 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025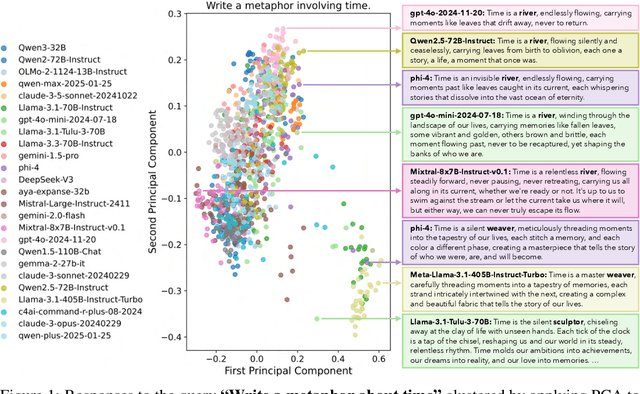
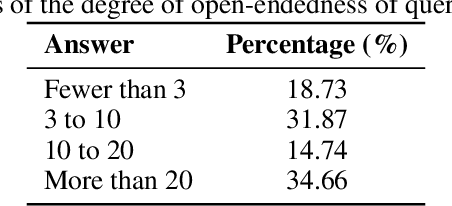
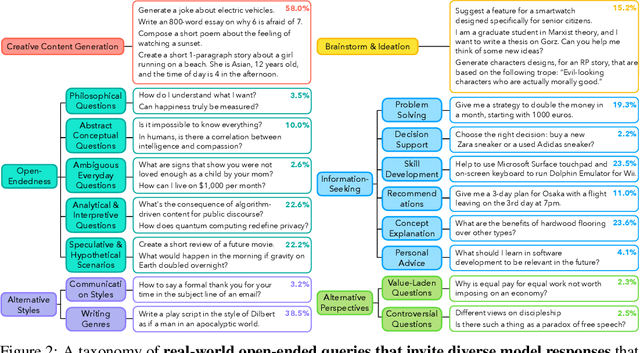

Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.
Learning Pluralistic User Preferences through Reinforcement Learning Fine-tuned Summaries
Jul 17, 2025
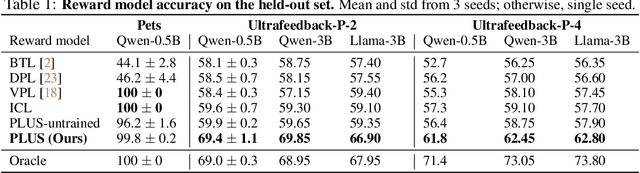
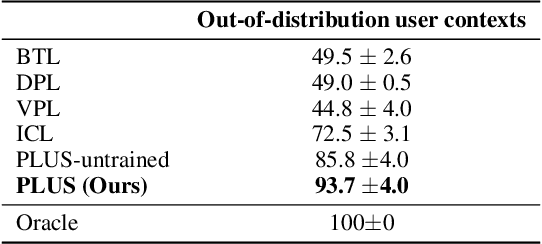
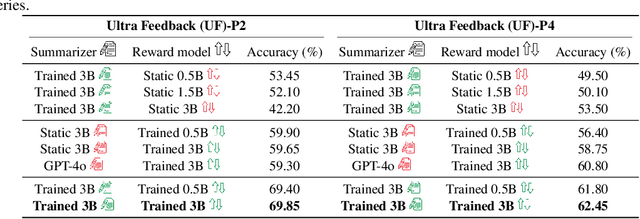
As everyday use cases of large language model (LLM) AI assistants have expanded, it is becoming increasingly important to personalize responses to align to different users' preferences and goals. While reinforcement learning from human feedback (RLHF) is effective at improving LLMs to be generally more helpful and fluent, it does not account for variability across users, as it models the entire user population with a single reward model. We present a novel framework, Preference Learning Using Summarization (PLUS), that learns text-based summaries of each user's preferences, characteristics, and past conversations. These summaries condition the reward model, enabling it to make personalized predictions about the types of responses valued by each user. We train the user-summarization model with reinforcement learning, and update the reward model simultaneously, creating an online co-adaptation loop. We show that in contrast with prior personalized RLHF techniques or with in-context learning of user information, summaries produced by PLUS capture meaningful aspects of a user's preferences. Across different pluralistic user datasets, we show that our method is robust to new users and diverse conversation topics. Additionally, we demonstrate that the textual summaries generated about users can be transferred for zero-shot personalization of stronger, proprietary models like GPT-4. The resulting user summaries are not only concise and portable, they are easy for users to interpret and modify, allowing for more transparency and user control in LLM alignment.
