 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Subtraction: Learning Representations for Conditional Entropy
Jan 02, 2025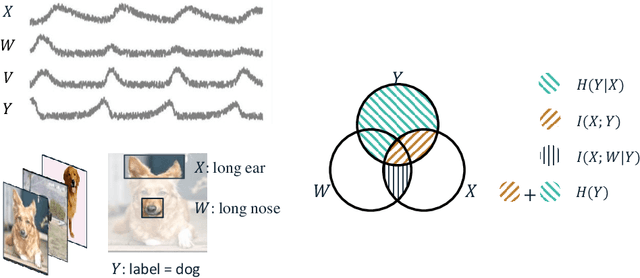
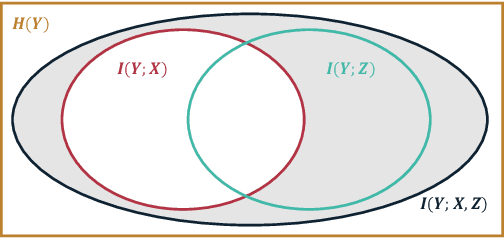
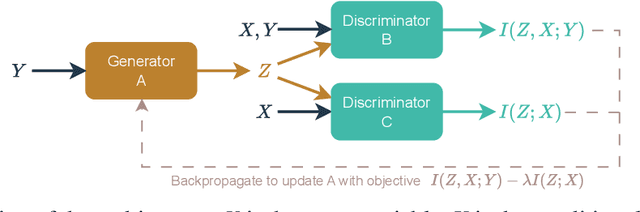
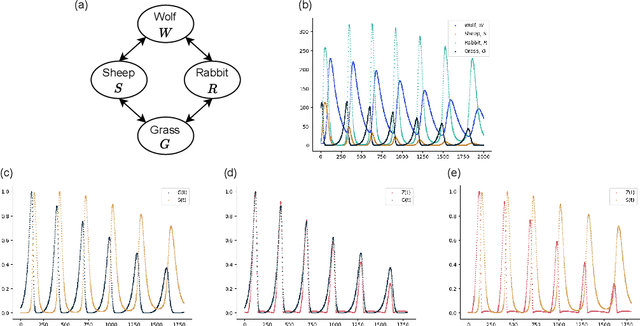
The representations of conditional entropy and conditional mutual information are significant in explaining the unique effects among variables. While previous studies based on conditional contrastive sampling have effectively removed information regarding discrete sensitive variables, they have not yet extended their scope to continuous cases. This paper introduces Information Subtraction, a framework designed to generate representations that preserve desired information while eliminating the undesired. We implement a generative-based architecture that outputs these representations by simultaneously maximizing an information term and minimizing another. With its flexibility in disentangling information, we can iteratively apply Information Subtraction to represent arbitrary information components between continuous variables, thereby explaining the various relationships that exist between them. Our results highlight the representations' ability to provide semantic features of conditional entropy. By subtracting sensitive and domain-specific information, our framework demonstrates effective performance in fair learning and domain generalization. The code for this paper is available at https://github.com/jh-liang/Information-Subtraction
QAEA-DR: A Unified Text Augmentation Framework for Dense Retrieval
Jul 29, 2024



In dense retrieval, embedding long texts into dense vectors can result in information loss, leading to inaccurate query-text matching. Additionally, low-quality texts with excessive noise or sparse key information are unlikely to align well with relevant queries. Recent studies mainly focus on improving the sentence embedding model or retrieval process. In this work, we introduce a novel text augmentation framework for dense retrieval. This framework transforms raw documents into information-dense text formats, which supplement the original texts to effectively address the aforementioned issues without modifying embedding or retrieval methodologies. Two text representations are generated via large language models (LLMs) zero-shot prompting: question-answer pairs and element-driven events. We term this approach QAEA-DR: unifying question-answer generation and event extraction in a text augmentation framework for dense retrieval. To further enhance the quality of generated texts, a scoring-based evaluation and regeneration mechanism is introduced in LLM prompting. Our QAEA-DR model has a positive impact on dense retrieval, supported by both theoretical analysis and empirical experiments.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
A Deep Learning Framework for Traffic Data Imputation Considering Spatiotemporal Dependencies
Apr 18, 2023



Spatiotemporal (ST) data collected by sensors can be represented as multi-variate time series, which is a sequence of data points listed in an order of time. Despite the vast amount of useful information, the ST data usually suffer from the issue of missing or incomplete data, which also limits its applications. Imputation is one viable solution and is often used to prepossess the data for further applications. However, in practice, n practice, spatiotemporal data imputation is quite difficult due to the complexity of spatiotemporal dependencies with dynamic changes in the traffic network and is a crucial prepossessing task for further applications. Existing approaches mostly only capture the temporal dependencies in time series or static spatial dependencies. They fail to directly model the spatiotemporal dependencies, and the representation ability of the models is relatively limited.