 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisrupting Style Mimicry Attacks on Video Imagery
May 11, 2024



Generative AI models are often used to perform mimicry attacks, where a pretrained model is fine-tuned on a small sample of images to learn to mimic a specific artist of interest. While researchers have introduced multiple anti-mimicry protection tools (Mist, Glaze, Anti-Dreambooth), recent evidence points to a growing trend of mimicry models using videos as sources of training data. This paper presents our experiences exploring techniques to disrupt style mimicry on video imagery. We first validate that mimicry attacks can succeed by training on individual frames extracted from videos. We show that while anti-mimicry tools can offer protection when applied to individual frames, this approach is vulnerable to an adaptive countermeasure that removes protection by exploiting randomness in optimization results of consecutive (nearly-identical) frames. We develop a new, tool-agnostic framework that segments videos into short scenes based on frame-level similarity, and use a per-scene optimization baseline to remove inter-frame randomization while reducing computational cost. We show via both image level metrics and an end-to-end user study that the resulting protection restores protection against mimicry (including the countermeasure). Finally, we develop another adaptive countermeasure and find that it falls short against our framework.
Organic or Diffused: Can We Distinguish Human Art from AI-generated Images?
Feb 06, 2024
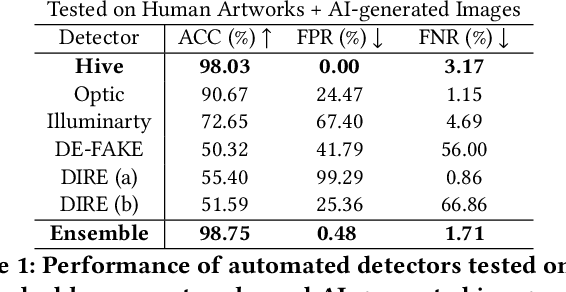
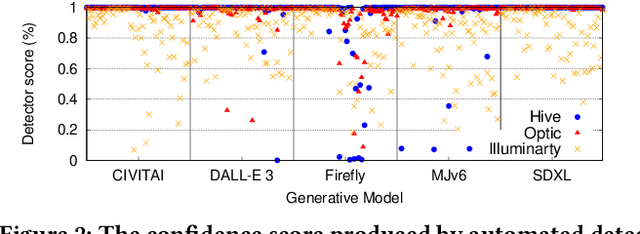
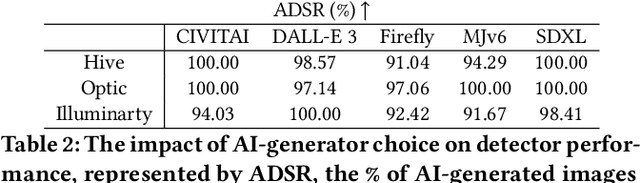
The advent of generative AI images has completely disrupted the art world. Distinguishing AI generated images from human art is a challenging problem whose impact is growing over time. A failure to address this problem allows bad actors to defraud individuals paying a premium for human art and companies whose stated policies forbid AI imagery. It is also critical for content owners to establish copyright, and for model trainers interested in curating training data in order to avoid potential model collapse. There are several different approaches to distinguishing human art from AI images, including classifiers trained by supervised learning, research tools targeting diffusion models, and identification by professional artists using their knowledge of artistic techniques. In this paper, we seek to understand how well these approaches can perform against today's modern generative models in both benign and adversarial settings. We curate real human art across 7 styles, generate matching images from 5 generative models, and apply 8 detectors (5 automated detectors and 3 different human groups including 180 crowdworkers, 4000+ professional artists, and 13 expert artists experienced at detecting AI). Both Hive and expert artists do very well, but make mistakes in different ways (Hive is weaker against adversarial perturbations while Expert artists produce higher false positives). We believe these weaknesses will remain as models continue to evolve, and use our data to demonstrate why a combined team of human and automated detectors provides the best combination of accuracy and robustness.
Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
Oct 20, 2023Data poisoning attacks manipulate training data to introduce unexpected behaviors into machine learning models at training time. For text-to-image generative models with massive training datasets, current understanding of poisoning attacks suggests that a successful attack would require injecting millions of poison samples into their training pipeline. In this paper, we show that poisoning attacks can be successful on generative models. We observe that training data per concept can be quite limited in these models, making them vulnerable to prompt-specific poisoning attacks, which target a model's ability to respond to individual prompts. We introduce Nightshade, an optimized prompt-specific poisoning attack where poison samples look visually identical to benign images with matching text prompts. Nightshade poison samples are also optimized for potency and can corrupt an Stable Diffusion SDXL prompt in <100 poison samples. Nightshade poison effects "bleed through" to related concepts, and multiple attacks can composed together in a single prompt. Surprisingly, we show that a moderate number of Nightshade attacks can destabilize general features in a text-to-image generative model, effectively disabling its ability to generate meaningful images. Finally, we propose the use of Nightshade` and similar tools as a last defense for content creators against web scrapers that ignore opt-out/do-not-crawl directives, and discuss possible implications for model trainers and content creators.
SoK: Anti-Facial Recognition Technology
Dec 08, 2021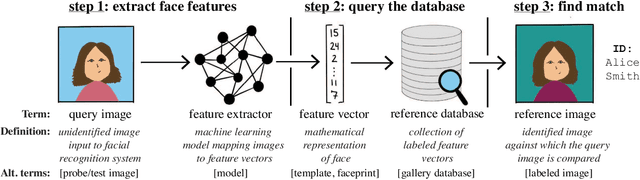
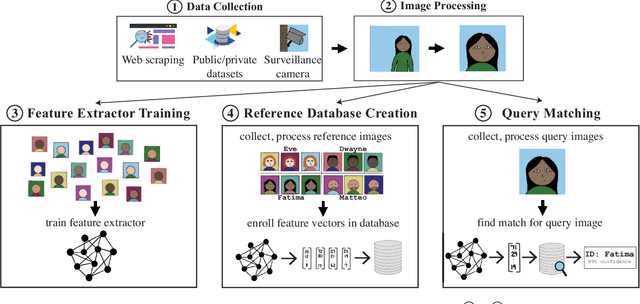

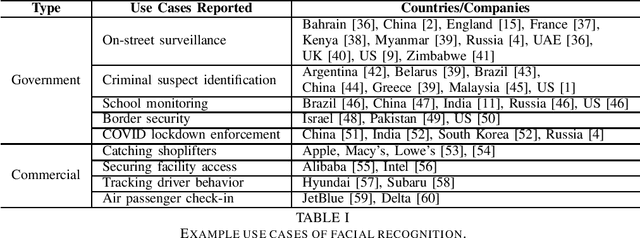
The rapid adoption of facial recognition (FR) technology by both government and commercial entities in recent years has raised concerns about civil liberties and privacy. In response, a broad suite of so-called "anti-facial recognition" (AFR) tools has been developed to help users avoid unwanted facial recognition. The set of AFR tools proposed in the last few years is wide-ranging and rapidly evolving, necessitating a step back to consider the broader design space of AFR systems and long-term challenges. This paper aims to fill that gap and provides the first comprehensive analysis of the AFR research landscape. Using the operational stages of FR systems as a starting point, we create a systematic framework for analyzing the benefits and tradeoffs of different AFR approaches. We then consider both technical and social challenges facing AFR tools and propose directions for future research in this field.
