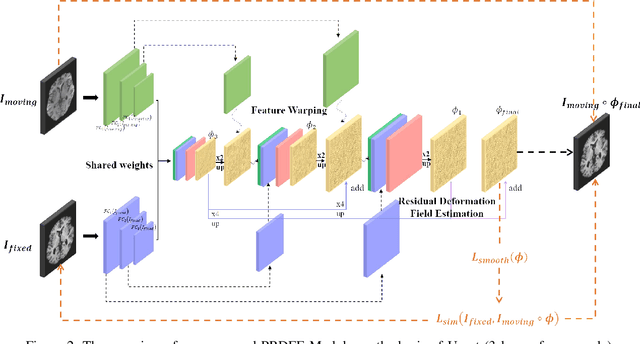


Deformation field estimation is an important and challenging issue in many medical image registration applications. In recent years, deep learning technique has become a promising approach for simplifying registration problems, and has been gradually applied to medical image registration. However, most existing deep learning registrations do not consider the problem that when the receptive field cannot cover the corresponding features in the moving image and the fixed image, it cannot output accurate displacement values. In fact, due to the limitation of the receptive field, the 3 x 3 kernel has difficulty in covering the corresponding features at high/original resolution. Multi-resolution and multi-convolution techniques can improve but fail to avoid this problem. In this study, we constructed pyramidal feature sets on moving and fixed images and used the warped moving and fixed features to estimate their "residual" deformation field at each scale, called the Pyramidal Residual Deformation Field Estimation module (PRDFE-Module). The "total" deformation field at each scale was computed by upsampling and weighted summing all the "residual" deformation fields at all its previous scales, which can effectively and accurately transfer the deformation fields from low resolution to high resolution and is used for warping the moving features at each scale. Simulation and real brain data results show that our method improves the accuracy of the registration and the rationality of the deformation field.
Cross-lingual Data Transformation and Combination for Text Classification
Jun 23, 2019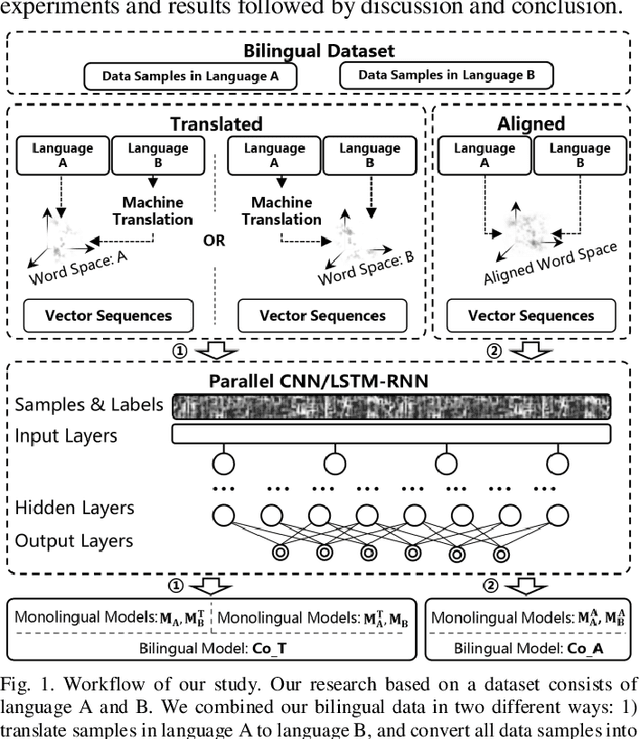
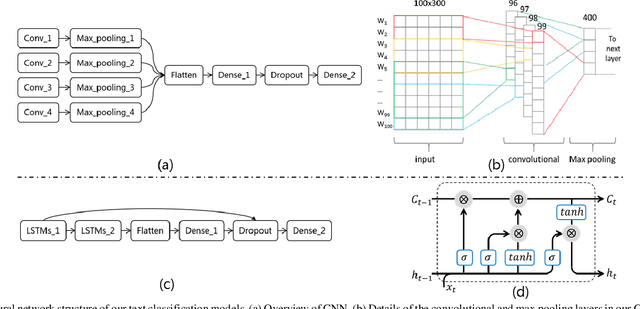
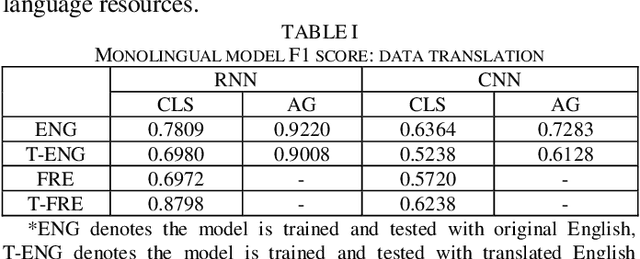
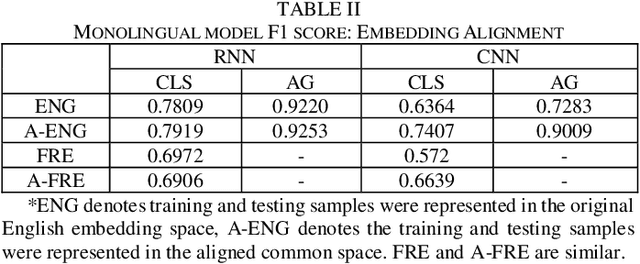
Text classification is a fundamental task for text data mining. In order to train a generalizable model, a large volume of text must be collected. To address data insufficiency, cross-lingual data may occasionally be necessary. Cross-lingual data sources may however suffer from data incompatibility, as text written in different languages can hold distinct word sequences and semantic patterns. Machine translation and word embedding alignment provide an effective way to transform and combine data for cross-lingual data training. To the best of our knowledge, there has been little work done on evaluating how the methodology used to conduct semantic space transformation and data combination affects the performance of classification models trained from