 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for Better Database Queries in the Outputs of Semantic Parsers
Oct 13, 2022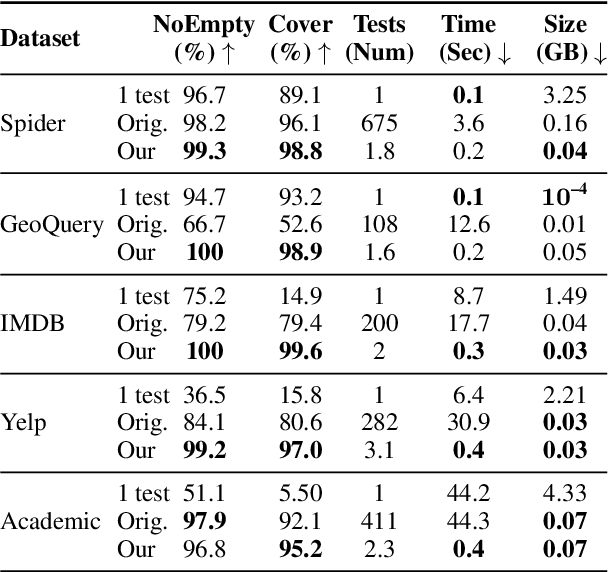
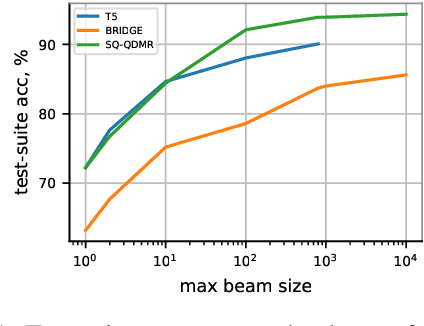
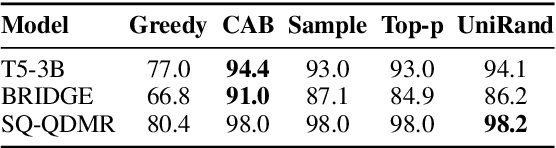
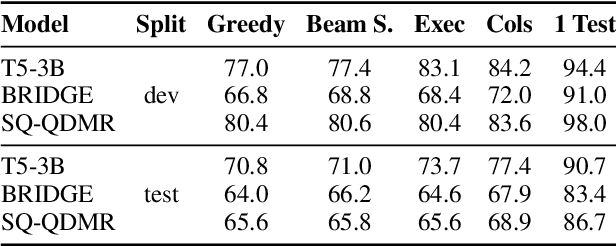
The task of generating a database query from a question in natural language suffers from ambiguity and insufficiently precise description of the goal. The problem is amplified when the system needs to generalize to databases unseen at training. In this paper, we consider the case when, at the test time, the system has access to an external criterion that evaluates the generated queries. The criterion can vary from checking that a query executes without errors to verifying the query on a set of tests. In this setting, we augment neural autoregressive models with a search algorithm that looks for a query satisfying the criterion. We apply our approach to the state-of-the-art semantic parsers and report that it allows us to find many queries passing all the tests on different datasets.
SPARQLing Database Queries from Intermediate Question Decompositions
Sep 13, 2021

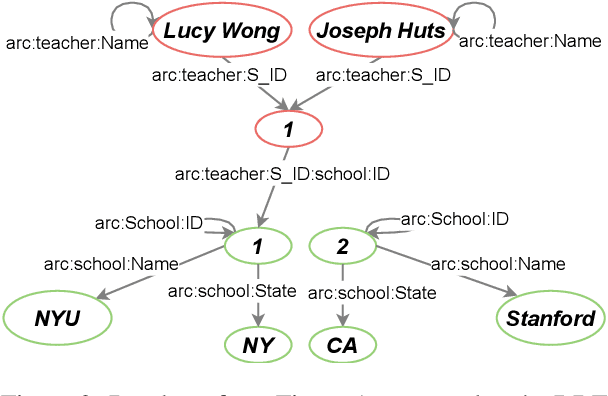

To translate natural language questions into executable database queries, most approaches rely on a fully annotated training set. Annotating a large dataset with queries is difficult as it requires query-language expertise. We reduce this burden using grounded in databases intermediate question representations. These representations are simpler to collect and were originally crowdsourced within the Break dataset (Wolfson et al., 2020). Our pipeline consists of two parts: a neural semantic parser that converts natural language questions into the intermediate representations and a non-trainable transpiler to the SPARQL query language (a standard language for accessing knowledge graphs and semantic web). We chose SPARQL because its queries are structurally closer to our intermediate representations (compared to SQL). We observe that the execution accuracy of queries constructed by our model on the challenging Spider dataset is comparable with the state-of-the-art text-to-SQL methods trained with annotated SQL queries. Our code and data are publicly available (see https://github.com/yandex-research/sparqling-queries).
