 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning About Intent for Ambiguous Requests
Nov 13, 2025
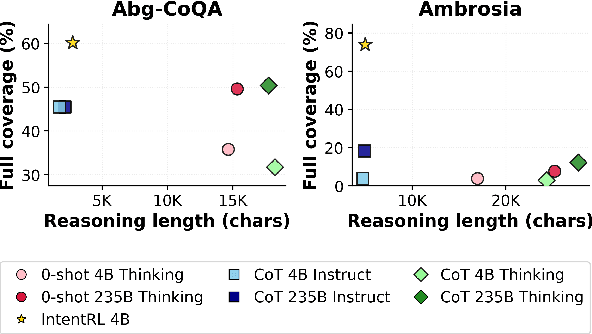


Large language models often respond to ambiguous requests by implicitly committing to one interpretation. Intent misunderstandings can frustrate users and create safety risks. To address this, we propose generating multiple interpretation-answer pairs in a single structured response to ambiguous requests. Our models are trained with reinforcement learning and customized reward functions using multiple valid answers as supervision. Experiments on conversational question answering and semantic parsing demonstrate that our method achieves higher coverage of valid answers than baseline approaches. Human evaluation confirms that predicted interpretations are highly aligned with their answers. Our approach promotes transparency with explicit interpretations, achieves efficiency by requiring only one generation step, and supports downstream applications through its structured output format.
Disambiguate First Parse Later: Generating Interpretations for Ambiguity Resolution in Semantic Parsing
Feb 25, 2025
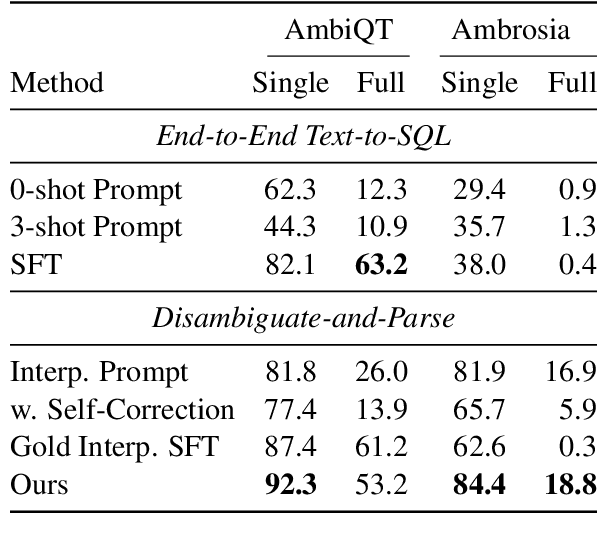

