 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Vision-Language Modeling via Concept Space Alignment
Mar 01, 2026We introduce V-SONAR, a vision-language embedding space extended from the text-only embedding space SONAR (Omnilingual Embeddings Team et al., 2026), which supports 1500 text languages and 177 speech languages. To construct V-SONAR, we propose a post-hoc alignment pipeline that maps the representations of an existing vision encoder into the SONAR space. We thoroughly evaluate V-SONAR and show that its embeddings achieve competitive performance on text-to-video retrieval. Equipped with the OMNISONAR text decoder, V-SONAR further surpasses state-of-the-art vision-language models on video captioning tasks, including DREAM-1K (BLEU 23.9 vs. 19.6) and PE-VIDEO (BLEU 39.0 vs. 30.0). Leveraging V-SONAR, we first demonstrate that the Large Concept Model (LCM; LCM team et al. 2024) operating in SONAR and trained with English text only, can perform both single- and multi-visual concept understanding in a zero-shot manner. Finally, we introduce V-LCM, which extends the LCM with vision-language instruction tuning. V-LCM encodes vision and language inputs into an unified sequence of latent embeddings via V-SONAR and SONAR, and it is trained with the same latent diffusion objective for next-embedding prediction as in LCM's text-only pre-training. Experiments on a large-scale multilingual and -modal instruction-tuning data mixture highlight the potential of V-LCM: V-LCM matches state-of-the-art vision-language models on tasks covering image/video captioning and question answering, while significantly outperforming them across 61 rich- to low-resource languages out of all 62 tested languages.
Self-Improving World Modelling with Latent Actions
Feb 05, 2026Internal modelling of the world -- predicting transitions between previous states $X$ and next states $Y$ under actions $Z$ -- is essential to reasoning and planning for LLMs and VLMs. Learning such models typically requires costly action-labelled trajectories. We propose SWIRL, a self-improvement framework that learns from state-only sequences by treating actions as a latent variable and alternating between Forward World Modelling (FWM) $P_θ(Y|X,Z)$ and an Inverse Dynamics Modelling (IDM) $Q_φ(Z|X,Y)$. SWIRL iterates two phases: (1) Variational Information Maximisation, which updates the FWM to generate next states that maximise conditional mutual information with latent actions given prior states, encouraging identifiable consistency; and (2) ELBO Maximisation, which updates the IDM to explain observed transitions, effectively performing coordinate ascent. Both models are trained with reinforcement learning (specifically, GRPO) with the opposite frozen model's log-probability as a reward signal. We provide theoretical learnability guarantees for both updates, and evaluate SWIRL on LLMs and VLMs across multiple environments: single-turn and multi-turn open-world visual dynamics and synthetic textual environments for physics, web, and tool calling. SWIRL achieves gains of 16% on AURORABench, 28% on ByteMorph, 16% on WorldPredictionBench, and 14% on StableToolBench.
Enabling Progressive Whole-slide Image Analysis with Multi-scale Pyramidal Network
Feb 02, 2026Multiple-instance Learning (MIL) is commonly used to undertake computational pathology (CPath) tasks, and the use of multi-scale patches allows diverse features across scales to be learned. Previous studies using multi-scale features in clinical applications rely on multiple inputs across magnifications with late feature fusion, which does not retain the link between features across scales while the inputs are dependent on arbitrary, manufacturer-defined magnifications, being inflexible and computationally expensive. In this paper, we propose the Multi-scale Pyramidal Network (MSPN), which is plug-and-play over attention-based MIL that introduces progressive multi-scale analysis on WSI. Our MSPN consists of (1) grid-based remapping that uses high magnification features to derive coarse features and (2) the coarse guidance network (CGN) that learns coarse contexts. We benchmark MSPN as an add-on module to 4 attention-based frameworks using 4 clinically relevant tasks across 3 types of foundation model, as well as the pre-trained MIL framework. We show that MSPN consistently improves MIL across the compared configurations and tasks, while being lightweight and easy-to-use.
