 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Hello, It's Me": Deep Learning-based Speech Synthesis Attacks in the Real World
Paper and Code
Sep 20, 2021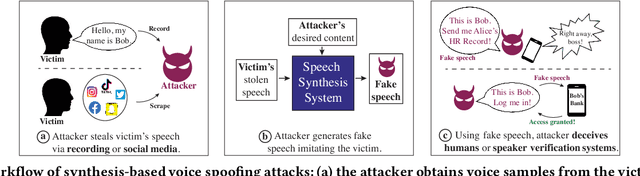
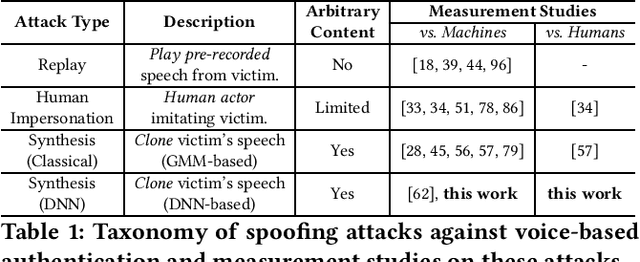

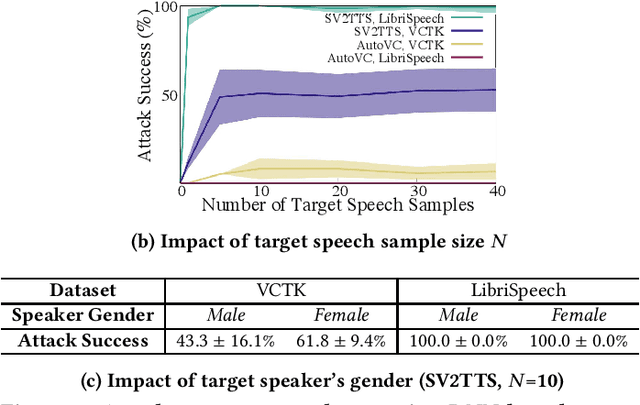
Advances in deep learning have introduced a new wave of voice synthesis tools, capable of producing audio that sounds as if spoken by a target speaker. If successful, such tools in the wrong hands will enable a range of powerful attacks against both humans and software systems (aka machines). This paper documents efforts and findings from a comprehensive experimental study on the impact of deep-learning based speech synthesis attacks on both human listeners and machines such as speaker recognition and voice-signin systems. We find that both humans and machines can be reliably fooled by synthetic speech and that existing defenses against synthesized speech fall short. These findings highlight the need to raise awareness and develop new protections against synthetic speech for both humans and machines.