Chasing Moving Targets with Online Self-Play Reinforcement Learning for Safer Language Models
Jun 09, 2025Conventional language model (LM) safety alignment relies on a reactive, disjoint procedure: attackers exploit a static model, followed by defensive fine-tuning to patch exposed vulnerabilities. This sequential approach creates a mismatch -- attackers overfit to obsolete defenses, while defenders perpetually lag behind emerging threats. To address this, we propose Self-RedTeam, an online self-play reinforcement learning algorithm where an attacker and defender agent co-evolve through continuous interaction. We cast safety alignment as a two-player zero-sum game, where a single model alternates between attacker and defender roles -- generating adversarial prompts and safeguarding against them -- while a reward LM adjudicates outcomes. This enables dynamic co-adaptation. Grounded in the game-theoretic framework of zero-sum games, we establish a theoretical safety guarantee which motivates the design of our method: if self-play converges to a Nash Equilibrium, the defender will reliably produce safe responses to any adversarial input. Empirically, Self-RedTeam uncovers more diverse attacks (+21.8% SBERT) compared to attackers trained against static defenders and achieves higher robustness on safety benchmarks (e.g., +65.5% on WildJailBreak) than defenders trained against static attackers. We further propose hidden Chain-of-Thought, allowing agents to plan privately, which boosts adversarial diversity and reduces over-refusals. Our results motivate a shift from reactive patching to proactive co-evolution in LM safety training, enabling scalable, autonomous, and robust self-improvement of LMs via multi-agent reinforcement learning (MARL).
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Oct 19, 2023



With the development of large language models (LLMs), striking a balance between the performance and safety of AI systems has never been more critical. However, the inherent tension between the objectives of helpfulness and harmlessness presents a significant challenge during LLM training. To address this issue, we propose Safe Reinforcement Learning from Human Feedback (Safe RLHF), a novel algorithm for human value alignment. Safe RLHF explicitly decouples human preferences regarding helpfulness and harmlessness, effectively avoiding the crowdworkers' confusion about the tension and allowing us to train separate reward and cost models. We formalize the safety concern of LLMs as an optimization task of maximizing the reward function while satisfying specified cost constraints. Leveraging the Lagrangian method to solve this constrained problem, Safe RLHF dynamically adjusts the balance between the two objectives during fine-tuning. Through a three-round fine-tuning using Safe RLHF, we demonstrate a superior ability to mitigate harmful responses while enhancing model performance compared to existing value-aligned algorithms. Experimentally, we fine-tuned the Alpaca-7B using Safe RLHF and aligned it with collected human preferences, significantly improving its helpfulness and harmlessness according to human evaluations.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset
Jul 10, 2023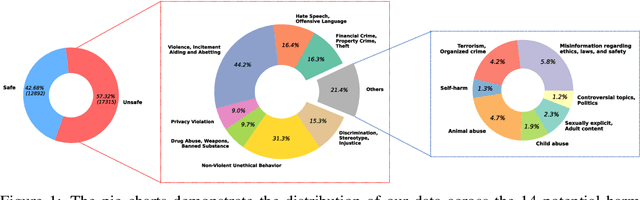



In this paper, we introduce the BeaverTails dataset, aimed at fostering research on safety alignment in large language models (LLMs). This dataset uniquely separates annotations of helpfulness and harmlessness for question-answering pairs, thus offering distinct perspectives on these crucial attributes. In total, we have compiled safety meta-labels for 30,207 question-answer (QA) pairs and gathered 30,144 pairs of expert comparison data for both the helpfulness and harmlessness metrics. We further showcase applications of BeaverTails in content moderation and reinforcement learning with human feedback (RLHF), emphasizing its potential for practical safety measures in LLMs. We believe this dataset provides vital resources for the community, contributing towards the safe development and deployment of LLMs. Our project page is available at the following URL: https://sites.google.com/view/pku-beavertails.