Lost in Space? Vision-Language Models Struggle with Relative Camera Pose Estimation
Jan 29, 2026Vision-Language Models (VLMs) perform well in 2D perception and semantic reasoning compared to their limited understanding of 3D spatial structure. We investigate this gap using relative camera pose estimation (RCPE), a fundamental vision task that requires inferring relative camera translation and rotation from a pair of images. We introduce VRRPI-Bench, a benchmark derived from unlabeled egocentric videos with verbalized annotations of relative camera motion, reflecting realistic scenarios with simultaneous translation and rotation around a shared object. We further propose VRRPI-Diag, a diagnostic benchmark that isolates individual motion degrees of freedom. Despite the simplicity of RCPE, most VLMs fail to generalize beyond shallow 2D heuristics, particularly for depth changes and roll transformations along the optical axis. Even state-of-the-art models such as GPT-5 ($0.64$) fall short of classic geometric baselines ($0.97$) and human performance ($0.92$). Moreover, VLMs exhibit difficulty in multi-image reasoning, with inconsistent performance (best $59.7\%$) when integrating spatial cues across frames. Our findings reveal limitations in grounding VLMs in 3D and multi-view spatial reasoning.
Iterative Multilingual Spectral Attribute Erasure
Jun 12, 2025Multilingual representations embed words with similar meanings to share a common semantic space across languages, creating opportunities to transfer debiasing effects between languages. However, existing methods for debiasing are unable to exploit this opportunity because they operate on individual languages. We present Iterative Multilingual Spectral Attribute Erasure (IMSAE), which identifies and mitigates joint bias subspaces across multiple languages through iterative SVD-based truncation. Evaluating IMSAE across eight languages and five demographic dimensions, we demonstrate its effectiveness in both standard and zero-shot settings, where target language data is unavailable, but linguistically similar languages can be used for debiasing. Our comprehensive experiments across diverse language models (BERT, LLaMA, Mistral) show that IMSAE outperforms traditional monolingual and cross-lingual approaches while maintaining model utility.
Bootstrapping World Models from Dynamics Models in Multimodal Foundation Models
Jun 06, 2025To what extent do vision-and-language foundation models possess a realistic world model (observation $\times$ action $\rightarrow$ observation) and a dynamics model (observation $\times$ observation $\rightarrow$ action), when actions are expressed through language? While open-source foundation models struggle with both, we find that fine-tuning them to acquire a dynamics model through supervision is significantly easier than acquiring a world model. In turn, dynamics models can be used to bootstrap world models through two main strategies: 1) weakly supervised learning from synthetic data and 2) inference time verification. Firstly, the dynamics model can annotate actions for unlabelled pairs of video frame observations to expand the training data. We further propose a new objective, where image tokens in observation pairs are weighted by their importance, as predicted by a recognition model. Secondly, the dynamics models can assign rewards to multiple samples of the world model to score them, effectively guiding search at inference time. We evaluate the world models resulting from both strategies through the task of action-centric image editing on Aurora-Bench. Our best model achieves a performance competitive with state-of-the-art image editing models, improving on them by a margin of $15\%$ on real-world subsets according to GPT4o-as-judge, and achieving the best average human evaluation across all subsets of Aurora-Bench.
What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
Feb 12, 2025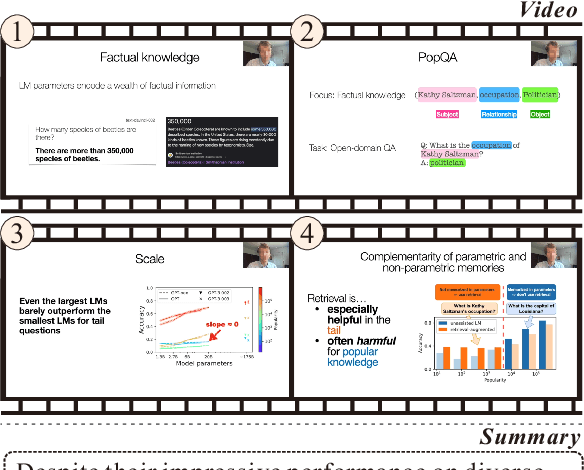
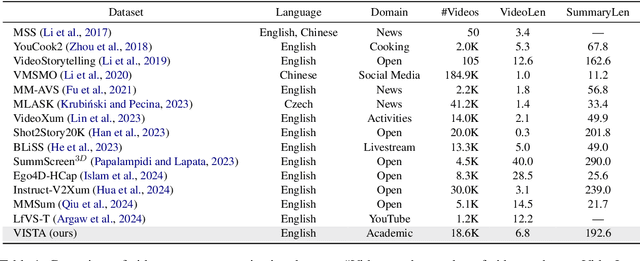

Transforming recorded videos into concise and accurate textual summaries is a growing challenge in multimodal learning. This paper introduces VISTA, a dataset specifically designed for video-to-text summarization in scientific domains. VISTA contains 18,599 recorded AI conference presentations paired with their corresponding paper abstracts. We benchmark the performance of state-of-the-art large models and apply a plan-based framework to better capture the structured nature of abstracts. Both human and automated evaluations confirm that explicit planning enhances summary quality and factual consistency. However, a considerable gap remains between models and human performance, highlighting the challenges of scientific video summarization.
