 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIKFST: IOO and KOO Algorithms for Accelerated and Precise WFST-based End-to-End Automatic Speech Recognition
Jan 01, 2026End-to-end automatic speech recognition has become the dominant paradigm in both academia and industry. To enhance recognition performance, the Weighted Finite-State Transducer (WFST) is widely adopted to integrate acoustic and language models through static graph composition, providing robust decoding and effective error correction. However, WFST decoding relies on a frame-by-frame autoregressive search over CTC posterior probabilities, which severely limits inference efficiency. Motivated by establishing a more principled compatibility between WFST decoding and CTC modeling, we systematically study the two fundamental components of CTC outputs, namely blank and non-blank frames, and identify a key insight: blank frames primarily encode positional information, while non-blank frames carry semantic content. Building on this observation, we introduce Keep-Only-One and Insert-Only-One, two decoding algorithms that explicitly exploit the structural roles of blank and non-blank frames to achieve significantly faster WFST-based inference without compromising recognition accuracy. Experiments on large-scale in-house, AISHELL-1, and LibriSpeech datasets demonstrate state-of-the-art recognition accuracy with substantially reduced decoding latency, enabling truly efficient and high-performance WFST decoding in modern speech recognition systems.
Enhancing Agentic RL with Progressive Reward Shaping and Value-based Sampling Policy Optimization
Dec 08, 2025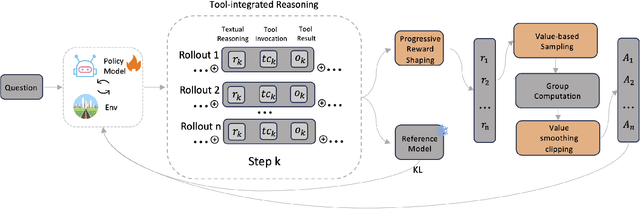
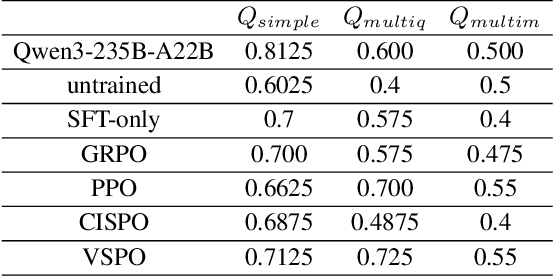
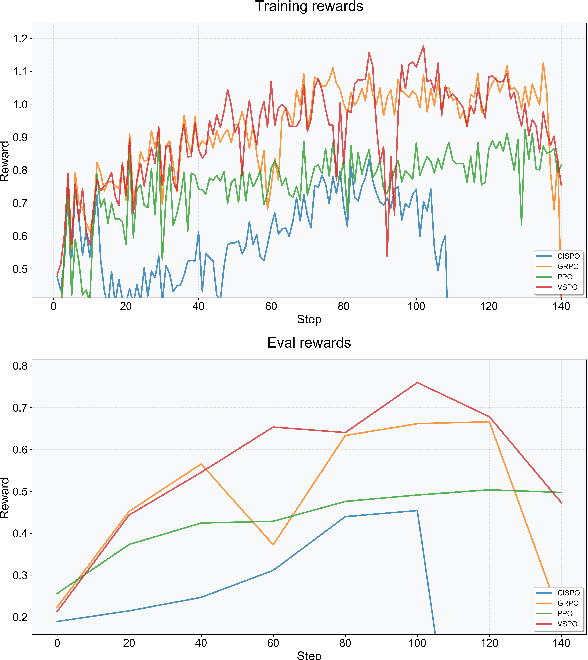
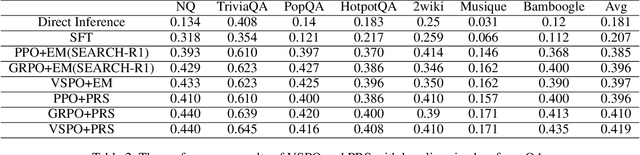
Large Language Models (LLMs) empowered with Tool-Integrated Reasoning (TIR) can iteratively plan, call external tools, and integrate returned information to solve complex, long-horizon reasoning tasks. Agentic Reinforcement Learning (Agentic RL) optimizes such models over full tool-interaction trajectories, but two key challenges hinder effectiveness: (1) Sparse, non-instructive rewards, such as binary 0-1 verifiable signals, provide limited guidance for intermediate steps and slow convergence; (2) Gradient degradation in Group Relative Policy Optimization (GRPO), where identical rewards within a rollout group yield zero advantage, reducing sample efficiency and destabilizing training. To address these challenges, we propose two complementary techniques: Progressive Reward Shaping (PRS) and Value-based Sampling Policy Optimization (VSPO). PRS is a curriculum-inspired reward design that introduces dense, stage-wise feedback - encouraging models to first master parseable and properly formatted tool calls, then optimize for factual correctness and answer quality. We instantiate PRS for short-form QA (with a length-aware BLEU to fairly score concise answers) and long-form QA (with LLM-as-a-Judge scoring to prevent reward hacking). VSPO is an enhanced GRPO variant that replaces low-value samples with prompts selected by a task-value metric balancing difficulty and uncertainty, and applies value-smoothing clipping to stabilize gradient updates. Experiments on multiple short-form and long-form QA benchmarks show that PRS consistently outperforms traditional binary rewards, and VSPO achieves superior stability, faster convergence, and higher final performance compared to PPO, GRPO, CISPO, and SFT-only baselines. Together, PRS and VSPO yield LLM-based TIR agents that generalize better across domains.
Breaking Through the Spike: Spike Window Decoding for Accelerated and Precise Automatic Speech Recognition
Jan 01, 2025



Recently, end-to-end automatic speech recognition has become the mainstream approach in both industry and academia. To optimize system performance in specific scenarios, the Weighted Finite-State Transducer (WFST) is extensively used to integrate acoustic and language models, leveraging its capacity to implicitly fuse language models within static graphs, thereby ensuring robust recognition while also facilitating rapid error correction. However, WFST necessitates a frame-by-frame search of CTC posterior probabilities through autoregression, which significantly hampers inference speed. In this work, we thoroughly investigate the spike property of CTC outputs and further propose the conjecture that adjacent frames to non-blank spikes carry semantic information beneficial to the model. Building on this, we propose the Spike Window Decoding algorithm, which greatly improves the inference speed by making the number of frames decoded in WFST linearly related to the number of spiking frames in the CTC output, while guaranteeing the recognition performance. Our method achieves SOTA recognition accuracy with significantly accelerates decoding speed, proven across both AISHELL-1 and large-scale In-House datasets, establishing a pioneering approach for integrating CTC output with WFST.