OS2D: One-Stage One-Shot Object Detection by Matching Anchor Features
Mar 15, 2020
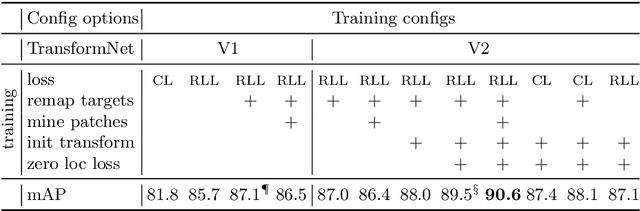
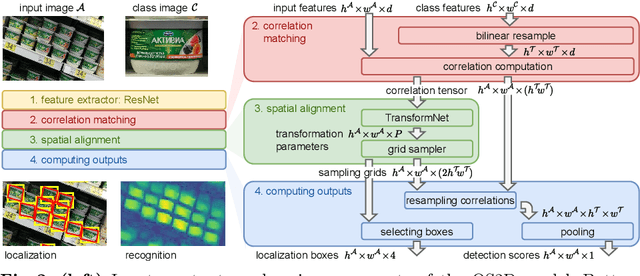
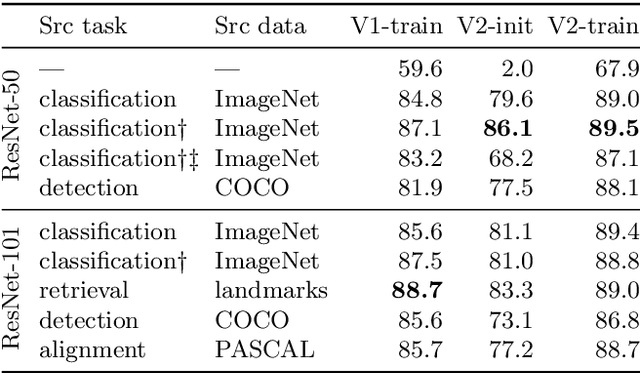
In this paper, we consider the task of one-shot object detection, which consists in detecting objects defined by a single demonstration. Differently from the standard object detection, the classes of objects used for training and testing do not overlap. We build the one-stage system that performs localization and recognition jointly. We use dense correlation matching of learned local features to find correspondences, a feed-forward geometric transformation model to align features and bilinear resampling of the correlation tensor to compute the detection score of the aligned features. All the components are differentiable, which allows end-to-end training. Experimental evaluation on several challenging domains (retail products, 3D objects, buildings and logos) shows that our method can detect unseen classes (e.g., toothpaste when trained on groceries) and outperforms several baselines by a significant margin. Our code is available online: https://github.com/aosokin/os2d .
Cost-Sensitive Training for Autoregressive Models
Dec 08, 2019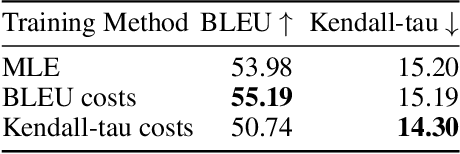
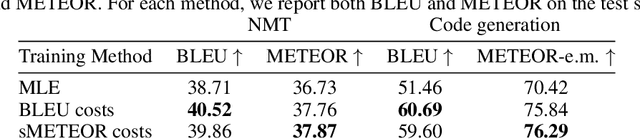

Training autoregressive models to better predict under the test metric, instead of maximizing the likelihood, has been reported to be beneficial in several use cases but brings additional complications, which prevent wider adoption. In this paper, we follow the learning-to-search approach (Daum\'e III et al., 2009; Leblond et al., 2018) and investigate its several components. First, we propose a way to construct a reference policy based on an alignment between the model output and ground truth. Our reference policy is optimal when applied to the Kendall-tau distance between permutations (appear in the task of word ordering) and helps when working with the METEOR score for machine translation. Second, we observe that the learning-to-search approach benefits from choosing the costs related to the test metrics. Finally, we study the effect of different learning objectives and find that the standard KL loss only learns several high-probability tokens and can be replaced with ranking objectives that target these tokens explicitly.
