 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing the Delta: What Do Models Actually Learn from Preference Pairs?
Apr 09, 2026Preference optimization methods such as DPO and KTO are widely used for aligning language models, yet little is understood about what properties of preference data drive downstream reasoning gains. We ask: what aspects of a preference pair improve a reasoning model's performance on general reasoning tasks? We investigate two distinct notions of quality delta in preference data: generator-level delta, arising from the differences in capability between models that generate chosen and rejected reasoning traces, and sample-level delta, arising from differences in judged quality differences within an individual preference pair. To study generator-level delta, we vary the generator's scale and model family, and to study sample-level delta, we employ an LLM-as-a-judge to rate the quality of generated traces along multiple reasoning-quality dimensions. We find that increasing generator-level delta steadily improves performance on out-of-domain reasoning tasks and filtering data by sample-level delta can enable more data-efficient training. Our results suggest a twofold recipe for improving reasoning performance through preference optimization: maximize generator-level delta when constructing preference pairs and exploit sample-level delta to select the most informative training examples.
Can Memory-Augmented Language Models Generalize on Reasoning-in-a-Haystack Tasks?
Mar 10, 2025Large language models often expose their brittleness in reasoning tasks, especially while executing long chains of reasoning over context. We propose MemReasoner, a new and simple memory-augmented LLM architecture, in which the memory learns the relative order of facts in context, and enables hopping over them, while the decoder selectively attends to the memory. MemReasoner is trained end-to-end, with optional supporting fact supervision of varying degrees. We train MemReasoner, along with existing memory-augmented transformer models and a state-space model, on two distinct synthetic multi-hop reasoning tasks. Experiments performed under a variety of challenging scenarios, including the presence of long distractor text or target answer changes in test set, show strong generalization of MemReasoner on both single- and two-hop tasks. This generalization of MemReasoner is achieved using none-to-weak supporting fact supervision (using none and 1\% of supporting facts for one- and two-hop tasks, respectively). In contrast, baseline models overall struggle to generalize and benefit far less from using full supporting fact supervision. The results highlight the importance of explicit memory mechanisms, combined with additional weak supervision, for improving large language model's context processing ability toward reasoning tasks.
Adapting to Evolving Adversaries with Regularized Continual Robust Training
Feb 06, 2025



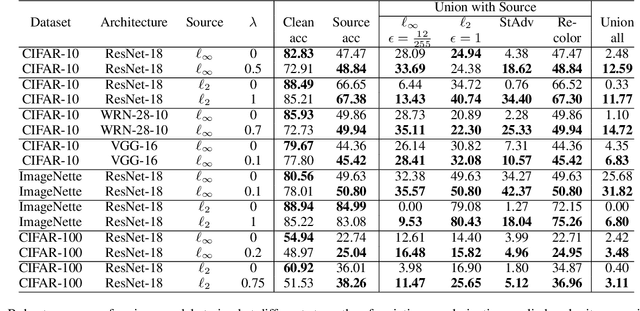
Robust training methods typically defend against specific attack types, such as Lp attacks with fixed budgets, and rarely account for the fact that defenders may encounter new attacks over time. A natural solution is to adapt the defended model to new adversaries as they arise via fine-tuning, a method which we call continual robust training (CRT). However, when implemented naively, fine-tuning on new attacks degrades robustness on previous attacks. This raises the question: how can we improve the initial training and fine-tuning of the model to simultaneously achieve robustness against previous and new attacks? We present theoretical results which show that the gap in a model's robustness against different attacks is bounded by how far each attack perturbs a sample in the model's logit space, suggesting that regularizing with respect to this logit space distance can help maintain robustness against previous attacks. Extensive experiments on 3 datasets (CIFAR-10, CIFAR-100, and ImageNette) and over 100 attack combinations demonstrate that the proposed regularization improves robust accuracy with little overhead in training time. Our findings and open-source code lay the groundwork for the deployment of models robust to evolving attacks.
