 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Editing of Activations for Large Language Model Alignment
Paper and Code
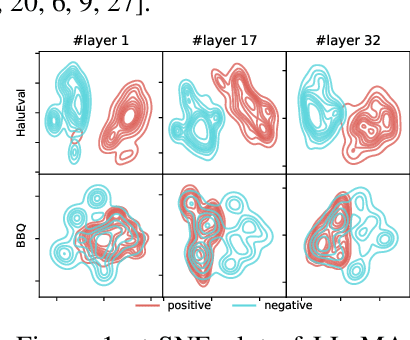
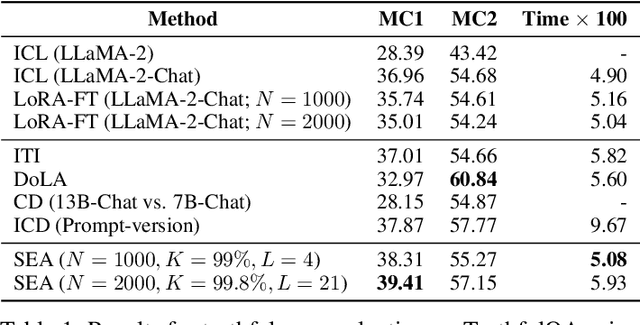

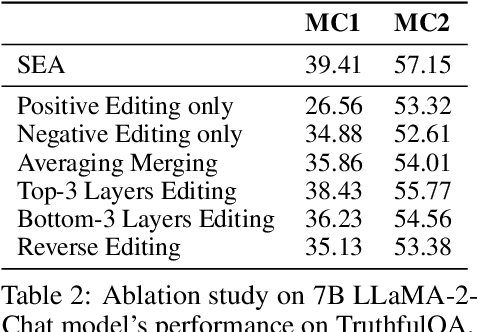
Large language models (LLMs) often exhibit undesirable behaviours, such as generating untruthful or biased content. Editing their internal representations has been shown to be effective in mitigating such behaviours on top of the existing alignment methods. We propose a novel inference-time editing method, namely spectral editing of activations (SEA), to project the input representations into directions with maximal covariance with the positive demonstrations (e.g., truthful) while minimising covariance with the negative demonstrations (e.g., hallucinated). We also extend our method to non-linear editing using feature functions. We run extensive experiments on benchmarks concerning truthfulness and bias with six open-source LLMs of different sizes and model families. The results demonstrate the superiority of SEA in effectiveness, generalisation to similar tasks, as well as inference and data efficiency. We also show that SEA editing only has a limited negative impact on other model capabilities.