 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisrupting Style Mimicry Attacks on Video Imagery
May 11, 2024



Generative AI models are often used to perform mimicry attacks, where a pretrained model is fine-tuned on a small sample of images to learn to mimic a specific artist of interest. While researchers have introduced multiple anti-mimicry protection tools (Mist, Glaze, Anti-Dreambooth), recent evidence points to a growing trend of mimicry models using videos as sources of training data. This paper presents our experiences exploring techniques to disrupt style mimicry on video imagery. We first validate that mimicry attacks can succeed by training on individual frames extracted from videos. We show that while anti-mimicry tools can offer protection when applied to individual frames, this approach is vulnerable to an adaptive countermeasure that removes protection by exploiting randomness in optimization results of consecutive (nearly-identical) frames. We develop a new, tool-agnostic framework that segments videos into short scenes based on frame-level similarity, and use a per-scene optimization baseline to remove inter-frame randomization while reducing computational cost. We show via both image level metrics and an end-to-end user study that the resulting protection restores protection against mimicry (including the countermeasure). Finally, we develop another adaptive countermeasure and find that it falls short against our framework.
Organic or Diffused: Can We Distinguish Human Art from AI-generated Images?
Feb 06, 2024
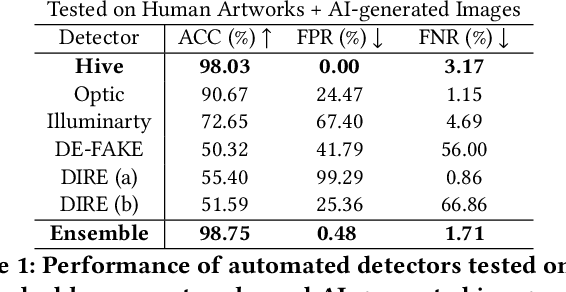
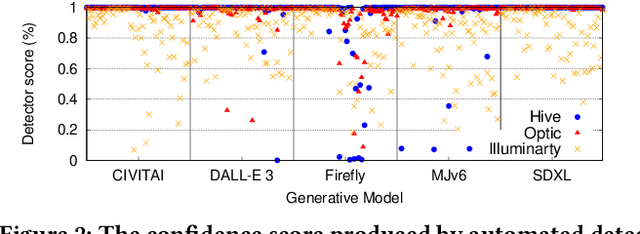
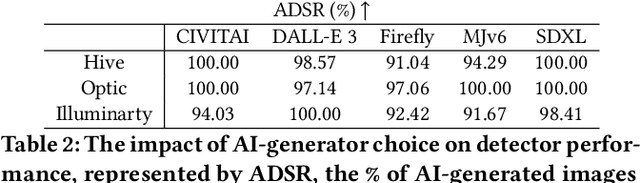
The advent of generative AI images has completely disrupted the art world. Distinguishing AI generated images from human art is a challenging problem whose impact is growing over time. A failure to address this problem allows bad actors to defraud individuals paying a premium for human art and companies whose stated policies forbid AI imagery. It is also critical for content owners to establish copyright, and for model trainers interested in curating training data in order to avoid potential model collapse. There are several different approaches to distinguishing human art from AI images, including classifiers trained by supervised learning, research tools targeting diffusion models, and identification by professional artists using their knowledge of artistic techniques. In this paper, we seek to understand how well these approaches can perform against today's modern generative models in both benign and adversarial settings. We curate real human art across 7 styles, generate matching images from 5 generative models, and apply 8 detectors (5 automated detectors and 3 different human groups including 180 crowdworkers, 4000+ professional artists, and 13 expert artists experienced at detecting AI). Both Hive and expert artists do very well, but make mistakes in different ways (Hive is weaker against adversarial perturbations while Expert artists produce higher false positives). We believe these weaknesses will remain as models continue to evolve, and use our data to demonstrate why a combined team of human and automated detectors provides the best combination of accuracy and robustness.
Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
Oct 20, 2023Data poisoning attacks manipulate training data to introduce unexpected behaviors into machine learning models at training time. For text-to-image generative models with massive training datasets, current understanding of poisoning attacks suggests that a successful attack would require injecting millions of poison samples into their training pipeline. In this paper, we show that poisoning attacks can be successful on generative models. We observe that training data per concept can be quite limited in these models, making them vulnerable to prompt-specific poisoning attacks, which target a model's ability to respond to individual prompts. We introduce Nightshade, an optimized prompt-specific poisoning attack where poison samples look visually identical to benign images with matching text prompts. Nightshade poison samples are also optimized for potency and can corrupt an Stable Diffusion SDXL prompt in <100 poison samples. Nightshade poison effects "bleed through" to related concepts, and multiple attacks can composed together in a single prompt. Surprisingly, we show that a moderate number of Nightshade attacks can destabilize general features in a text-to-image generative model, effectively disabling its ability to generate meaningful images. Finally, we propose the use of Nightshade` and similar tools as a last defense for content creators against web scrapers that ignore opt-out/do-not-crawl directives, and discuss possible implications for model trainers and content creators.
Natural Backdoor Datasets
Jun 21, 2022

