 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-World: Building Software Engineering Agents in Docker-Free Environments
Feb 03, 2026Recent advances in large language models (LLMs) have enabled software engineering agents to tackle complex code modification tasks. Most existing approaches rely on execution feedback from containerized environments, which require dependency-complete setup and physical execution of programs and tests. While effective, this paradigm is resource-intensive and difficult to maintain, substantially complicating agent training and limiting scalability. We propose SWE-World, a Docker-free framework that replaces physical execution environments with a learned surrogate for training and evaluating software engineering agents. SWE-World leverages LLM-based models trained on real agent-environment interaction data to predict intermediate execution outcomes and final test feedback, enabling agents to learn without interacting with physical containerized environments. This design preserves the standard agent-environment interaction loop while eliminating the need for costly environment construction and maintenance during agent optimization and evaluation. Furthermore, because SWE-World can simulate the final evaluation outcomes of candidate trajectories without real submission, it enables selecting the best solution among multiple test-time attempts, thereby facilitating effective test-time scaling (TTS) in software engineering tasks. Experiments on SWE-bench Verified demonstrate that SWE-World raises Qwen2.5-Coder-32B from 6.2\% to 52.0\% via Docker-free SFT, 55.0\% with Docker-free RL, and 68.2\% with further TTS. The code is available at https://github.com/RUCAIBox/SWE-World
Enhancing Cross-task Transfer of Large Language Models via Activation Steering
Jul 17, 2025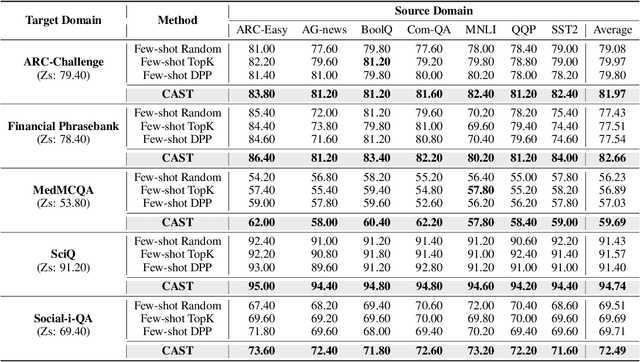
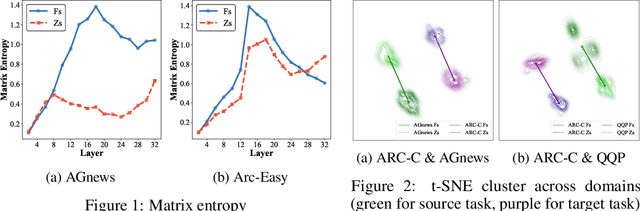

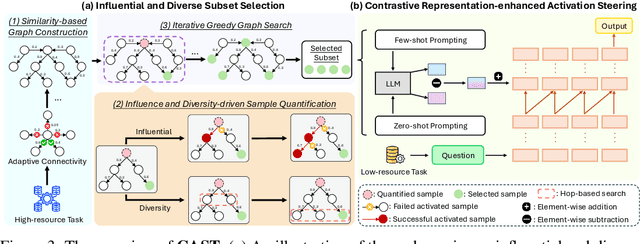
Large language models (LLMs) have shown impressive abilities in leveraging pretrained knowledge through prompting, but they often struggle with unseen tasks, particularly in data-scarce scenarios. While cross-task in-context learning offers a direct solution for transferring knowledge across tasks, it still faces critical challenges in terms of robustness, scalability, and efficiency. In this paper, we investigate whether cross-task transfer can be achieved via latent space steering without parameter updates or input expansion. Through an analysis of activation patterns in the latent space of LLMs, we observe that the enhanced activations induced by in-context examples have consistent patterns across different tasks. Inspired by these findings, we propose CAST, a novel Cross-task Activation Steering Transfer framework that enables effective transfer by manipulating the model's internal activation states. Our approach first selects influential and diverse samples from high-resource tasks, then utilizes their contrastive representation-enhanced activations to adapt LLMs to low-resource tasks. Extensive experiments across both cross-domain and cross-lingual transfer settings show that our method outperforms competitive baselines and demonstrates superior scalability and lower computational costs.
Unlocking General Long Chain-of-Thought Reasoning Capabilities of Large Language Models via Representation Engineering
Mar 14, 2025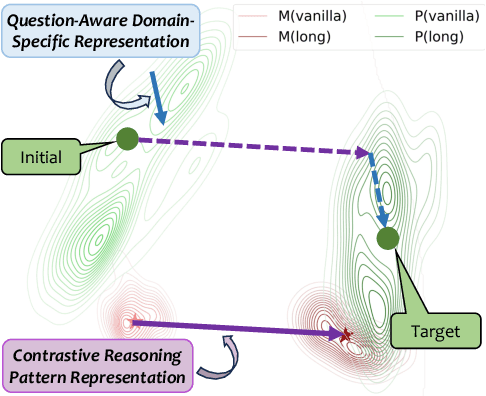



Recent advancements in long chain-of-thoughts(long CoTs) have significantly improved the reasoning capabilities of large language models(LLMs). Existing work finds that the capability of long CoT reasoning can be efficiently elicited by tuning on only a few examples and can easily transfer to other tasks. This motivates us to investigate whether long CoT reasoning is a general capability for LLMs. In this work, we conduct an empirical analysis for this question from the perspective of representation. We find that LLMs do encode long CoT reasoning as a general capability, with a clear distinction from vanilla CoTs. Furthermore, domain-specific representations are also required for the effective transfer of long CoT reasoning. Inspired by these findings, we propose GLoRE, a novel representation engineering method to unleash the general long CoT reasoning capabilities of LLMs. Extensive experiments demonstrate the effectiveness and efficiency of GLoRE in both in-domain and cross-domain scenarios.