 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisually Grounded Commonsense Knowledge Acquisition
Paper and Code
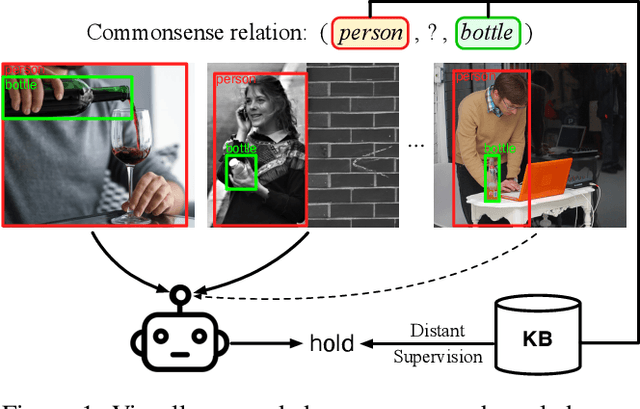
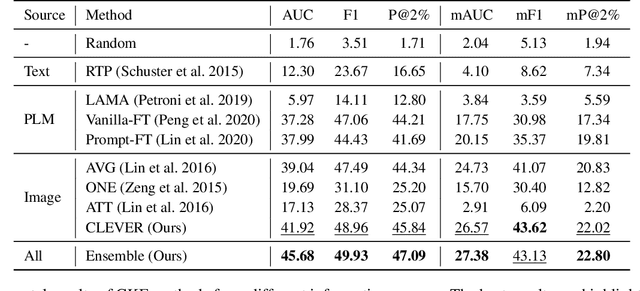
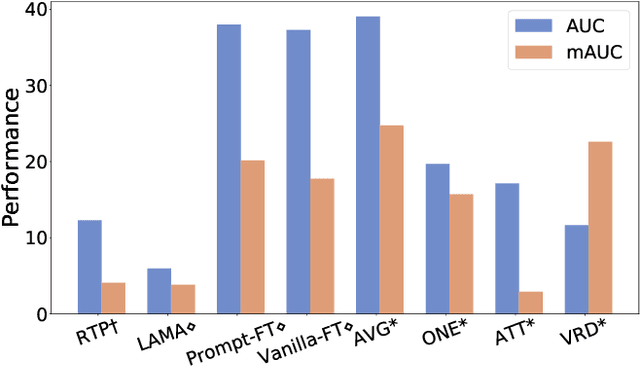
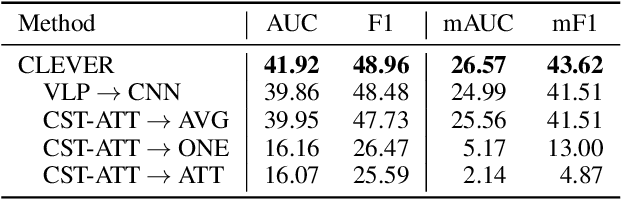
Large-scale commonsense knowledge bases empower a broad range of AI applications, where the automatic extraction of commonsense knowledge (CKE) is a fundamental and challenging problem. CKE from text is known for suffering from the inherent sparsity and reporting bias of commonsense in text. Visual perception, on the other hand, contains rich commonsense knowledge about real-world entities, e.g., (person, can_hold, bottle), which can serve as promising sources for acquiring grounded commonsense knowledge. In this work, we present CLEVER, which formulates CKE as a distantly supervised multi-instance learning problem, where models learn to summarize commonsense relations from a bag of images about an entity pair without any human annotation on image instances. To address the problem, CLEVER leverages vision-language pre-training models for deep understanding of each image in the bag, and selects informative instances from the bag to summarize commonsense entity relations via a novel contrastive attention mechanism. Comprehensive experimental results in held-out and human evaluation show that CLEVER can extract commonsense knowledge in promising quality, outperforming pre-trained language model-based methods by 3.9 AUC and 6.4 mAUC points. The predicted commonsense scores show strong correlation with human judgment with a 0.78 Spearman coefficient. Moreover, the extracted commonsense can also be grounded into images with reasonable interpretability. The data and codes can be obtained at https://github.com/thunlp/CLEVER.