Position Paper: Beyond Robustness Against Single Attack Types
May 02, 2024Current research on defending against adversarial examples focuses primarily on achieving robustness against a single attack type such as $\ell_2$ or $\ell_{\infty}$-bounded attacks. However, the space of possible perturbations is much larger and currently cannot be modeled by a single attack type. The discrepancy between the focus of current defenses and the space of attacks of interest calls to question the practicality of existing defenses and the reliability of their evaluation. In this position paper, we argue that the research community should look beyond single attack robustness, and we draw attention to three potential directions involving robustness against multiple attacks: simultaneous multiattack robustness, unforeseen attack robustness, and a newly defined problem setting which we call continual adaptive robustness. We provide a unified framework which rigorously defines these problem settings, synthesize existing research in these fields, and outline open directions. We hope that our position paper inspires more research in simultaneous multiattack, unforeseen attack, and continual adaptive robustness.
Larimar: Large Language Models with Episodic Memory Control
Mar 18, 2024Efficient and accurate updating of knowledge stored in Large Language Models (LLMs) is one of the most pressing research challenges today. This paper presents Larimar - a novel, brain-inspired architecture for enhancing LLMs with a distributed episodic memory. Larimar's memory allows for dynamic, one-shot updates of knowledge without the need for computationally expensive re-training or fine-tuning. Experimental results on multiple fact editing benchmarks demonstrate that Larimar attains accuracy comparable to most competitive baselines, even in the challenging sequential editing setup, but also excels in speed - yielding speed-ups of 4-10x depending on the base LLM - as well as flexibility due to the proposed architecture being simple, LLM-agnostic, and hence general. We further provide mechanisms for selective fact forgetting and input context length generalization with Larimar and show their effectiveness.
PatchCURE: Improving Certifiable Robustness, Model Utility, and Computation Efficiency of Adversarial Patch Defenses
Oct 19, 2023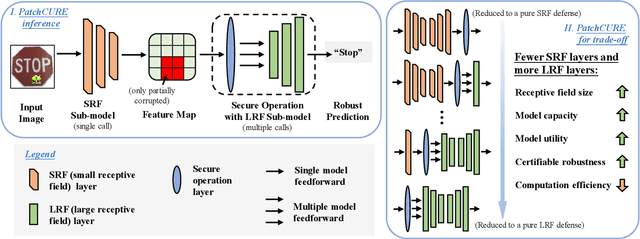
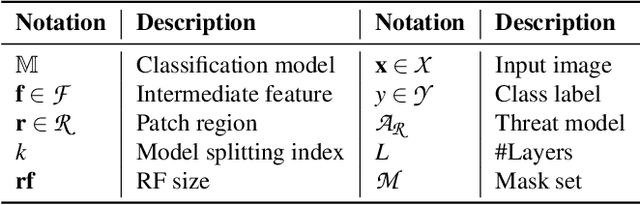
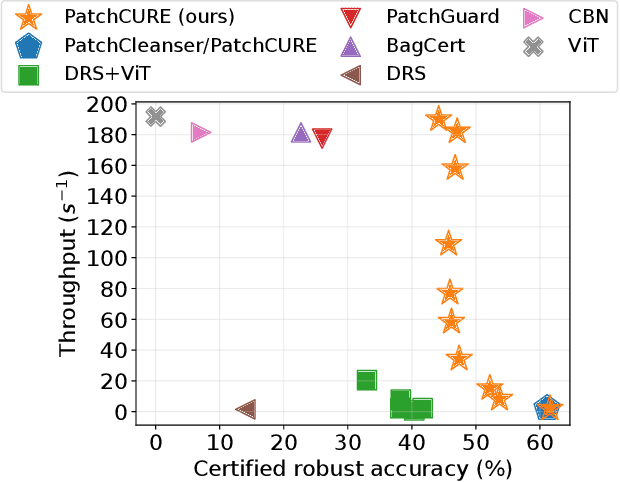

State-of-the-art defenses against adversarial patch attacks can now achieve strong certifiable robustness with a marginal drop in model utility. However, this impressive performance typically comes at the cost of 10-100x more inference-time computation compared to undefended models -- the research community has witnessed an intense three-way trade-off between certifiable robustness, model utility, and computation efficiency. In this paper, we propose a defense framework named PatchCURE to approach this trade-off problem. PatchCURE provides sufficient "knobs" for tuning defense performance and allows us to build a family of defenses: the most robust PatchCURE instance can match the performance of any existing state-of-the-art defense (without efficiency considerations); the most efficient PatchCURE instance has similar inference efficiency as undefended models. Notably, PatchCURE achieves state-of-the-art robustness and utility performance across all different efficiency levels, e.g., 16-23% absolute clean accuracy and certified robust accuracy advantages over prior defenses when requiring computation efficiency to be close to undefended models. The family of PatchCURE defenses enables us to flexibly choose appropriate defenses to satisfy given computation and/or utility constraints in practice.