Scaling Matters in Deep Structured-Prediction Models
Feb 28, 2019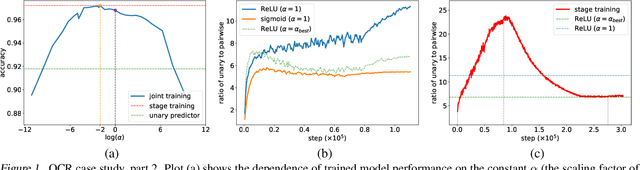
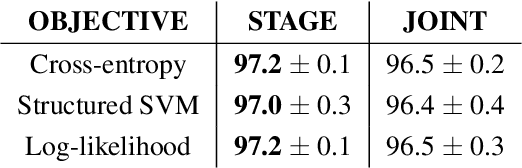
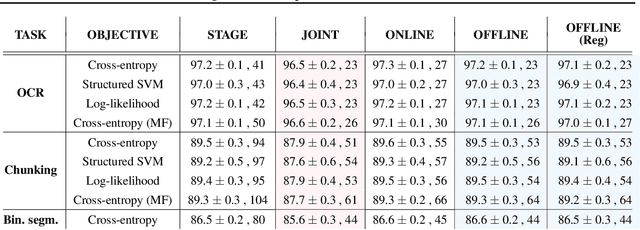
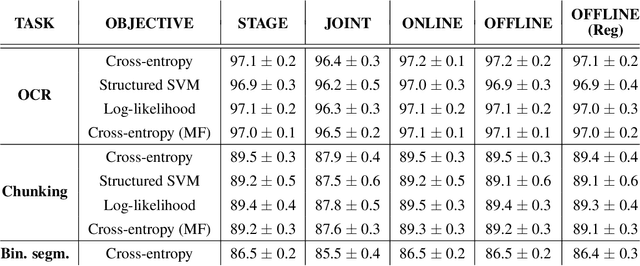
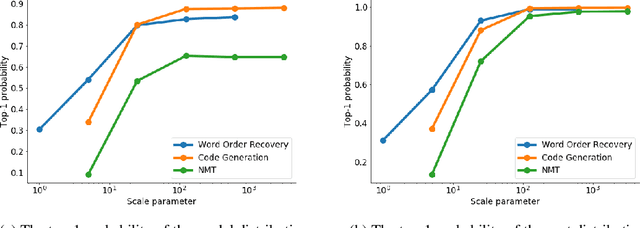
Deep structured-prediction energy-based models combine the expressive power of learned representations and the ability of embedding knowledge about the task at hand into the system. A common way to learn parameters of such models consists in a multistage procedure where different combinations of components are trained at different stages. The joint end-to-end training of the whole system is then done as the last fine-tuning stage. This multistage approach is time-consuming and cumbersome as it requires multiple runs until convergence and multiple rounds of hyperparameter tuning. From this point of view, it is beneficial to start the joint training procedure from the beginning. However, such approaches often unexpectedly fail and deliver results worse than the multistage ones. In this paper, we hypothesize that one reason for joint training of deep energy-based models to fail is the incorrect relative normalization of different components in the energy function. We propose online and offline scaling algorithms that fix the joint training and demonstrate their efficacy on three different tasks.