cross-lingual resources. In this paper, we systematically evaluated the performance of two commonly used CNN (Convolutional Neural Network) and RNN (Recurrent Neural Network) text classifiers with differing data transformation and combination strategies. Monolingual models were trained from English and French alongside their translated and aligned embeddings. Our results suggested that semantic space transformation may conditionally promote the performance of monolingual models. Bilingual models were trained from a combination of both English and French. Our results indicate that a cross-lingual classification model can significantly benefit from cross-lingual data by learning from translated or aligned embedding spaces.
Direct Automated Quantitative Measurement of Spine via Cascade Amplifier Regression Network
Jun 14, 2018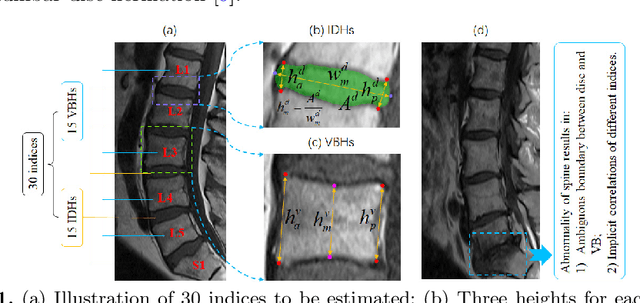
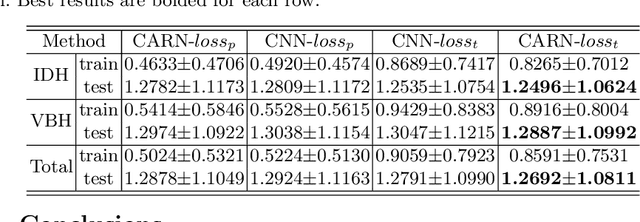
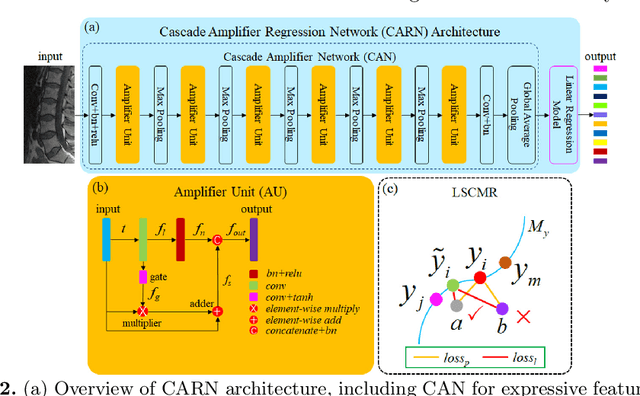
Automated quantitative measurement of the spine (i.e., multiple indices estimation of heights, widths, areas, and so on for the vertebral body and disc) is of the utmost importance in clinical spinal disease diagnoses, such as osteoporosis, intervertebral disc degeneration, and lumbar disc herniation, yet still an unprecedented challenge due to the variety of spine structure and the high dimensionality of indices to be estimated. In this paper, we propose a novel cascade amplifier regression network (CARN), which includes the CARN architecture and local shape-constrained manifold regularization (LSCMR) loss function, to achieve accurate direct automated multiple indices estimation. The CARN architecture is composed of a cascade amplifier network (CAN) for expressive feature embedding and a linear regression model for multiple indices estimation. The CAN consists of cascade amplifier units (AUs), which are used for selective feature reuse by stimulating effective feature and suppressing redundant feature during propagating feature map between adjacent layers, thus an expressive feature embedding is obtained. During training, the LSCMR is utilized to alleviate overfitting and generate realistic estimation by learning the multiple indices distribution. Experiments on MR images of 195 subjects show that the proposed CARN achieves impressive performance with mean absolute errors of 1.2496 mm, 1.2887 mm, and 1.2692 mm for estimation of 15 heights of discs, 15 heights of vertebral bodies, and total indices respectively. The proposed method has great potential in clinical spinal disease diagnoses.