 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterizing Activation Functions for Adversarial Robustness
Paper and Code
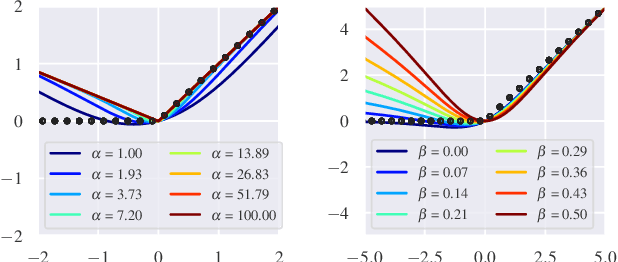

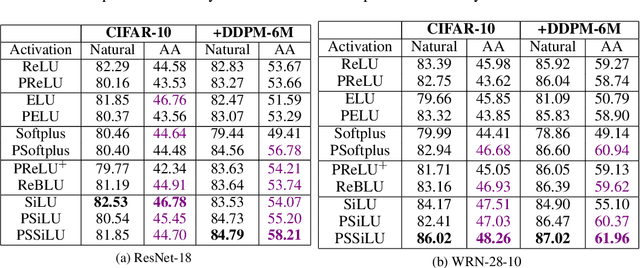
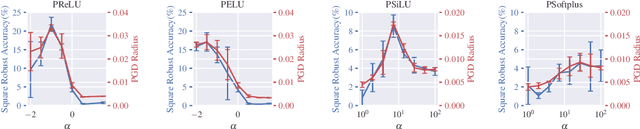
Deep neural networks are known to be vulnerable to adversarially perturbed inputs. A commonly used defense is adversarial training, whose performance is influenced by model capacity. While previous works have studied the impact of varying model width and depth on robustness, the impact of increasing capacity by using learnable parametric activation functions (PAFs) has not been studied. We study how using learnable PAFs can improve robustness in conjunction with adversarial training. We first ask the question: how should we incorporate parameters into activation functions to improve robustness? To address this, we analyze the direct impact of activation shape on robustness through PAFs and observe that activation shapes with positive outputs on negative inputs and with high finite curvature can increase robustness. We combine these properties to create a new PAF, which we call Parametric Shifted Sigmoidal Linear Unit (PSSiLU). We then combine PAFs (including PReLU, PSoftplus and PSSiLU) with adversarial training and analyze robust performance. We find that PAFs optimize towards activation shape properties found to directly affect robustness. Additionally, we find that while introducing only 1-2 learnable parameters into the network, smooth PAFs can significantly increase robustness over ReLU. For instance, when trained on CIFAR-10 with additional synthetic data, PSSiLU improves robust accuracy by 4.54% over ReLU on ResNet-18 and 2.69% over ReLU on WRN-28-10 in the $\ell_{\infty}$ threat model while adding only 2 additional parameters into the network architecture. The PSSiLU WRN-28-10 model achieves 61.96% AutoAttack accuracy, improving over the state-of-the-art robust accuracy on RobustBench (Croce et al., 2020).