 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent and Unforgeable Watermarks for Deep Neural Networks
Paper and Code
Oct 02, 2019
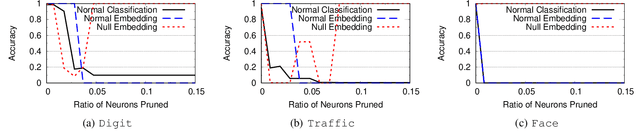
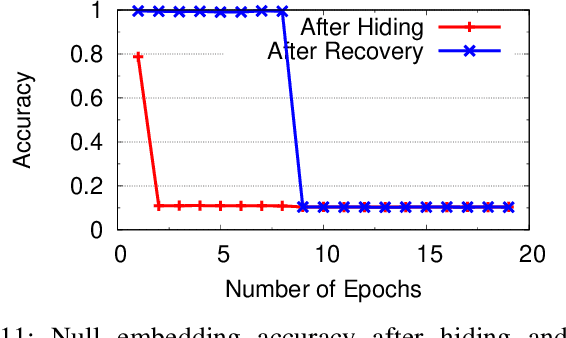
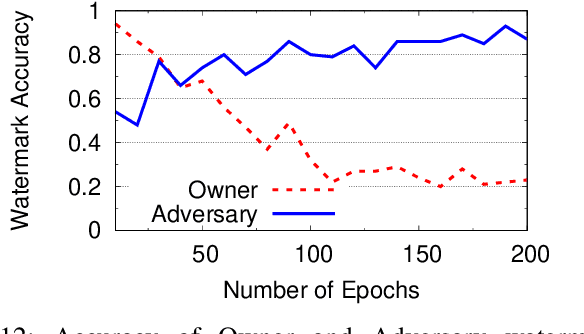
As deep learning classifiers continue to mature, model providers with sufficient data and computation resources are exploring approaches to monetize the development of increasingly powerful models. Licensing models is a promising approach, but requires a robust tool for owners to claim ownership of models, i.e. a watermark. Unfortunately, current watermarks are all vulnerable to piracy attacks, where attackers embed forged watermarks into a model to dispute ownership. We believe properties of persistence and piracy resistance are critical to watermarks, but are fundamentally at odds with the current way models are trained and tuned. In this work, we propose two new training techniques (out-of-bound values and null-embedding) that provide persistence and limit the training of certain inputs into trained models. We then introduce "wonder filters", a new primitive that embeds a persistent bit-sequence into a model, but only at initial training time. Wonder filters enable model owners to embed a bit-sequence generated from their private keys into a model at training time. Attackers cannot remove wonder filters via tuning, and cannot add their own filters to pretrained models. We provide analytical proofs of key properties, and experimentally validate them over a variety of tasks and models. Finally, we explore a number of adaptive counter-measures, and show our watermark remains robust.