 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould All Temporal Difference Learning Use Emphasis?
Paper and Code

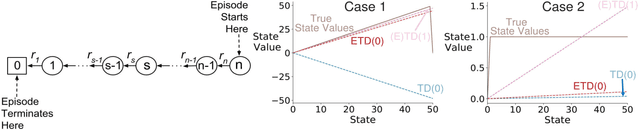


Emphatic Temporal Difference (ETD) learning has recently been proposed as a convergent off-policy learning method. ETD was proposed mainly to address convergence issues of conventional Temporal Difference (TD) learning under off-policy training but it is different from conventional TD learning even under on-policy training. A simple counterexample provided back in 2017 pointed to a potential class of problems where ETD converges but TD diverges. In this paper, we empirically show that ETD converges on a few other well-known on-policy experiments whereas TD either diverges or performs poorly. We also show that ETD outperforms TD on the mountain car prediction problem. Our results, together with a similar pattern observed under off-policy training in prior works, suggest that ETD might be a good substitute over conventional TD.