 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent and Unforgeable Watermarks for Deep Neural Networks
Oct 02, 2019
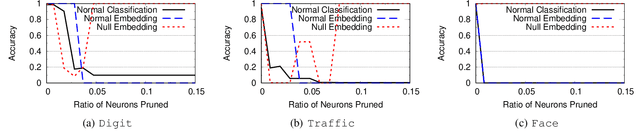
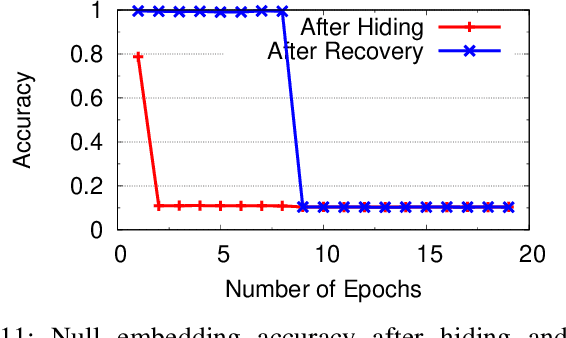
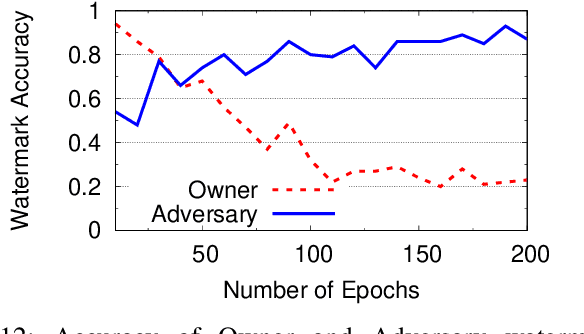
As deep learning classifiers continue to mature, model providers with sufficient data and computation resources are exploring approaches to monetize the development of increasingly powerful models. Licensing models is a promising approach, but requires a robust tool for owners to claim ownership of models, i.e. a watermark. Unfortunately, current watermarks are all vulnerable to piracy attacks, where attackers embed forged watermarks into a model to dispute ownership. We believe properties of persistence and piracy resistance are critical to watermarks, but are fundamentally at odds with the current way models are trained and tuned. In this work, we propose two new training techniques (out-of-bound values and null-embedding) that provide persistence and limit the training of certain inputs into trained models. We then introduce "wonder filters", a new primitive that embeds a persistent bit-sequence into a model, but only at initial training time. Wonder filters enable model owners to embed a bit-sequence generated from their private keys into a model at training time. Attackers cannot remove wonder filters via tuning, and cannot add their own filters to pretrained models. We provide analytical proofs of key properties, and experimentally validate them over a variety of tasks and models. Finally, we explore a number of adaptive counter-measures, and show our watermark remains robust.
Gotta Catch 'Em All: Using Concealed Trapdoors to Detect Adversarial Attacks on Neural Networks
Apr 18, 2019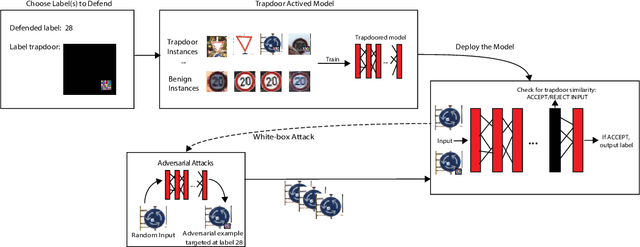
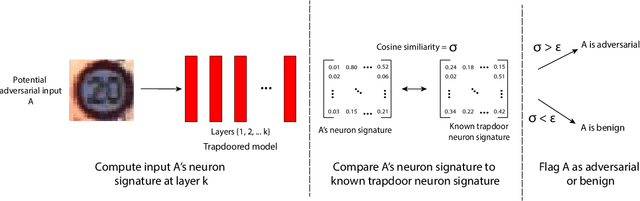
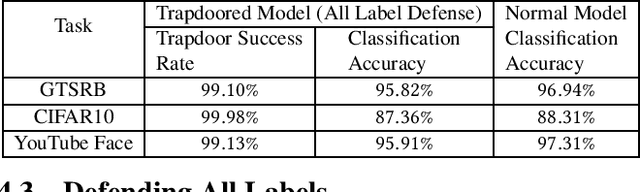
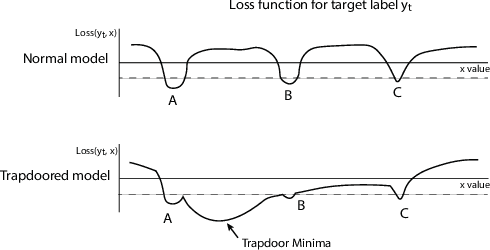
Deep neural networks are vulnerable to adversarial attacks. Numerous efforts have focused on defenses that either try to patch `holes' in trained models or try to make it difficult or costly to compute adversarial examples exploiting these holes. In our work, we explore a counter-intuitive approach of constructing "adversarial trapdoors. Unlike prior works that try to patch or disguise vulnerable points in the manifold, we intentionally inject `trapdoors,' artificial weaknesses in the manifold that attract optimized perturbation into certain pre-embedded local optima. As a result, the adversarial generation functions naturally gravitate towards our trapdoors, producing adversarial examples that the model owner can recognize through a known neuron activation signature. In this paper, we introduce trapdoors and describe an implementation of trapdoors using similar strategies to backdoor/Trojan attacks. We show that by proactively injecting trapdoors into the models (and extracting their neuron activation signature), we can detect adversarial examples generated by the state of the art attacks (Projected Gradient Descent, Optimization based CW, and Elastic Net) with high detection success rate and negligible impact on normal inputs. These results also generalize across multiple classification domains (image recognition, face recognition and traffic sign recognition). We explore different properties of trapdoors, and discuss potential countermeasures (adaptive attacks) and mitigations.