 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust but Verify: Adaptive Conditioning for Reference-Based Diffusion Super-Resolution via Implicit Reference Correlation Modeling
Feb 02, 2026Recent works have explored reference-based super-resolution (RefSR) to mitigate hallucinations in diffusion-based image restoration. A key challenge is that real-world degradations make correspondences between low-quality (LQ) inputs and reference (Ref) images unreliable, requiring adaptive control of reference usage. Existing methods either ignore LQ-Ref correlations or rely on brittle explicit matching, leading to over-reliance on misleading references or under-utilization of valuable cues. To address this, we propose Ada-RefSR, a single-step diffusion framework guided by a "Trust but Verify" principle: reference information is leveraged when reliable and suppressed otherwise. Its core component, Adaptive Implicit Correlation Gating (AICG), employs learnable summary tokens to distill dominant reference patterns and capture implicit correlations with LQ features. Integrated into the attention backbone, AICG provides lightweight, adaptive regulation of reference guidance, serving as a built-in safeguard against erroneous fusion. Experiments on multiple datasets demonstrate that Ada-RefSR achieves a strong balance of fidelity, naturalness, and efficiency, while remaining robust under varying reference alignment.
ClearSR: Latent Low-Resolution Image Embeddings Help Diffusion-Based Real-World Super Resolution Models See Clearer
Oct 18, 2024


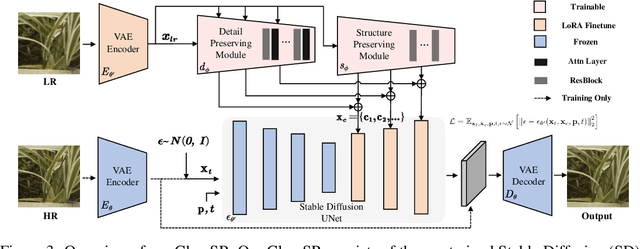
We present ClearSR, a new method that can better take advantage of latent low-resolution image (LR) embeddings for diffusion-based real-world image super-resolution (Real-ISR). Previous Real-ISR models mostly focus on how to activate more generative priors of text-to-image diffusion models to make the output high-resolution (HR) images look better. However, since these methods rely too much on the generative priors, the content of the output images is often inconsistent with the input LR ones. To mitigate the above issue, in this work, we explore using latent LR embeddings to constrain the control signals from ControlNet, and extract LR information at both detail and structure levels. We show that the proper use of latent LR embeddings can produce higher-quality control signals, which enables the super-resolution results to be more consistent with the LR image and leads to clearer visual results. In addition, we also show that latent LR embeddings can be used to control the inference stage, allowing for the improvement of fidelity and generation ability simultaneously. Experiments demonstrate that our model can achieve better performance across multiple metrics on several test sets and generate more consistent SR results with LR images than existing methods. Our code will be made publicly available.
Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models' Reasoning Performance
May 26, 2023

As large language models (LLMs) are continuously being developed, their evaluation becomes increasingly important yet challenging. This work proposes Chain-of-Thought Hub, an open-source evaluation suite on the multi-step reasoning capabilities of large language models. We are interested in this setting for two reasons: (1) from the behavior of GPT and PaLM model family, we observe that complex reasoning is likely to be a key differentiator between weaker and stronger LLMs; (2) we envisage large language models to become the next-generation computational platform and foster an ecosystem of LLM-based new applications, this naturally requires the foundation models to perform complex tasks that often involve the composition of linguistic and logical operations. Our approach is to compile a suite of challenging reasoning benchmarks to track the progress of LLMs. Our current results show that: (1) model scale clearly correlates with reasoning capabilities; (2) As of May 2023, Claude-v1.3 and PaLM-2 are the only two models that are comparable with GPT-4, while open-sourced models still lag behind; (3) LLaMA-65B performs closely to code-davinci-002, indicating that with successful further development such as reinforcement learning from human feedback (RLHF), it has great potential to be close to GPT-3.5-Turbo. Our results also suggest that for the open-source efforts to catch up, the community may focus more on building better base models and exploring RLHF.
Data Determines Distributional Robustness in Contrastive Language Image Pre-training (CLIP)
May 03, 2022
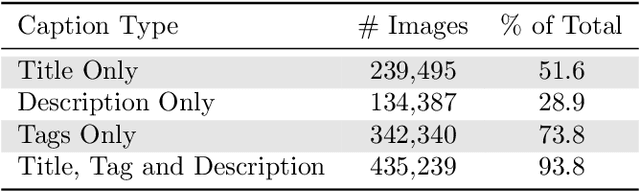