MultiRobustBench: Benchmarking Robustness Against Multiple Attacks
Feb 21, 2023



The bulk of existing research in defending against adversarial examples focuses on defending against a single (typically bounded Lp-norm) attack, but for a practical setting, machine learning (ML) models should be robust to a wide variety of attacks. In this paper, we present the first unified framework for considering multiple attacks against ML models. Our framework is able to model different levels of learner's knowledge about the test-time adversary, allowing us to model robustness against unforeseen attacks and robustness against unions of attacks. Using our framework, we present the first leaderboard, MultiRobustBench, for benchmarking multiattack evaluation which captures performance across attack types and attack strengths. We evaluate the performance of 16 defended models for robustness against a set of 9 different attack types, including Lp-based threat models, spatial transformations, and color changes, at 20 different attack strengths (180 attacks total). Additionally, we analyze the state of current defenses against multiple attacks. Our analysis shows that while existing defenses have made progress in terms of average robustness across the set of attacks used, robustness against the worst-case attack is still a big open problem as all existing models perform worse than random guessing.
Characterizing the Optimal 0-1 Loss for Multi-class Classification with a Test-time Attacker
Feb 21, 2023



Finding classifiers robust to adversarial examples is critical for their safe deployment. Determining the robustness of the best possible classifier under a given threat model for a given data distribution and comparing it to that achieved by state-of-the-art training methods is thus an important diagnostic tool. In this paper, we find achievable information-theoretic lower bounds on loss in the presence of a test-time attacker for multi-class classifiers on any discrete dataset. We provide a general framework for finding the optimal 0-1 loss that revolves around the construction of a conflict hypergraph from the data and adversarial constraints. We further define other variants of the attacker-classifier game that determine the range of the optimal loss more efficiently than the full-fledged hypergraph construction. Our evaluation shows, for the first time, an analysis of the gap to optimal robustness for classifiers in the multi-class setting on benchmark datasets.
Formulating Robustness Against Unforeseen Attacks
Apr 28, 2022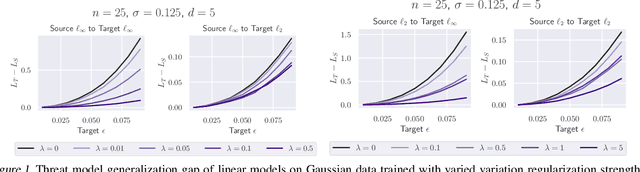
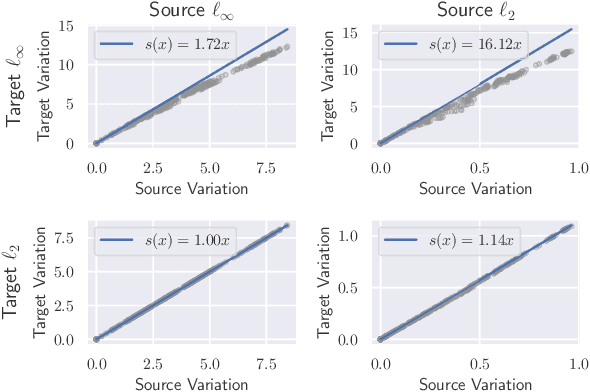

Existing defenses against adversarial examples such as adversarial training typically assume that the adversary will conform to a specific or known threat model, such as $\ell_p$ perturbations within a fixed budget. In this paper, we focus on the scenario where there is a mismatch in the threat model assumed by the defense during training, and the actual capabilities of the adversary at test time. We ask the question: if the learner trains against a specific "source" threat model, when can we expect robustness to generalize to a stronger unknown "target" threat model during test-time? Our key contribution is to formally define the problem of learning and generalization with an unforeseen adversary, which helps us reason about the increase in adversarial risk from the conventional perspective of a known adversary. Applying our framework, we derive a generalization bound which relates the generalization gap between source and target threat models to variation of the feature extractor, which measures the expected maximum difference between extracted features across a given threat model. Based on our generalization bound, we propose adversarial training with variation regularization (AT-VR) which reduces variation of the feature extractor across the source threat model during training. We empirically demonstrate that AT-VR can lead to improved generalization to unforeseen attacks during test-time compared to standard adversarial training on Gaussian and image datasets.