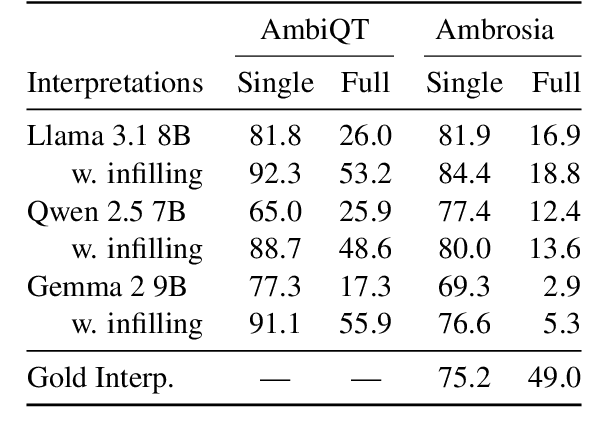
Handling ambiguity and underspecification is an important challenge in natural language interfaces, particularly for tasks like text-to-SQL semantic parsing. We propose a modular approach that resolves ambiguity using natural language interpretations before mapping these to logical forms (e.g., SQL queries). Although LLMs excel at parsing unambiguous utterances, they show strong biases for ambiguous ones, typically predicting only preferred interpretations. We constructively exploit this bias to generate an initial set of preferred disambiguations and then apply a specialized infilling model to identify and generate missing interpretations. To train the infilling model, we introduce an annotation method that uses SQL execution to validate different meanings. Our approach improves interpretation coverage and generalizes across datasets with different annotation styles, database structures, and ambiguity types.
AMBROSIA: A Benchmark for Parsing Ambiguous Questions into Database Queries
Jun 27, 2024Practical semantic parsers are expected to understand user utterances and map them to executable programs, even when these are ambiguous. We introduce a new benchmark, AMBROSIA, which we hope will inform and inspire the development of text-to-SQL parsers capable of recognizing and interpreting ambiguous requests. Our dataset contains questions showcasing three different types of ambiguity (scope ambiguity, attachment ambiguity, and vagueness), their interpretations, and corresponding SQL queries. In each case, the ambiguity persists even when the database context is provided. This is achieved through a novel approach that involves controlled generation of databases from scratch. We benchmark various LLMs on AMBROSIA, revealing that even the most advanced models struggle to identify and interpret ambiguity in questions.
Improving Generalization in Semantic Parsing by Increasing Natural Language Variation
Feb 13, 2024Text-to-SQL semantic parsing has made significant progress in recent years, with various models demonstrating impressive performance on the challenging Spider benchmark. However, it has also been shown that these models often struggle to generalize even when faced with small perturbations of previously (accurately) parsed expressions. This is mainly due to the linguistic form of questions in Spider which are overly specific, unnatural, and display limited variation. In this work, we use data augmentation to enhance the robustness of text-to-SQL parsers against natural language variations. Existing approaches generate question reformulations either via models trained on Spider or only introduce local changes. In contrast, we leverage the capabilities of large language models to generate more realistic and diverse questions. Using only a few prompts, we achieve a two-fold increase in the number of questions in Spider. Training on this augmented dataset yields substantial improvements on a range of evaluation sets, including robustness benchmarks and out-of-domain data.
Searching for Better Database Queries in the Outputs of Semantic Parsers
Oct 13, 2022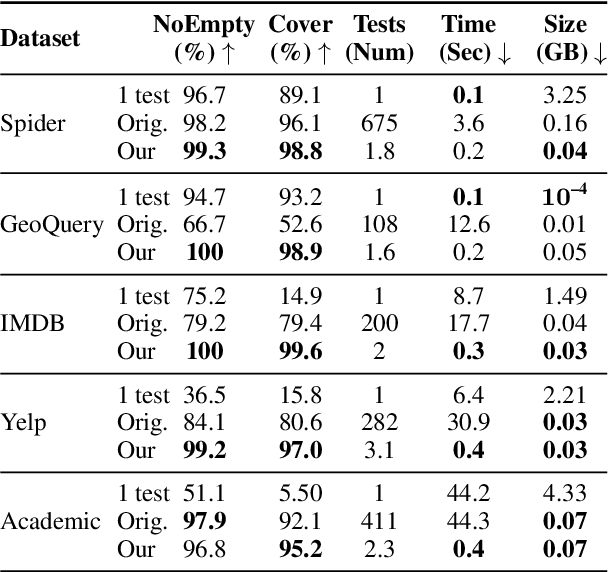
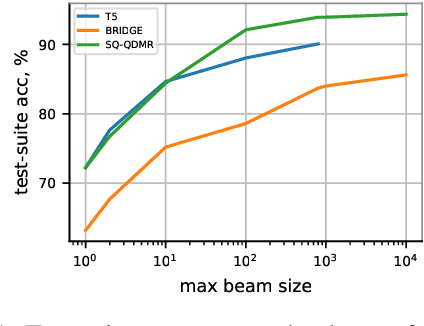
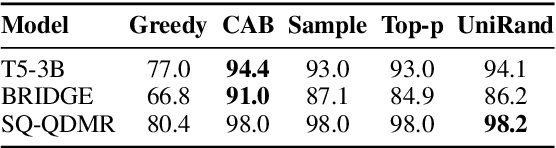
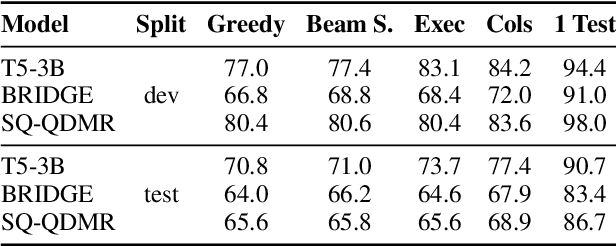
The task of generating a database query from a question in natural language suffers from ambiguity and insufficiently precise description of the goal. The problem is amplified when the system needs to generalize to databases unseen at training. In this paper, we consider the case when, at the test time, the system has access to an external criterion that evaluates the generated queries. The criterion can vary from checking that a query executes without errors to verifying the query on a set of tests. In this setting, we augment neural autoregressive models with a search algorithm that looks for a query satisfying the criterion. We apply our approach to the state-of-the-art semantic parsers and report that it allows us to find many queries passing all the tests on different datasets.
SPARQLing Database Queries from Intermediate Question Decompositions
Sep 13, 2021