Multiple Instance Learning with Coarse-to-Fine Self-Distillation
Feb 04, 2025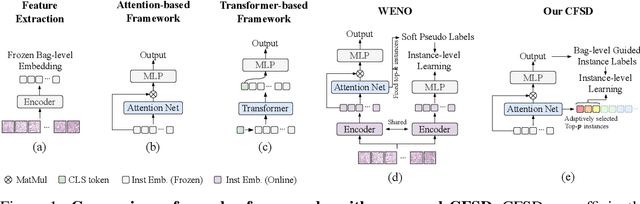
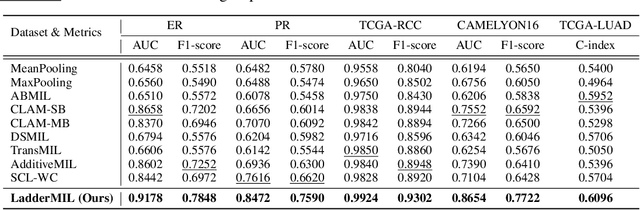
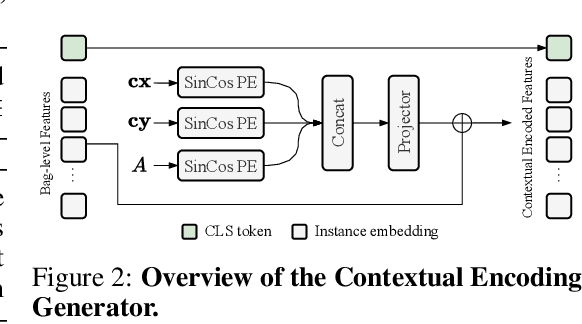
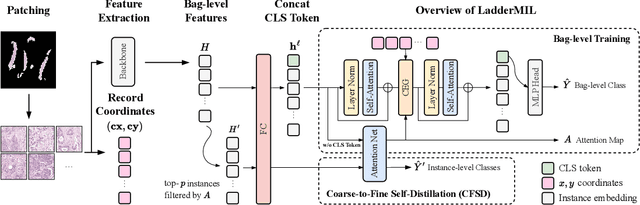
Multiple Instance Learning (MIL) for whole slide image (WSI) analysis in computational pathology often neglects instance-level learning as supervision is typically provided only at the bag level. In this work, we present PathMIL, a framework designed to improve MIL through two perspectives: (1) employing instance-level supervision and (2) learning inter-instance contextual information on bag level. Firstly, we propose a novel Coarse-to-Fine Self-Distillation (CFSD) paradigm, to probe and distil a classifier trained with bag-level information to obtain instance-level labels which could effectively provide the supervision for the same classifier in a finer way. Secondly, to capture inter-instance contextual information in WSI, we propose Two-Dimensional Positional Encoding (2DPE), which encodes the spatial appearance of instances within a bag. We also theoretically and empirically prove the instance-level learnability of CFSD. PathMIL is evaluated on multiple benchmarking tasks, including subtype classification (TCGA-NSCLC), tumour classification (CAMELYON16), and an internal benchmark for breast cancer receptor status classification. Our method achieves state-of-the-art performance, with AUC scores of 0.9152 and 0.8524 for estrogen and progesterone receptor status classification, respectively, an AUC of 0.9618 for subtype classification, and 0.8634 for tumour classification, surpassing existing methods.