Traceback of Data Poisoning Attacks in Neural Networks
Oct 13, 2021

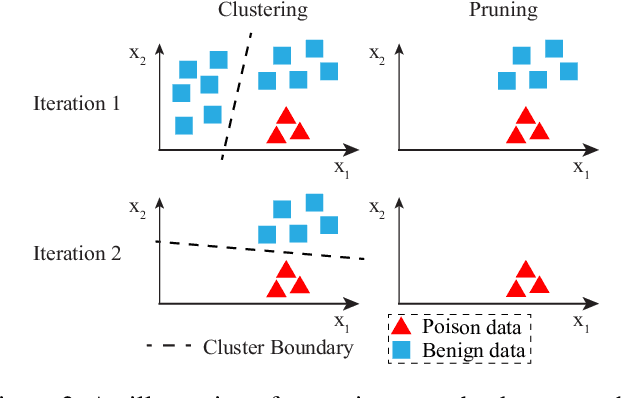
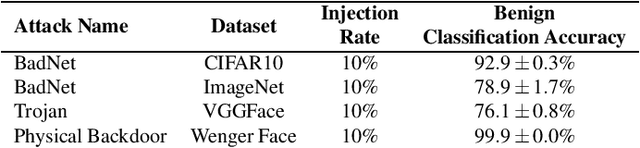
In adversarial machine learning, new defenses against attacks on deep learning systems are routinely broken soon after their release by more powerful attacks. In this context, forensic tools can offer a valuable complement to existing defenses, by tracing back a successful attack to its root cause, and offering a path forward for mitigation to prevent similar attacks in the future. In this paper, we describe our efforts in developing a forensic traceback tool for poison attacks on deep neural networks. We propose a novel iterative clustering and pruning solution that trims "innocent" training samples, until all that remains is the set of poisoned data responsible for the attack. Our method clusters training samples based on their impact on model parameters, then uses an efficient data unlearning method to prune innocent clusters. We empirically demonstrate the efficacy of our system on three types of dirty-label (backdoor) poison attacks and three types of clean-label poison attacks, across domains of computer vision and malware classification. Our system achieves over 98.4% precision and 96.8% recall across all attacks. We also show that our system is robust against four anti-forensics measures specifically designed to attack it.
Blacklight: Defending Black-Box Adversarial Attacks on Deep Neural Networks
Jun 24, 2020

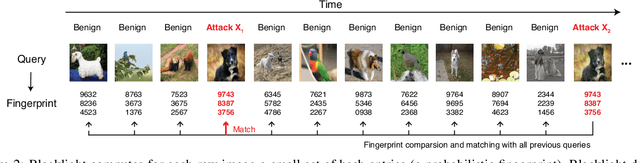

The vulnerability of deep neural networks (DNNs) to adversarial examples is well documented. Under the strong white-box threat model, where attackers have full access to DNN internals, recent work has produced continual advancements in defenses, often followed by more powerful attacks that break them. Meanwhile, research on the more realistic black-box threat model has focused almost entirely on reducing the query-cost of attacks, making them increasingly practical for ML models already deployed today. This paper proposes and evaluates Blacklight, a new defense against black-box adversarial attacks. Blacklight targets a key property of black-box attacks: to compute adversarial examples, they produce sequences of highly similar images while trying to minimize the distance from some initial benign input. To detect an attack, Blacklight computes for each query image a compact set of one-way hash values that form a probabilistic fingerprint. Variants of an image produce nearly identical fingerprints, and fingerprint generation is robust against manipulation. We evaluate Blacklight on 5 state-of-the-art black-box attacks, across a variety of models and classification tasks. While the most efficient attacks take thousands or tens of thousands of queries to complete, Blacklight identifies them all, often after only a handful of queries. Blacklight is also robust against several powerful countermeasures, including an optimal black-box attack that approximates white-box attacks in efficiency. Finally, Blacklight significantly outperforms the only known alternative in both detection coverage of attack queries and resistance against persistent attackers.
Fawkes: Protecting Personal Privacy against Unauthorized Deep Learning Models
Feb 19, 2020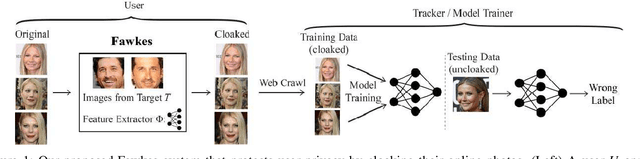

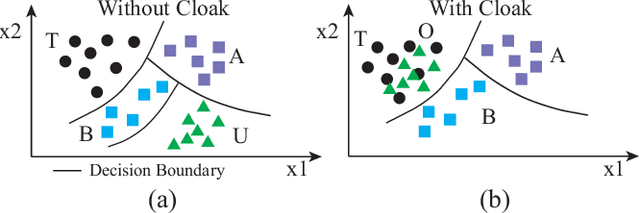
Today's proliferation of powerful facial recognition models poses a real threat to personal privacy. As Clearview.ai demonstrated, anyone can canvas the Internet for data, and train highly accurate facial recognition models of us without our knowledge. We need tools to protect ourselves from unauthorized facial recognition systems and their numerous potential misuses. Unfortunately, work in related areas are limited in practicality and effectiveness. In this paper, we propose Fawkes, a system that allow individuals to inoculate themselves against unauthorized facial recognition models. Fawkes achieves this by helping users adding imperceptible pixel-level changes (we call them "cloaks") to their own photos before publishing them online. When collected by a third-party "tracker" and used to train facial recognition models, these "cloaked" images produce functional models that consistently misidentify the user. We experimentally prove that Fawkes provides 95+% protection against user recognition regardless of how trackers train their models. Even when clean, uncloaked images are "leaked" to the tracker and used for training, Fawkes can still maintain a 80+% protection success rate. In fact, we perform real experiments against today's state-of-the-art facial recognition services and achieve 100% success. Finally, we show that Fawkes is robust against a variety of countermeasures that try to detect or disrupt cloaks.