Parameterizing Activation Functions for Adversarial Robustness
Oct 11, 2021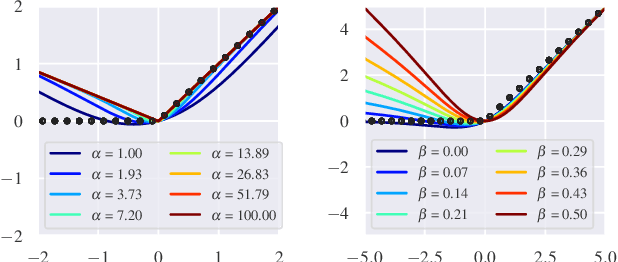

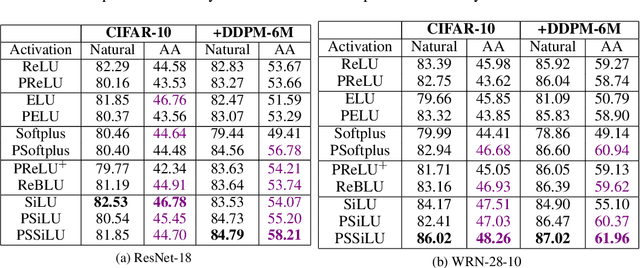
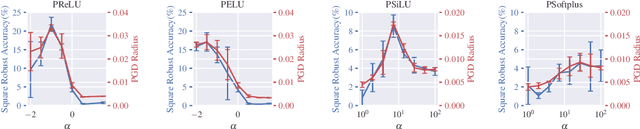
Deep neural networks are known to be vulnerable to adversarially perturbed inputs. A commonly used defense is adversarial training, whose performance is influenced by model capacity. While previous works have studied the impact of varying model width and depth on robustness, the impact of increasing capacity by using learnable parametric activation functions (PAFs) has not been studied. We study how using learnable PAFs can improve robustness in conjunction with adversarial training. We first ask the question: how should we incorporate parameters into activation functions to improve robustness? To address this, we analyze the direct impact of activation shape on robustness through PAFs and observe that activation shapes with positive outputs on negative inputs and with high finite curvature can increase robustness. We combine these properties to create a new PAF, which we call Parametric Shifted Sigmoidal Linear Unit (PSSiLU). We then combine PAFs (including PReLU, PSoftplus and PSSiLU) with adversarial training and analyze robust performance. We find that PAFs optimize towards activation shape properties found to directly affect robustness. Additionally, we find that while introducing only 1-2 learnable parameters into the network, smooth PAFs can significantly increase robustness over ReLU. For instance, when trained on CIFAR-10 with additional synthetic data, PSSiLU improves robust accuracy by 4.54% over ReLU on ResNet-18 and 2.69% over ReLU on WRN-28-10 in the $\ell_{\infty}$ threat model while adding only 2 additional parameters into the network architecture. The PSSiLU WRN-28-10 model achieves 61.96% AutoAttack accuracy, improving over the state-of-the-art robust accuracy on RobustBench (Croce et al., 2020).