Eliciting In-context Retrieval and Reasoning for Long-context Large Language Models
Jan 14, 2025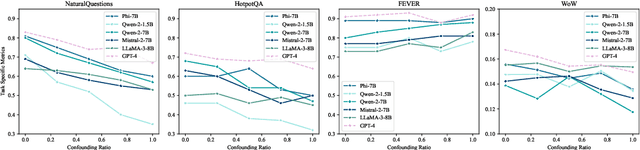

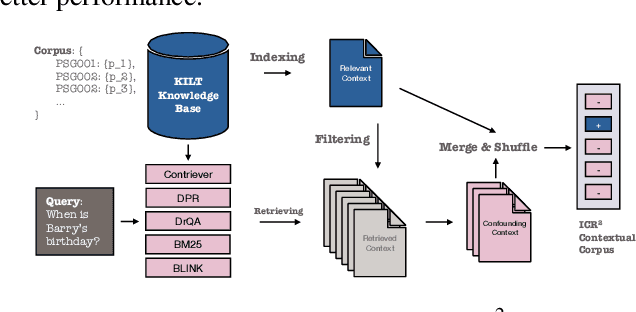
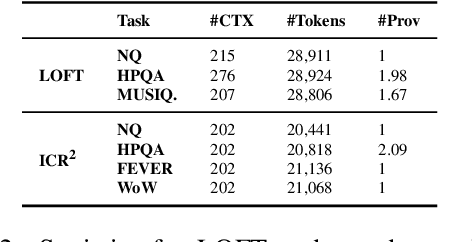
Recent advancements in long-context language models (LCLMs) promise to transform Retrieval-Augmented Generation (RAG) by simplifying pipelines. With their expanded context windows, LCLMs can process entire knowledge bases and perform retrieval and reasoning directly -- a capability we define as In-Context Retrieval and Reasoning (ICR^2). However, existing benchmarks like LOFT often overestimate LCLM performance by providing overly simplified contexts. To address this, we introduce ICR^2, a benchmark that evaluates LCLMs in more realistic scenarios by including confounding passages retrieved with strong retrievers. We then propose three methods to enhance LCLM performance: (1) retrieve-then-generate fine-tuning, (2) retrieval-attention-probing, which uses attention heads to filter and de-noise long contexts during decoding, and (3) joint retrieval head training alongside the generation head. Our evaluation of five well-known LCLMs on LOFT and ICR^2 demonstrates significant gains with our best approach applied to Mistral-7B: +17 and +15 points by Exact Match on LOFT, and +13 and +2 points on ICR^2, compared to vanilla RAG and supervised fine-tuning, respectively. It even outperforms GPT-4-Turbo on most tasks despite being a much smaller model.
Spectral Editing of Activations for Large Language Model Alignment
May 15, 2024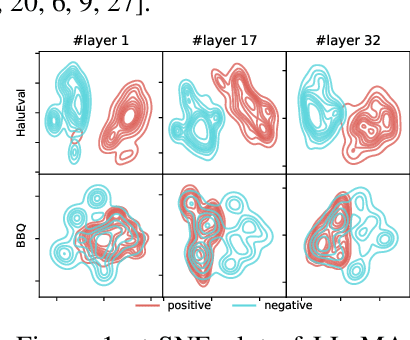
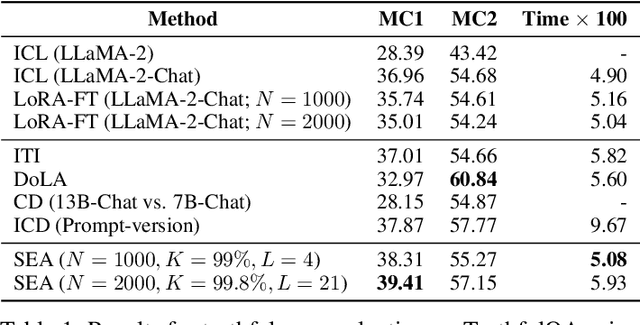

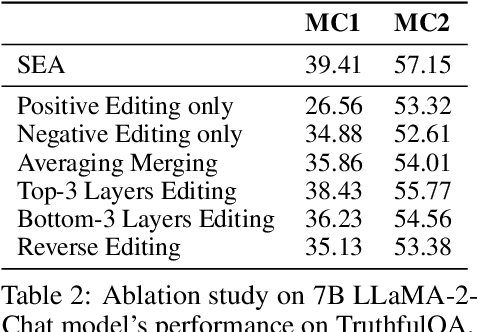
Large language models (LLMs) often exhibit undesirable behaviours, such as generating untruthful or biased content. Editing their internal representations has been shown to be effective in mitigating such behaviours on top of the existing alignment methods. We propose a novel inference-time editing method, namely spectral editing of activations (SEA), to project the input representations into directions with maximal covariance with the positive demonstrations (e.g., truthful) while minimising covariance with the negative demonstrations (e.g., hallucinated). We also extend our method to non-linear editing using feature functions. We run extensive experiments on benchmarks concerning truthfulness and bias with six open-source LLMs of different sizes and model families. The results demonstrate the superiority of SEA in effectiveness, generalisation to similar tasks, as well as inference and data efficiency. We also show that SEA editing only has a limited negative impact on other model capabilities.