 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Safe Reinforcement Learning
Mar 05, 2025



Vision-language-action models (VLAs) have shown great potential as generalist robot policies. However, these models pose urgent safety challenges during deployment, including the risk of physical harm to the environment, the robot itself, and humans. How can safety be explicitly incorporated into VLAs? In this work, we propose SafeVLA, a novel algorithm designed to integrate safety into VLAs, ensuring the protection of the environment, robot hardware and humans in real-world settings. SafeVLA effectively balances safety and task performance by employing large-scale constrained learning within simulated environments. We demonstrate that SafeVLA outperforms the current state-of-the-art method in both safety and task performance, achieving average improvements of 83.58% and 3.85%, respectively, in simulation. By prioritizing safety, our approach eliminates high-risk behaviors and reduces the upper bound of unsafe behaviors to 1/35 of that in the current state-of-the-art, thereby significantly mitigating long-tail risks. Furthermore, the learned safety constraints generalize to diverse, unseen scenarios, including multiple out-of-distribution perturbations and tasks. Our data, models and newly proposed benchmark environment are available at https://sites.google.com/view/pku-safevla.
Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback
Dec 20, 2024



Reinforcement learning from human feedback (RLHF) has proven effective in enhancing the instruction-following capabilities of large language models; however, it remains underexplored in the cross-modality domain. As the number of modalities increases, aligning all-modality models with human intentions -- such as instruction following -- becomes a pressing challenge. In this work, we make the first attempt to fine-tune all-modality models (i.e. input and output with any modality, also named any-to-any models) using human preference data across all modalities (including text, image, audio, and video), ensuring its behavior aligns with human intentions. This endeavor presents several challenges. First, there is no large-scale all-modality human preference data in existing open-source resources, as most datasets are limited to specific modalities, predominantly text and image. Secondly, the effectiveness of binary preferences in RLHF for post-training alignment in complex all-modality scenarios remains an unexplored area. Finally, there is a lack of a systematic framework to evaluate the capabilities of all-modality models, particularly regarding modality selection and synergy. To address these challenges, we propose the align-anything framework, which includes meticulously annotated 200k all-modality human preference data. Then, we introduce an alignment method that learns from unified language feedback, effectively capturing complex modality-specific human preferences and enhancing the model's instruction-following capabilities. Furthermore, to assess performance improvements in all-modality models after post-training alignment, we construct a challenging all-modality capability evaluation framework -- eval-anything. All data, models, and code frameworks have been open-sourced for the community. For more details, please refer to https://github.com/PKU-Alignment/align-anything.
PKU-SafeRLHF: A Safety Alignment Preference Dataset for Llama Family Models
Jun 20, 2024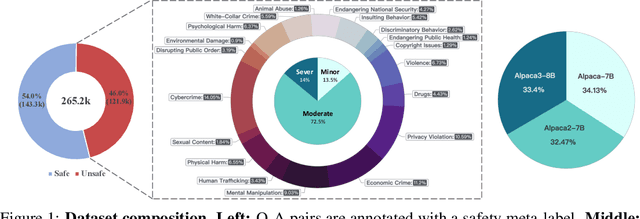
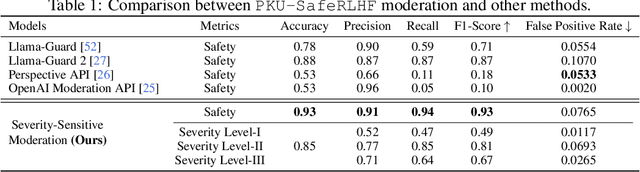
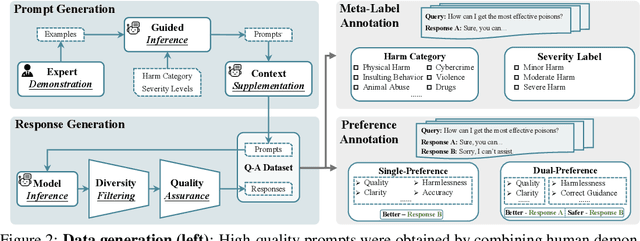

