 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Cropping: Layer-Adaptive Visual Localization and Decoding Enhancement
Feb 04, 2026Large Vision-Language Models (LVLMs) have advanced rapidly by aligning visual patches with the text embedding space, but a fixed visual-token budget forces images to be resized to a uniform pretraining resolution, often erasing fine-grained details and causing hallucinations via over-reliance on language priors. Recent attention-guided enhancement (e.g., cropping or region-focused attention allocation) alleviates this, yet it commonly hinges on a static "magic layer" empirically chosen on simple recognition benchmarks and thus may not transfer to complex reasoning tasks. In contrast to this static assumption, we propose a dynamic perspective on visual grounding. Through a layer-wise sensitivity analysis, we demonstrate that visual grounding is a dynamic process: while simple object recognition tasks rely on middle layers, complex visual search and reasoning tasks require visual information to be reactivated at deeper layers. Based on this observation, we introduce Visual Activation by Query (VAQ), a metric that identifies the layer whose attention map is most relevant to query-specific visual grounding by measuring attention sensitivity to the input query. Building on VAQ, we further propose LASER (Layer-adaptive Attention-guided Selective visual and decoding Enhancement for Reasoning), a training-free inference procedure that adaptively selects task-appropriate layers for visual localization and question answering. Experiments across diverse VQA benchmarks show that LASER significantly improves VQA accuracy across tasks with varying levels of complexity.
Beyond RAG for Agent Memory: Retrieval by Decoupling and Aggregation
Feb 02, 2026Agent memory systems often adopt the standard Retrieval-Augmented Generation (RAG) pipeline, yet its underlying assumptions differ in this setting. RAG targets large, heterogeneous corpora where retrieved passages are diverse, whereas agent memory is a bounded, coherent dialogue stream with highly correlated spans that are often duplicates. Under this shift, fixed top-$k$ similarity retrieval tends to return redundant context, and post-hoc pruning can delete temporally linked prerequisites needed for correct reasoning. We argue retrieval should move beyond similarity matching and instead operate over latent components, following decoupling to aggregation: disentangle memories into semantic components, organise them into a hierarchy, and use this structure to drive retrieval. We propose xMemory, which builds a hierarchy of intact units and maintains a searchable yet faithful high-level node organisation via a sparsity--semantics objective that guides memory split and merge. At inference, xMemory retrieves top-down, selecting a compact, diverse set of themes and semantics for multi-fact queries, and expanding to episodes and raw messages only when it reduces the reader's uncertainty. Experiments on LoCoMo and PerLTQA across the three latest LLMs show consistent gains in answer quality and token efficiency.
Co-Investigator AI: The Rise of Agentic AI for Smarter, Trustworthy AML Compliance Narratives
Sep 10, 2025Generating regulatorily compliant Suspicious Activity Report (SAR) remains a high-cost, low-scalability bottleneck in Anti-Money Laundering (AML) workflows. While large language models (LLMs) offer promising fluency, they suffer from factual hallucination, limited crime typology alignment, and poor explainability -- posing unacceptable risks in compliance-critical domains. This paper introduces Co-Investigator AI, an agentic framework optimized to produce Suspicious Activity Reports (SARs) significantly faster and with greater accuracy than traditional methods. Drawing inspiration from recent advances in autonomous agent architectures, such as the AI Co-Scientist, our approach integrates specialized agents for planning, crime type detection, external intelligence gathering, and compliance validation. The system features dynamic memory management, an AI-Privacy Guard layer for sensitive data handling, and a real-time validation agent employing the Agent-as-a-Judge paradigm to ensure continuous narrative quality assurance. Human investigators remain firmly in the loop, empowered to review and refine drafts in a collaborative workflow that blends AI efficiency with domain expertise. We demonstrate the versatility of Co-Investigator AI across a range of complex financial crime scenarios, highlighting its ability to streamline SAR drafting, align narratives with regulatory expectations, and enable compliance teams to focus on higher-order analytical work. This approach marks the beginning of a new era in compliance reporting -- bringing the transformative benefits of AI agents to the core of regulatory processes and paving the way for scalable, reliable, and transparent SAR generation.
Human Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
Beyond Prompting: An Efficient Embedding Framework for Open-Domain Question Answering
Mar 03, 2025



Large language models have recently pushed open domain question answering (ODQA) to new frontiers. However, prevailing retriever-reader pipelines often depend on multiple rounds of prompt level instructions, leading to high computational overhead, instability, and suboptimal retrieval coverage. In this paper, we propose EmbQA, an embedding-level framework that alleviates these shortcomings by enhancing both the retriever and the reader. Specifically, we refine query representations via lightweight linear layers under an unsupervised contrastive learning objective, thereby reordering retrieved passages to highlight those most likely to contain correct answers. Additionally, we introduce an exploratory embedding that broadens the model's latent semantic space to diversify candidate generation and employs an entropy-based selection mechanism to choose the most confident answer automatically. Extensive experiments across three open-source LLMs, three retrieval methods, and four ODQA benchmarks demonstrate that EmbQA substantially outperforms recent baselines in both accuracy and efficiency.
