 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting to Evolving Adversaries with Regularized Continual Robust Training
Feb 06, 2025



Robust training methods typically defend against specific attack types, such as Lp attacks with fixed budgets, and rarely account for the fact that defenders may encounter new attacks over time. A natural solution is to adapt the defended model to new adversaries as they arise via fine-tuning, a method which we call continual robust training (CRT). However, when implemented naively, fine-tuning on new attacks degrades robustness on previous attacks. This raises the question: how can we improve the initial training and fine-tuning of the model to simultaneously achieve robustness against previous and new attacks? We present theoretical results which show that the gap in a model's robustness against different attacks is bounded by how far each attack perturbs a sample in the model's logit space, suggesting that regularizing with respect to this logit space distance can help maintain robustness against previous attacks. Extensive experiments on 3 datasets (CIFAR-10, CIFAR-100, and ImageNette) and over 100 attack combinations demonstrate that the proposed regularization improves robust accuracy with little overhead in training time. Our findings and open-source code lay the groundwork for the deployment of models robust to evolving attacks.
Understanding Robust Learning through the Lens of Representation Similarities
Jun 20, 2022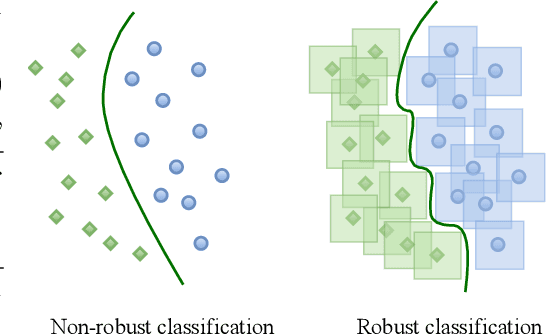
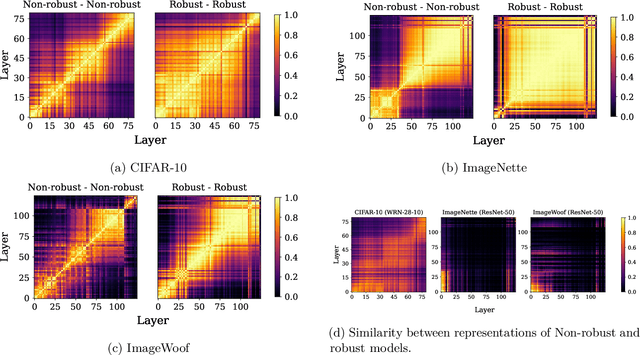
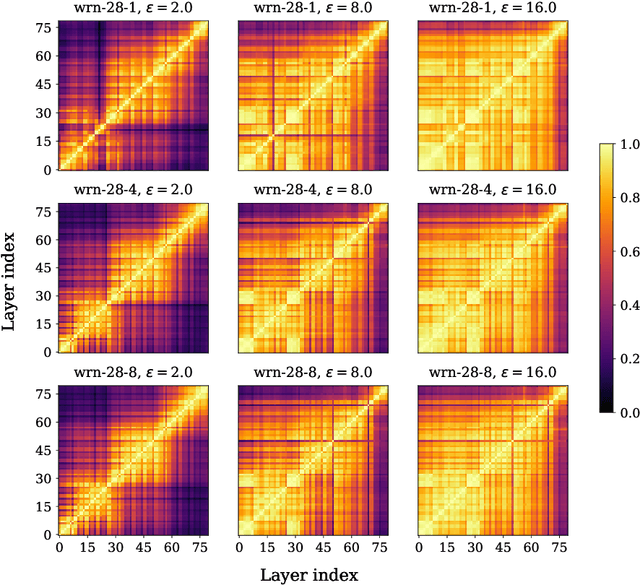
Representation learning, i.e. the generation of representations useful for downstream applications, is a task of fundamental importance that underlies much of the success of deep neural networks (DNNs). Recently, robustness to adversarial examples has emerged as a desirable property for DNNs, spurring the development of robust training methods that account for adversarial examples. In this paper, we aim to understand how the properties of representations learned by robust training differ from those obtained from standard, non-robust training. This is critical to diagnosing numerous salient pitfalls in robust networks, such as, degradation of performance on benign inputs, poor generalization of robustness, and increase in over-fitting. We utilize a powerful set of tools known as representation similarity metrics, across three vision datasets, to obtain layer-wise comparisons between robust and non-robust DNNs with different architectures, training procedures and adversarial constraints. Our experiments highlight hitherto unseen properties of robust representations that we posit underlie the behavioral differences of robust networks. We discover a lack of specialization in robust networks' representations along with a disappearance of `block structure'. We also find overfitting during robust training largely impacts deeper layers. These, along with other findings, suggest ways forward for the design and training of better robust networks.
"Hello, It's Me": Deep Learning-based Speech Synthesis Attacks in the Real World
Sep 20, 2021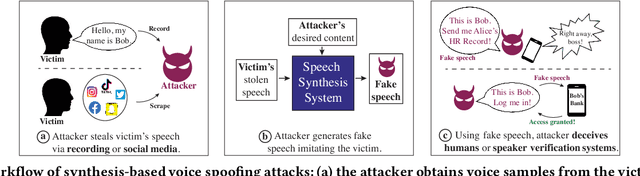
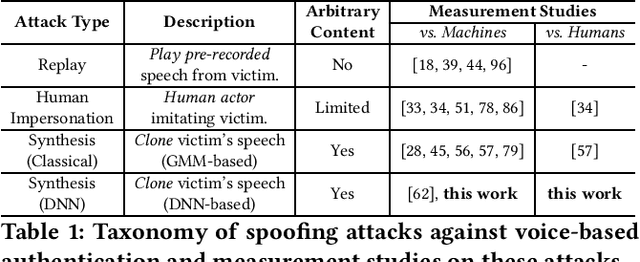

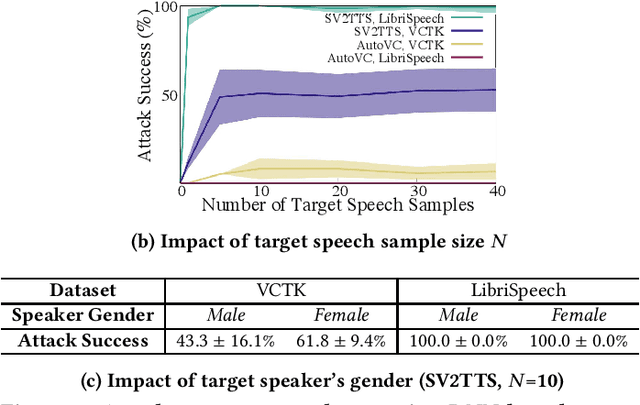
Advances in deep learning have introduced a new wave of voice synthesis tools, capable of producing audio that sounds as if spoken by a target speaker. If successful, such tools in the wrong hands will enable a range of powerful attacks against both humans and software systems (aka machines). This paper documents efforts and findings from a comprehensive experimental study on the impact of deep-learning based speech synthesis attacks on both human listeners and machines such as speaker recognition and voice-signin systems. We find that both humans and machines can be reliably fooled by synthetic speech and that existing defenses against synthesized speech fall short. These findings highlight the need to raise awareness and develop new protections against synthetic speech for both humans and machines.