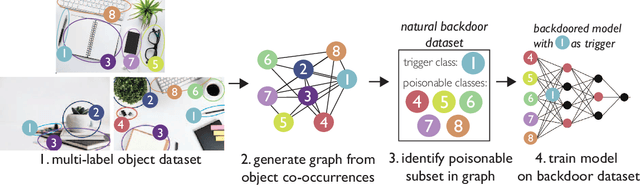
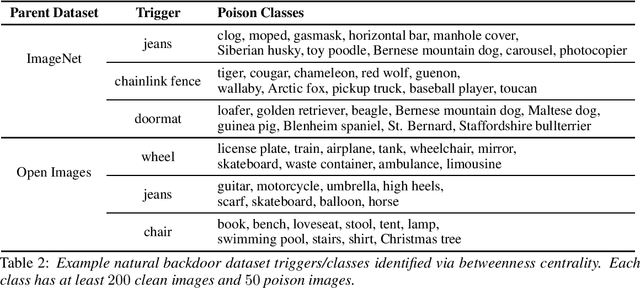
Extensive literature on backdoor poison attacks has studied attacks and defenses for backdoors using "digital trigger patterns." In contrast, "physical backdoors" use physical objects as triggers, have only recently been identified, and are qualitatively different enough to resist all defenses targeting digital trigger backdoors. Research on physical backdoors is limited by access to large datasets containing real images of physical objects co-located with targets of classification. Building these datasets is time- and labor-intensive. This works seeks to address the challenge of accessibility for research on physical backdoor attacks. We hypothesize that there may be naturally occurring physically co-located objects already present in popular datasets such as ImageNet. Once identified, a careful relabeling of these data can transform them into training samples for physical backdoor attacks. We propose a method to scalably identify these subsets of potential triggers in existing datasets, along with the specific classes they can poison. We call these naturally occurring trigger-class subsets natural backdoor datasets. Our techniques successfully identify natural backdoors in widely-available datasets, and produce models behaviorally equivalent to those trained on manually curated datasets. We release our code to allow the research community to create their own datasets for research on physical backdoor attacks.
Assessing Privacy Risks from Feature Vector Reconstruction Attacks
Feb 11, 2022



In deep neural networks for facial recognition, feature vectors are numerical representations that capture the unique features of a given face. While it is known that a version of the original face can be recovered via "feature reconstruction," we lack an understanding of the end-to-end privacy risks produced by these attacks. In this work, we address this shortcoming by developing metrics that meaningfully capture the threat of reconstructed face images. Using end-to-end experiments and user studies, we show that reconstructed face images enable re-identification by both commercial facial recognition systems and humans, at a rate that is at worst, a factor of four times higher than randomized baselines. Our results confirm that feature vectors should be recognized as Personal Identifiable Information (PII) in order to protect user privacy.
Backdoor Attacks on Facial Recognition in the Physical World
Jun 25, 2020
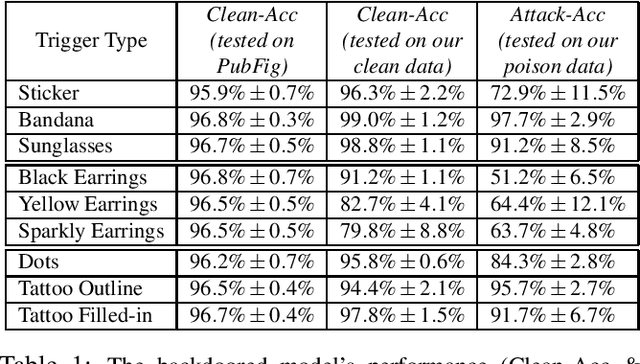

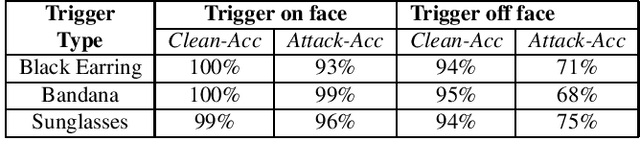
Backdoor attacks embed hidden malicious behaviors inside deep neural networks (DNNs) that are only activated when a specific "trigger" is present on some input to the model. A variety of these attacks have been successfully proposed and evaluated, generally using digitally generated patterns or images as triggers. Despite significant prior work on the topic, a key question remains unanswered: "can backdoor attacks be physically realized in the real world, and what limitations do attackers face in executing them?" In this paper, we present results of a detailed study on DNN backdoor attacks in the physical world, specifically focused on the task of facial recognition. We take 3205 photographs of 10 volunteers in a variety of settings and backgrounds and train a facial recognition model using transfer learning from VGGFace. We evaluate the effectiveness of 9 accessories as potential triggers, and analyze impact from external factors such as lighting and image quality. First, we find that triggers vary significantly in efficacy and a key factor is that facial recognition models are heavily tuned to features on the face and less so to features around the periphery. Second, the efficacy of most trigger objects is. negatively impacted by lower image quality but unaffected by lighting. Third, most triggers suffer from false positives, where non-trigger objects unintentionally activate the backdoor. Finally, we evaluate 4 backdoor defenses against physical backdoors. We show that they all perform poorly because physical triggers break key assumptions they made based on triggers in the digital domain. Our key takeaway is that implementing physical backdoors is much more challenging than described in literature for both attackers and defenders and much more work is necessary to understand how backdoors work in the real world.