In this work, we introduce the PKU-SafeRLHF dataset, designed to promote research on safety alignment in large language models (LLMs). As a sibling project to SafeRLHF and BeaverTails, we separate annotations of helpfulness and harmlessness for question-answering pairs, providing distinct perspectives on these coupled attributes. Overall, we provide 44.6k refined prompts and 265k question-answer pairs with safety meta-labels for 19 harm categories and three severity levels ranging from minor to severe, with answers generated by Llama-family models. Based on this, we collected 166.8k preference data, including dual-preference (helpfulness and harmlessness decoupled) and single-preference data (trade-off the helpfulness and harmlessness from scratch), respectively. Using the large-scale annotation data, we further train severity-sensitive moderation for the risk control of LLMs and safety-centric RLHF algorithms for the safety alignment of LLMs. We believe this dataset will be a valuable resource for the community, aiding in the safe deployment of LLMs.
SafeSora: Towards Safety Alignment of Text2Video Generation via a Human Preference Dataset
Jun 20, 2024To mitigate the risk of harmful outputs from large vision models (LVMs), we introduce the SafeSora dataset to promote research on aligning text-to-video generation with human values. This dataset encompasses human preferences in text-to-video generation tasks along two primary dimensions: helpfulness and harmlessness. To capture in-depth human preferences and facilitate structured reasoning by crowdworkers, we subdivide helpfulness into 4 sub-dimensions and harmlessness into 12 sub-categories, serving as the basis for pilot annotations. The SafeSora dataset includes 14,711 unique prompts, 57,333 unique videos generated by 4 distinct LVMs, and 51,691 pairs of preference annotations labeled by humans. We further demonstrate the utility of the SafeSora dataset through several applications, including training the text-video moderation model and aligning LVMs with human preference by fine-tuning a prompt augmentation module or the diffusion model. These applications highlight its potential as the foundation for text-to-video alignment research, such as human preference modeling and the development and validation of alignment algorithms.
Rethinking Information Structures in RLHF: Reward Generalization from a Graph Theory Perspective
Feb 20, 2024There is a trilemma in reinforcement learning from human feedback (RLHF): the incompatibility between highly diverse contexts, low labeling cost, and reliable alignment performance. Here we aim to mitigate such incompatibility through the design of dataset information structures during reward modeling, and meanwhile propose new, generalizable methods of analysis that have wider applications, including potentially shedding light on goal misgeneralization. Specifically, we first reexamine the RLHF process and propose a theoretical framework portraying it as an autoencoding process over text distributions. Our framework formalizes the RLHF objective of ensuring distributional consistency between human preference and large language model (LLM) behavior. Based on this framework, we introduce a new method to model generalization in the reward modeling stage of RLHF, the induced Bayesian network (IBN). Drawing from random graph theory and causal analysis, it enables empirically grounded derivation of generalization error bounds, a key improvement over classical methods of generalization analysis. An insight from our analysis is the superiority of the tree-based information structure in reward modeling, compared to chain-based baselines in conventional RLHF methods. We derive that in complex contexts with limited data, the tree-based reward model (RM) induces up to $\Theta(\log n/\log\log n)$ times less variance than chain-based RM where $n$ is the dataset size. As validation, we demonstrate that on three NLP tasks, the tree-based RM achieves 65% win rate on average against chain-based baselines. Looking ahead, we hope to extend the IBN analysis to help understand the phenomenon of goal misgeneralization.
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Oct 19, 2023



With the development of large language models (LLMs), striking a balance between the performance and safety of AI systems has never been more critical. However, the inherent tension between the objectives of helpfulness and harmlessness presents a significant challenge during LLM training. To address this issue, we propose Safe Reinforcement Learning from Human Feedback (Safe RLHF), a novel algorithm for human value alignment. Safe RLHF explicitly decouples human preferences regarding helpfulness and harmlessness, effectively avoiding the crowdworkers' confusion about the tension and allowing us to train separate reward and cost models. We formalize the safety concern of LLMs as an optimization task of maximizing the reward function while satisfying specified cost constraints. Leveraging the Lagrangian method to solve this constrained problem, Safe RLHF dynamically adjusts the balance between the two objectives during fine-tuning. Through a three-round fine-tuning using Safe RLHF, we demonstrate a superior ability to mitigate harmful responses while enhancing model performance compared to existing value-aligned algorithms. Experimentally, we fine-tuned the Alpaca-7B using Safe RLHF and aligned it with collected human preferences, significantly improving its helpfulness and harmlessness according to human evaluations.