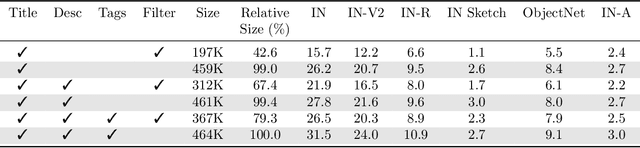
Contrastively trained image-text models such as CLIP, ALIGN, and BASIC have demonstrated unprecedented robustness to multiple challenging natural distribution shifts. Since these image-text models differ from previous training approaches in several ways, an important question is what causes the large robustness gains. We answer this question via a systematic experimental investigation. Concretely, we study five different possible causes for the robustness gains: (i) the training set size, (ii) the training distribution, (iii) language supervision at training time, (iv) language supervision at test time, and (v) the contrastive loss function. Our experiments show that the more diverse training distribution is the main cause for the robustness gains, with the other factors contributing little to no robustness. Beyond our experimental results, we also introduce ImageNet-Captions, a version of ImageNet with original text annotations from Flickr, to enable further controlled experiments of language-image training.
Mix and Match: Markov Chains & Mixing Times for Matching in Rideshare
Nov 30, 2019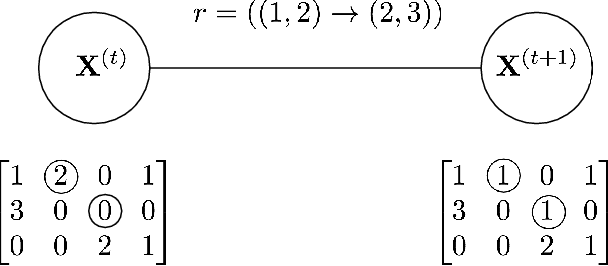
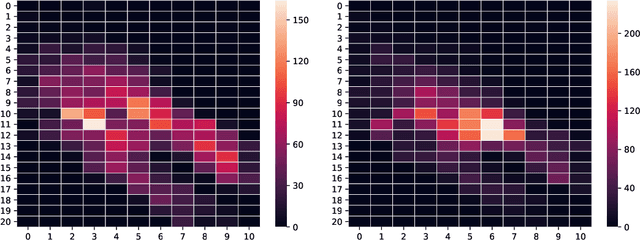
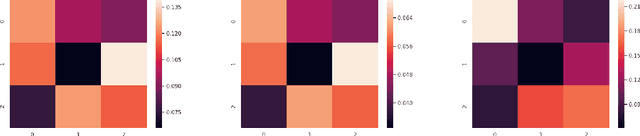
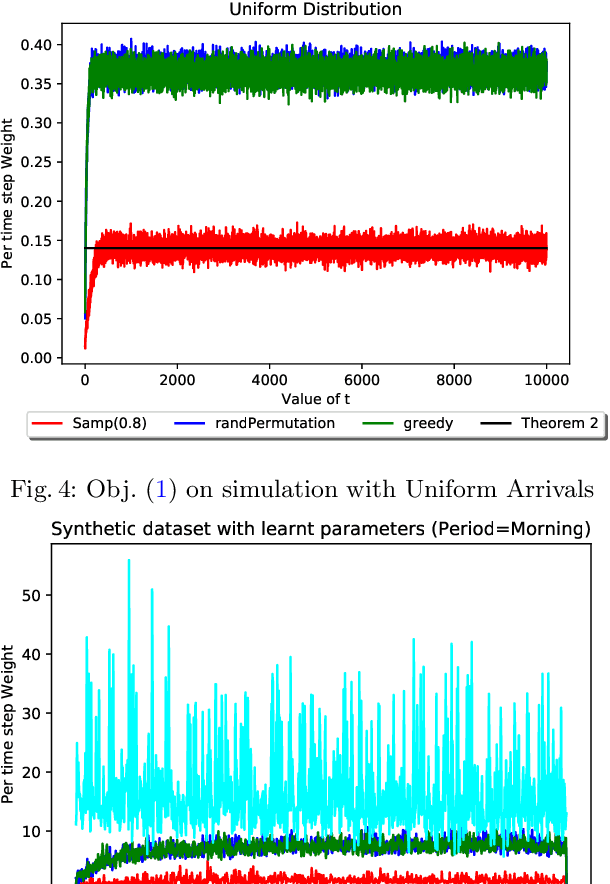
Rideshare platforms such as Uber and Lyft dynamically dispatch drivers to match riders' requests. We model the dispatching process in rideshare as a Markov chain that takes into account the geographic mobility of both drivers and riders over time. Prior work explores dispatch policies in the limit of such Markov chains; we characterize when this limit assumption is valid, under a variety of natural dispatch policies. We give explicit bounds on convergence in general, and exact (including constants) convergence rates for special cases. Then, on simulated and real transit data, we show that our bounds characterize convergence rates -- even when the necessary theoretical assumptions are relaxed. Additionally these policies compare well against a standard reinforcement learning algorithm which optimizes for profit without any convergence properties.