 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCECT-Mamba: a Hierarchical Contrast-enhanced-aware Model for Pancreatic Tumor Subtyping from Multi-phase CECT
Sep 16, 2025Contrast-enhanced computed tomography (CECT) is the primary imaging technique that provides valuable spatial-temporal information about lesions, enabling the accurate diagnosis and subclassification of pancreatic tumors. However, the high heterogeneity and variability of pancreatic tumors still pose substantial challenges for precise subtyping diagnosis. Previous methods fail to effectively explore the contextual information across multiple CECT phases commonly used in radiologists' diagnostic workflows, thereby limiting their performance. In this paper, we introduce, for the first time, an automatic way to combine the multi-phase CECT data to discriminate between pancreatic tumor subtypes, among which the key is using Mamba with promising learnability and simplicity to encourage both temporal and spatial modeling from multi-phase CECT. Specifically, we propose a dual hierarchical contrast-enhanced-aware Mamba module incorporating two novel spatial and temporal sampling sequences to explore intra and inter-phase contrast variations of lesions. A similarity-guided refinement module is also imposed into the temporal scanning modeling to emphasize the learning on local tumor regions with more obvious temporal variations. Moreover, we design the space complementary integrator and multi-granularity fusion module to encode and aggregate the semantics across different scales, achieving more efficient learning for subtyping pancreatic tumors. The experimental results on an in-house dataset of 270 clinical cases achieve an accuracy of 97.4% and an AUC of 98.6% in distinguishing between pancreatic ductal adenocarcinoma (PDAC) and pancreatic neuroendocrine tumors (PNETs), demonstrating its potential as a more accurate and efficient tool.
RIS-Empowered Integrated Location Sensing and Communication with Superimposed Pilots
Apr 05, 2025In addition to enhancing wireless communication coverage quality, reconfigurable intelligent surface (RIS) technique can also assist in positioning. In this work, we consider RIS-assisted superimposed pilot and data transmission without the assumption availability of prior channel state information and position information of mobile user equipments (UEs). To tackle this challenge, we design a frame structure of transmission protocol composed of several location coherence intervals, each with pure-pilot and data-pilot transmission durations. The former is used to estimate UE locations, while the latter is time-slotted, duration of which does not exceed the channel coherence time, where the data and pilot signals are transmitted simultaneously. We conduct the Fisher Information matrix (FIM) analysis and derive \text {Cram\'er-Rao bound} (CRB) for the position estimation error. The inverse fast Fourier transform (IFFT) is adopted to obtain the estimation results of UE positions, which are then exploited for channel estimation. Furthermore, we derive the closed-form lower bound of the ergodic achievable rate of superimposed pilot (SP) transmission, which is used to optimize the phase profile of the RIS to maximize the achievable sum rate using the genetic algorithm. Finally, numerical results validate the accuracy of the UE position estimation using the IFFT algorithm and the superiority of the proposed SP scheme by comparison with the regular pilot scheme.
Understanding Robust Learning through the Lens of Representation Similarities
Jun 20, 2022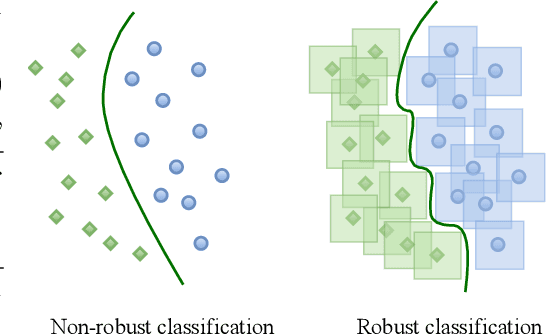
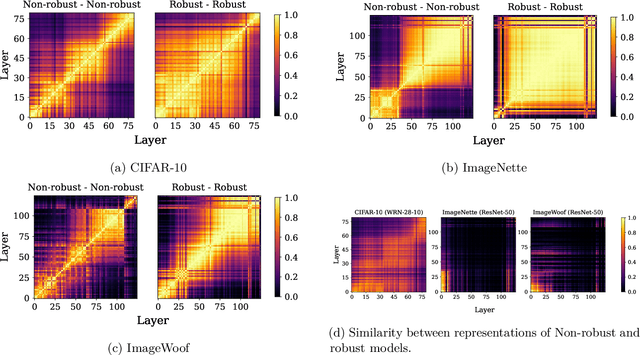
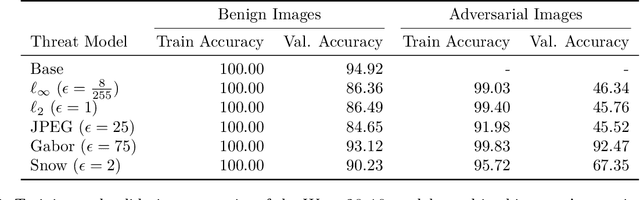
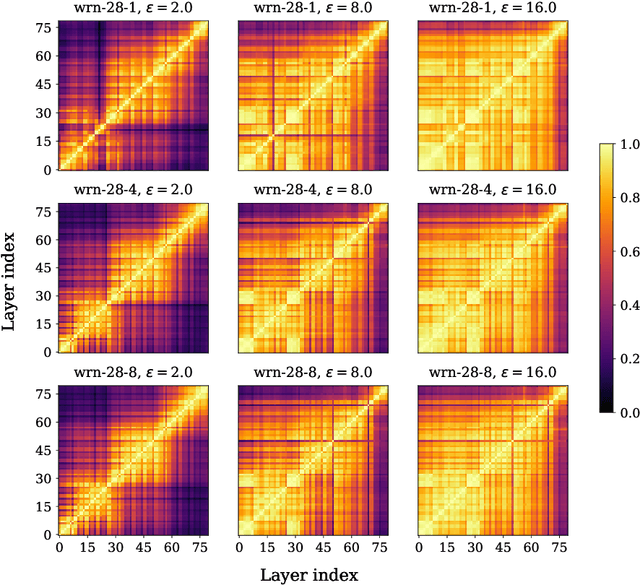
Representation learning, i.e. the generation of representations useful for downstream applications, is a task of fundamental importance that underlies much of the success of deep neural networks (DNNs). Recently, robustness to adversarial examples has emerged as a desirable property for DNNs, spurring the development of robust training methods that account for adversarial examples. In this paper, we aim to understand how the properties of representations learned by robust training differ from those obtained from standard, non-robust training. This is critical to diagnosing numerous salient pitfalls in robust networks, such as, degradation of performance on benign inputs, poor generalization of robustness, and increase in over-fitting. We utilize a powerful set of tools known as representation similarity metrics, across three vision datasets, to obtain layer-wise comparisons between robust and non-robust DNNs with different architectures, training procedures and adversarial constraints. Our experiments highlight hitherto unseen properties of robust representations that we posit underlie the behavioral differences of robust networks. We discover a lack of specialization in robust networks' representations along with a disappearance of `block structure'. We also find overfitting during robust training largely impacts deeper layers. These, along with other findings, suggest ways forward for the design and training of better robust networks.