 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Sensitive Training for Autoregressive Models
Paper and Code
Dec 08, 2019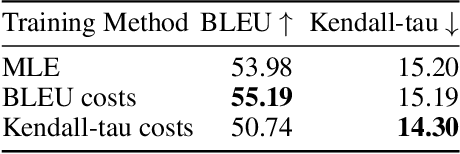
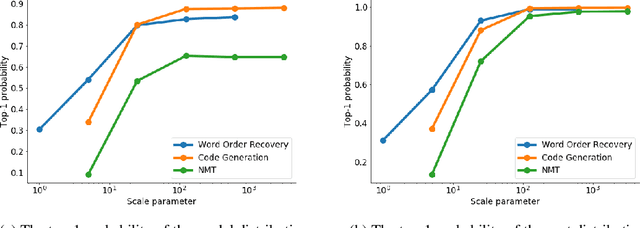
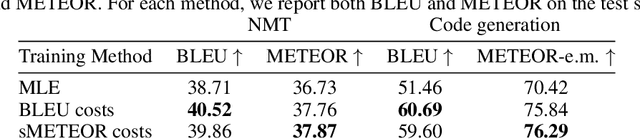

Training autoregressive models to better predict under the test metric, instead of maximizing the likelihood, has been reported to be beneficial in several use cases but brings additional complications, which prevent wider adoption. In this paper, we follow the learning-to-search approach (Daum\'e III et al., 2009; Leblond et al., 2018) and investigate its several components. First, we propose a way to construct a reference policy based on an alignment between the model output and ground truth. Our reference policy is optimal when applied to the Kendall-tau distance between permutations (appear in the task of word ordering) and helps when working with the METEOR score for machine translation. Second, we observe that the learning-to-search approach benefits from choosing the costs related to the test metrics. Finally, we study the effect of different learning objectives and find that the standard KL loss only learns several high-probability tokens and can be replaced with ranking objectives that target these tokens explicitly.