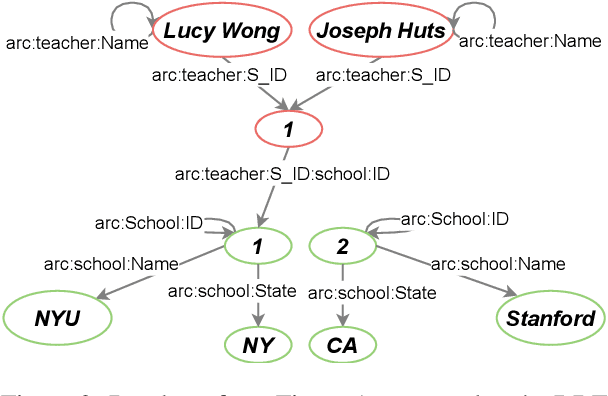

To translate natural language questions into executable database queries, most approaches rely on a fully annotated training set. Annotating a large dataset with queries is difficult as it requires query-language expertise. We reduce this burden using grounded in databases intermediate question representations. These representations are simpler to collect and were originally crowdsourced within the Break dataset (Wolfson et al., 2020). Our pipeline consists of two parts: a neural semantic parser that converts natural language questions into the intermediate representations and a non-trainable transpiler to the SPARQL query language (a standard language for accessing knowledge graphs and semantic web). We chose SPARQL because its queries are structurally closer to our intermediate representations (compared to SQL). We observe that the execution accuracy of queries constructed by our model on the challenging Spider dataset is comparable with the state-of-the-art text-to-SQL methods trained with annotated SQL queries. Our code and data are publicly available (see https://github.com/yandex-research/sparqling-queries).
Cost-Sensitive Training for Autoregressive Models
Dec 08, 2019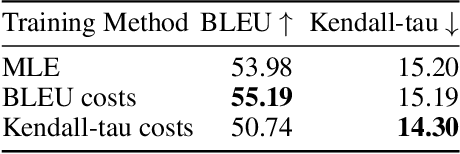
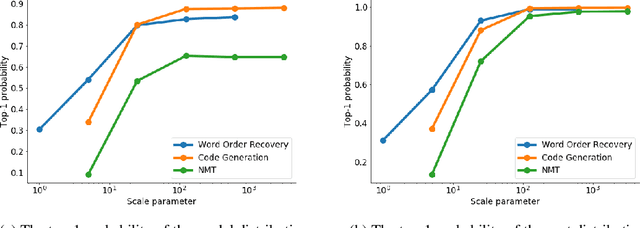
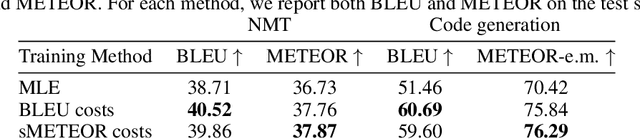

Training autoregressive models to better predict under the test metric, instead of maximizing the likelihood, has been reported to be beneficial in several use cases but brings additional complications, which prevent wider adoption. In this paper, we follow the learning-to-search approach (Daum\'e III et al., 2009; Leblond et al., 2018) and investigate its several components. First, we propose a way to construct a reference policy based on an alignment between the model output and ground truth. Our reference policy is optimal when applied to the Kendall-tau distance between permutations (appear in the task of word ordering) and helps when working with the METEOR score for machine translation. Second, we observe that the learning-to-search approach benefits from choosing the costs related to the test metrics. Finally, we study the effect of different learning objectives and find that the standard KL loss only learns several high-probability tokens and can be replaced with ranking objectives that target these tokens explicitly.