Tube-CNN: Modeling temporal evolution of appearance for object detection in video
Dec 06, 2018
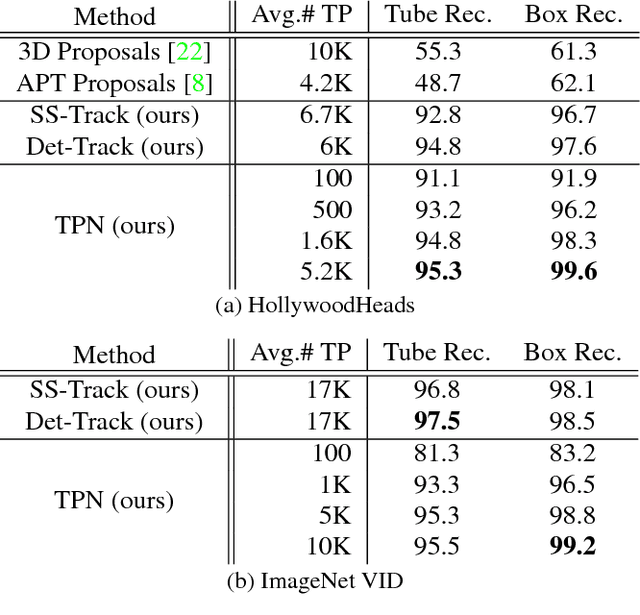
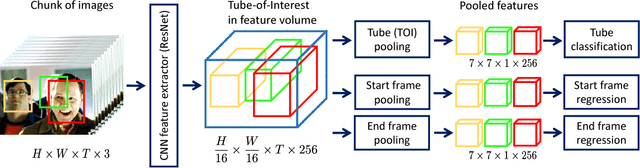
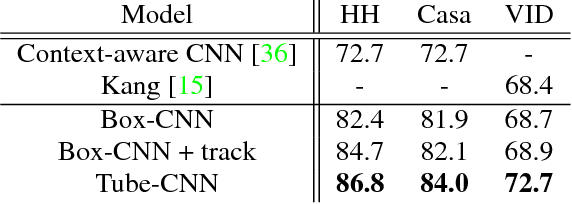
Object detection in video is crucial for many applications. Compared to images, video provides additional cues which can help to disambiguate the detection problem. Our goal in this paper is to learn discriminative models for the temporal evolution of object appearance and to use such models for object detection. To model temporal evolution, we introduce space-time tubes corresponding to temporal sequences of bounding boxes. We propose two CNN architectures for generating and classifying tubes, respectively. Our tube proposal network (TPN) first generates a large number of spatio-temporal tube proposals maximizing object recall. The Tube-CNN then implements a tube-level object detector in the video. Our method improves state of the art on two large-scale datasets for object detection in video: HollywoodHeads and ImageNet VID. Tube models show particular advantages in difficult dynamic scenes.
Marginal Weighted Maximum Log-likelihood for Efficient Learning of Perturb-and-Map models
Nov 21, 2018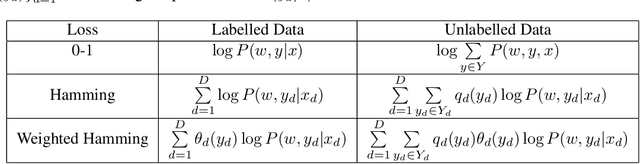

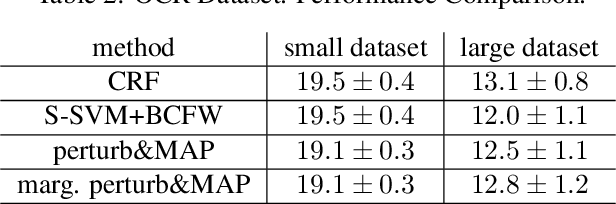

We consider the structured-output prediction problem through probabilistic approaches and generalize the "perturb-and-MAP" framework to more challenging weighted Hamming losses, which are crucial in applications. While in principle our approach is a straightforward marginalization, it requires solving many related MAP inference problems. We show that for log-supermodular pairwise models these operations can be performed efficiently using the machinery of dynamic graph cuts. We also propose to use double stochastic gradient descent, both on the data and on the perturbations, for efficient learning. Our framework can naturally take weak supervision (e.g., partial labels) into account. We conduct a set of experiments on medium-scale character recognition and image segmentation, showing the benefits of our algorithms.
Quantifying Learning Guarantees for Convex but Inconsistent Surrogates
Oct 26, 2018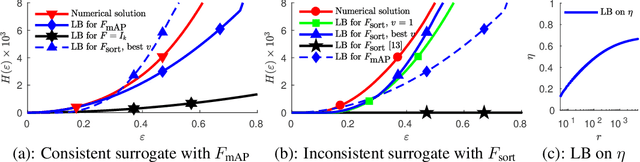
We study consistency properties of machine learning methods based on minimizing convex surrogates. We extend the recent framework of Osokin et al. (2017) for the quantitative analysis of consistency properties to the case of inconsistent surrogates. Our key technical contribution consists in a new lower bound on the calibration function for the quadratic surrogate, which is non-trivial (not always zero) for inconsistent cases. The new bound allows to quantify the level of inconsistency of the setting and shows how learning with inconsistent surrogates can have guarantees on sample complexity and optimization difficulty. We apply our theory to two concrete cases: multi-class classification with the tree-structured loss and ranking with the mean average precision loss. The results show the approximation-computation trade-offs caused by inconsistent surrogates and their potential benefits.