Gotta Catch 'Em All: Using Concealed Trapdoors to Detect Adversarial Attacks on Neural Networks
Apr 18, 2019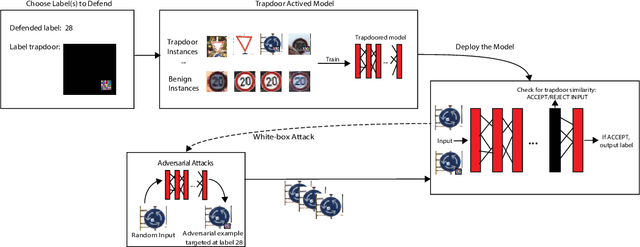
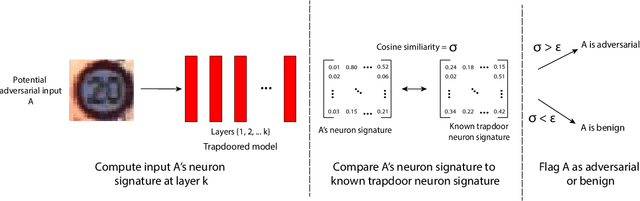
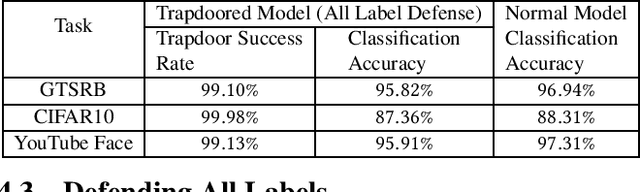
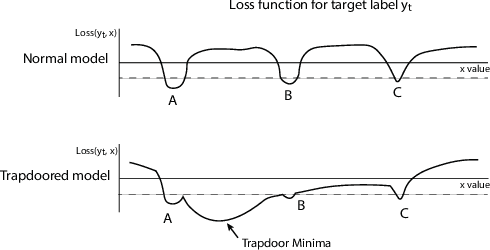
Deep neural networks are vulnerable to adversarial attacks. Numerous efforts have focused on defenses that either try to patch `holes' in trained models or try to make it difficult or costly to compute adversarial examples exploiting these holes. In our work, we explore a counter-intuitive approach of constructing "adversarial trapdoors. Unlike prior works that try to patch or disguise vulnerable points in the manifold, we intentionally inject `trapdoors,' artificial weaknesses in the manifold that attract optimized perturbation into certain pre-embedded local optima. As a result, the adversarial generation functions naturally gravitate towards our trapdoors, producing adversarial examples that the model owner can recognize through a known neuron activation signature. In this paper, we introduce trapdoors and describe an implementation of trapdoors using similar strategies to backdoor/Trojan attacks. We show that by proactively injecting trapdoors into the models (and extracting their neuron activation signature), we can detect adversarial examples generated by the state of the art attacks (Projected Gradient Descent, Optimization based CW, and Elastic Net) with high detection success rate and negligible impact on normal inputs. These results also generalize across multiple classification domains (image recognition, face recognition and traffic sign recognition). We explore different properties of trapdoors, and discuss potential countermeasures (adaptive attacks) and mitigations.