OmniSafe: An Infrastructure for Accelerating Safe Reinforcement Learning Research
May 16, 2023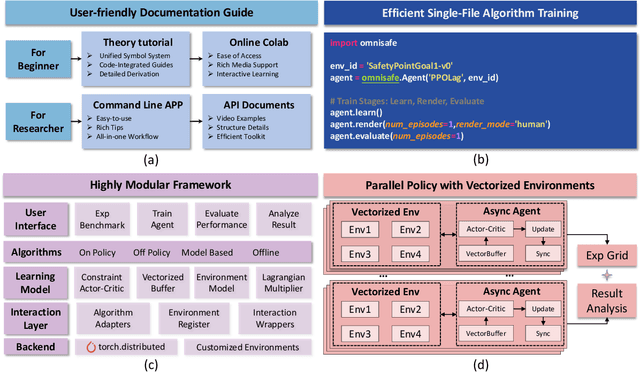
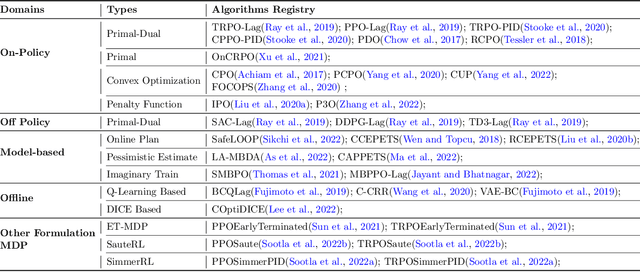
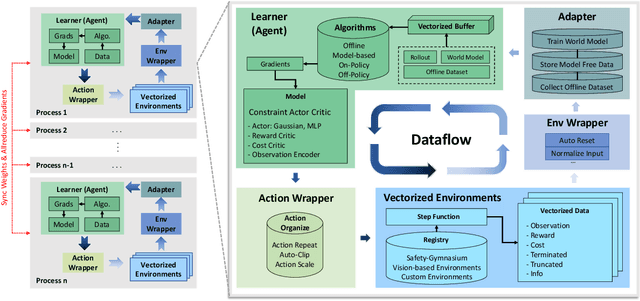
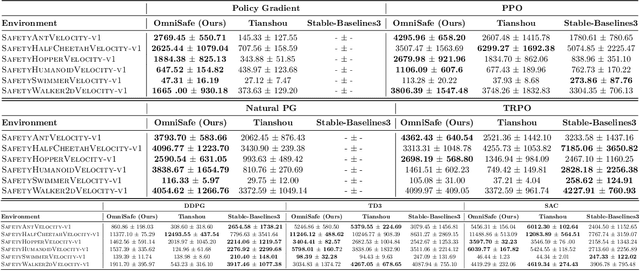
AI systems empowered by reinforcement learning (RL) algorithms harbor the immense potential to catalyze societal advancement, yet their deployment is often impeded by significant safety concerns. Particularly in safety-critical applications, researchers have raised concerns about unintended harms or unsafe behaviors of unaligned RL agents. The philosophy of safe reinforcement learning (SafeRL) is to align RL agents with harmless intentions and safe behavioral patterns. In SafeRL, agents learn to develop optimal policies by receiving feedback from the environment, while also fulfilling the requirement of minimizing the risk of unintended harm or unsafe behavior. However, due to the intricate nature of SafeRL algorithm implementation, combining methodologies across various domains presents a formidable challenge. This had led to an absence of a cohesive and efficacious learning framework within the contemporary SafeRL research milieu. In this work, we introduce a foundational framework designed to expedite SafeRL research endeavors. Our comprehensive framework encompasses an array of algorithms spanning different RL domains and places heavy emphasis on safety elements. Our efforts are to make the SafeRL-related research process more streamlined and efficient, therefore facilitating further research in AI safety. Our project is released at: https://github.com/PKU-Alignment/omnisafe.
Proactive Multi-Camera Collaboration For 3D Human Pose Estimation
Mar 07, 2023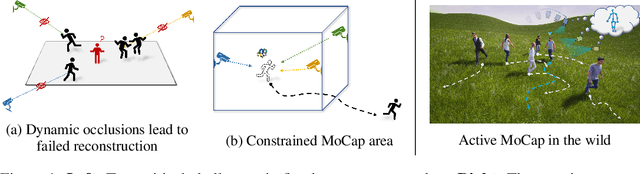



This paper presents a multi-agent reinforcement learning (MARL) scheme for proactive Multi-Camera Collaboration in 3D Human Pose Estimation in dynamic human crowds. Traditional fixed-viewpoint multi-camera solutions for human motion capture (MoCap) are limited in capture space and susceptible to dynamic occlusions. Active camera approaches proactively control camera poses to find optimal viewpoints for 3D reconstruction. However, current methods still face challenges with credit assignment and environment dynamics. To address these issues, our proposed method introduces a novel Collaborative Triangulation Contribution Reward (CTCR) that improves convergence and alleviates multi-agent credit assignment issues resulting from using 3D reconstruction accuracy as the shared reward. Additionally, we jointly train our model with multiple world dynamics learning tasks to better capture environment dynamics and encourage anticipatory behaviors for occlusion avoidance. We evaluate our proposed method in four photo-realistic UE4 environments to ensure validity and generalizability. Empirical results show that our method outperforms fixed and active baselines in various scenarios with different numbers of cameras and humans.