Modeling Spatio-Temporal Human Track Structure for Action Localization
Jun 28, 2018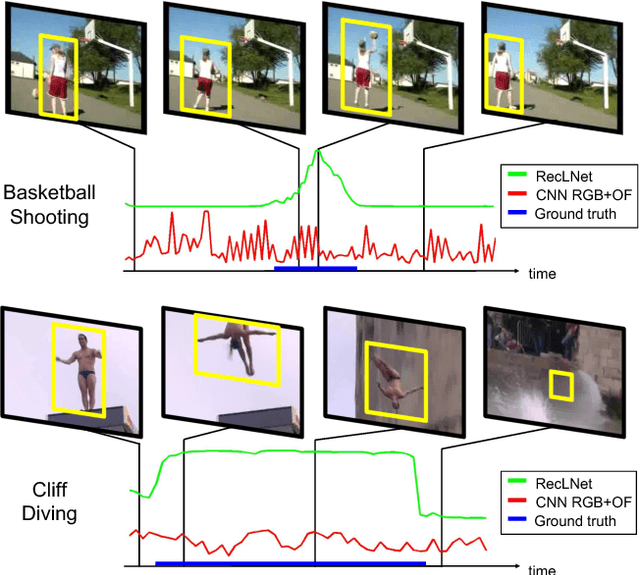
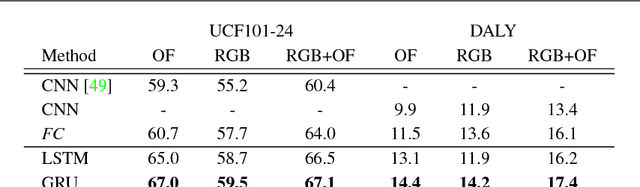
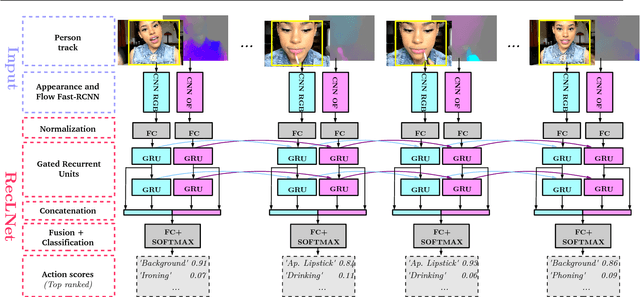

This paper addresses spatio-temporal localization of human actions in video. In order to localize actions in time, we propose a recurrent localization network (RecLNet) designed to model the temporal structure of actions on the level of person tracks. Our model is trained to simultaneously recognize and localize action classes in time and is based on two layer gated recurrent units (GRU) applied separately to two streams, i.e. appearance and optical flow streams. When used together with state-of-the-art person detection and tracking, our model is shown to improve substantially spatio-temporal action localization in videos. The gain is shown to be mainly due to improved temporal localization. We evaluate our method on two recent datasets for spatio-temporal action localization, UCF101-24 and DALY, demonstrating a significant improvement of the state of the art.
SEARNN: Training RNNs with Global-Local Losses
Mar 04, 2018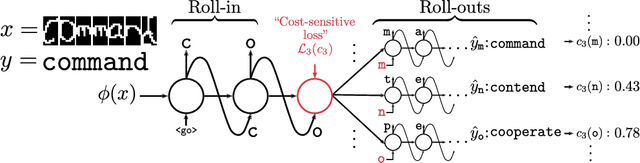
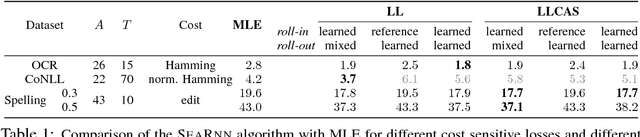

We propose SEARNN, a novel training algorithm for recurrent neural networks (RNNs) inspired by the "learning to search" (L2S) approach to structured prediction. RNNs have been widely successful in structured prediction applications such as machine translation or parsing, and are commonly trained using maximum likelihood estimation (MLE). Unfortunately, this training loss is not always an appropriate surrogate for the test error: by only maximizing the ground truth probability, it fails to exploit the wealth of information offered by structured losses. Further, it introduces discrepancies between training and predicting (such as exposure bias) that may hurt test performance. Instead, SEARNN leverages test-alike search space exploration to introduce global-local losses that are closer to the test error. We first demonstrate improved performance over MLE on two different tasks: OCR and spelling correction. Then, we propose a subsampling strategy to enable SEARNN to scale to large vocabulary sizes. This allows us to validate the benefits of our approach on a machine translation task.