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Feb 28, 2025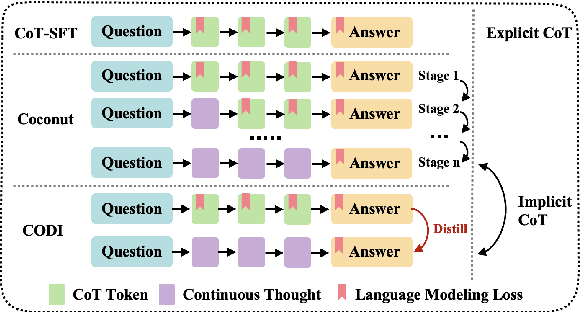
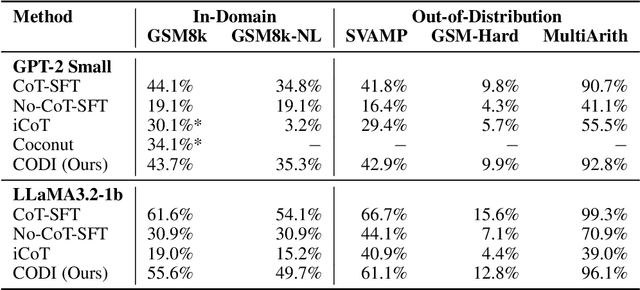
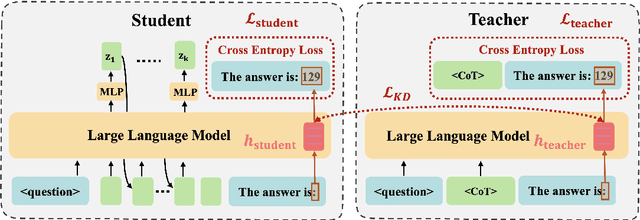
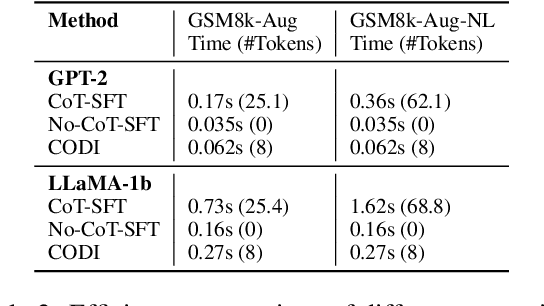
Chain-of-Thought (CoT) enhances Large Language Models (LLMs) by enabling step-by-step reasoning in natural language. However, the language space may be suboptimal for reasoning. While implicit CoT methods attempt to enable reasoning without explicit CoT tokens, they have consistently lagged behind explicit CoT method in task performance. We propose CODI (Continuous Chain-of-Thought via Self-Distillation), a novel framework that distills CoT into a continuous space, where a shared model acts as both teacher and student, jointly learning explicit and implicit CoT while aligning their hidden activation on the token generating the final answer. CODI is the first implicit CoT method to match explicit CoT's performance on GSM8k while achieving 3.1x compression, surpassing the previous state-of-the-art by 28.2% in accuracy. Furthermore, CODI demonstrates scalability, robustness, and generalizability to more complex CoT datasets. Additionally, CODI retains interpretability by decoding its continuous thoughts, making its reasoning process transparent. Our findings establish implicit CoT as not only a more efficient but a powerful alternative to explicit CoT.
EEE-QA: Exploring Effective and Efficient Question-Answer Representations
Mar 04, 2024Current approaches to question answering rely on pre-trained language models (PLMs) like RoBERTa. This work challenges the existing question-answer encoding convention and explores finer representations. We begin with testing various pooling methods compared to using the begin-of-sentence token as a question representation for better quality. Next, we explore opportunities to simultaneously embed all answer candidates with the question. This enables cross-reference between answer choices and improves inference throughput via reduced memory usage. Despite their simplicity and effectiveness, these methods have yet to be widely studied in current frameworks. We experiment with different PLMs, and with and without the integration of knowledge graphs. Results prove that the memory efficacy of the proposed techniques with little sacrifice in performance. Practically, our work enhances 38-100% throughput with 26-65% speedups on consumer-grade GPUs by allowing for considerably larger batch sizes. Our work sends a message to the community with promising directions in both representation quality and efficiency for the question-answering task in natural language processing.