 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Watermarking for Autoregressive Image Generation
Apr 13, 2026The proliferation of autoregressive (AR) image generators demands reliable detection and attribution of their outputs to mitigate misinformation, and to filter synthetic images from training data to prevent model collapse. To address this need, watermarking techniques, specifically designed for AR models, embed a subtle signal at generation time, enabling downstream verification through a corresponding watermark detector. In this work, we study these schemes and demonstrate their vulnerability to both watermark removal and forgery attacks. We assess existing attacks and further introduce three new attacks: (i) a vector-quantized regeneration removal attack, (ii) adversarial optimization-based attack, and (iii) a frequency injection attack. Our evaluation reveals that removal and forgery attacks can be effective with access to a single watermarked reference image and without access to original model parameters or watermarking secrets. Our findings indicate that existing watermarking schemes for AR image generation do not reliably support synthetic content detection for dataset filtering. Moreover, they enable Watermark Mimicry, whereby authentic images can be manipulated to imitate a generator's watermark and trigger false detection to prevent their inclusion in future model training.
Private PoEtry: Private In-Context Learning via Product of Experts
Feb 04, 2026In-context learning (ICL) enables Large Language Models (LLMs) to adapt to new tasks with only a small set of examples at inference time, thereby avoiding task-specific fine-tuning. However, in-context examples may contain privacy-sensitive information that should not be revealed through model outputs. Existing differential privacy (DP) approaches to ICL are either computationally expensive or rely on heuristics with limited effectiveness, including context oversampling, synthetic data generation, or unnecessary thresholding. We reformulate private ICL through the lens of a Product-of-Experts model. This gives a theoretically grounded framework, and the algorithm can be trivially parallelized. We evaluate our method across five datasets in text classification, math, and vision-language. We find that our method improves accuracy by more than 30 percentage points on average compared to prior DP-ICL methods, while maintaining strong privacy guarantees.
Uncertainty Quantification for Collaborative Object Detection Under Adversarial Attacks
Feb 04, 2025



Collaborative Object Detection (COD) and collaborative perception can integrate data or features from various entities, and improve object detection accuracy compared with individual perception. However, adversarial attacks pose a potential threat to the deep learning COD models, and introduce high output uncertainty. With unknown attack models, it becomes even more challenging to improve COD resiliency and quantify the output uncertainty for highly dynamic perception scenes such as autonomous vehicles. In this study, we propose the Trusted Uncertainty Quantification in Collaborative Perception framework (TUQCP). TUQCP leverages both adversarial training and uncertainty quantification techniques to enhance the adversarial robustness of existing COD models. More specifically, TUQCP first adds perturbations to the shared information of randomly selected agents during object detection collaboration by adversarial training. TUQCP then alleviates the impacts of adversarial attacks by providing output uncertainty estimation through learning-based module and uncertainty calibration through conformal prediction. Our framework works for early and intermediate collaboration COD models and single-agent object detection models. We evaluate TUQCP on V2X-Sim, a comprehensive collaborative perception dataset for autonomous driving, and demonstrate a 80.41% improvement in object detection accuracy compared to the baselines under the same adversarial attacks. TUQCP demonstrates the importance of uncertainty quantification to COD under adversarial attacks.
PatchCURE: Improving Certifiable Robustness, Model Utility, and Computation Efficiency of Adversarial Patch Defenses
Oct 19, 2023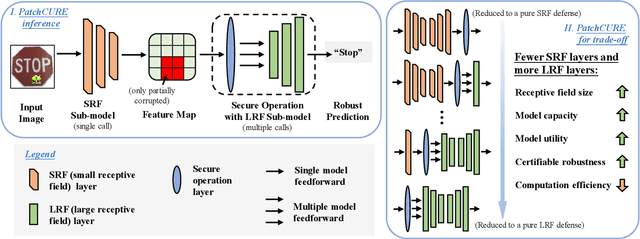
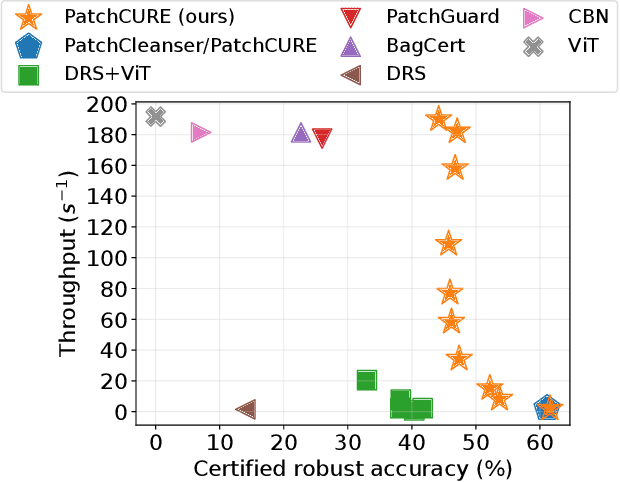

State-of-the-art defenses against adversarial patch attacks can now achieve strong certifiable robustness with a marginal drop in model utility. However, this impressive performance typically comes at the cost of 10-100x more inference-time computation compared to undefended models -- the research community has witnessed an intense three-way trade-off between certifiable robustness, model utility, and computation efficiency. In this paper, we propose a defense framework named PatchCURE to approach this trade-off problem. PatchCURE provides sufficient "knobs" for tuning defense performance and allows us to build a family of defenses: the most robust PatchCURE instance can match the performance of any existing state-of-the-art defense (without efficiency considerations); the most efficient PatchCURE instance has similar inference efficiency as undefended models. Notably, PatchCURE achieves state-of-the-art robustness and utility performance across all different efficiency levels, e.g., 16-23% absolute clean accuracy and certified robust accuracy advantages over prior defenses when requiring computation efficiency to be close to undefended models. The family of PatchCURE defenses enables us to flexibly choose appropriate defenses to satisfy given computation and/or utility constraints in practice.