 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairGFL: Privacy-Preserving Fairness-Aware Federated Learning with Overlapping Subgraphs
Dec 29, 2025Graph federated learning enables the collaborative extraction of high-order information from distributed subgraphs while preserving the privacy of raw data. However, graph data often exhibits overlap among different clients. Previous research has demonstrated certain benefits of overlapping data in mitigating data heterogeneity. However, the negative effects have not been explored, particularly in cases where the overlaps are imbalanced across clients. In this paper, we uncover the unfairness issue arising from imbalanced overlapping subgraphs through both empirical observations and theoretical reasoning. To address this issue, we propose FairGFL (FAIRness-aware subGraph Federated Learning), a novel algorithm that enhances cross-client fairness while maintaining model utility in a privacy-preserving manner. Specifically, FairGFL incorporates an interpretable weighted aggregation approach to enhance fairness across clients, leveraging privacy-preserving estimation of their overlapping ratios. Furthermore, FairGFL improves the tradeoff between model utility and fairness by integrating a carefully crafted regularizer into the federated composite loss function. Through extensive experiments on four benchmark graph datasets, we demonstrate that FairGFL outperforms four representative baseline algorithms in terms of both model utility and fairness.
Review of Mathematical Optimization in Federated Learning
Dec 02, 2024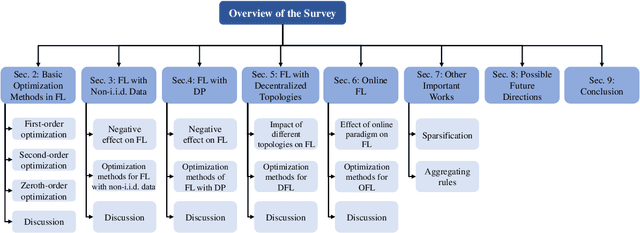
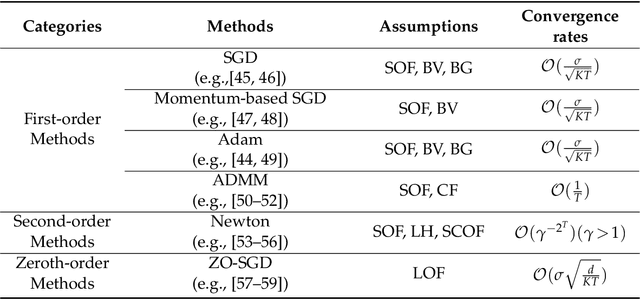
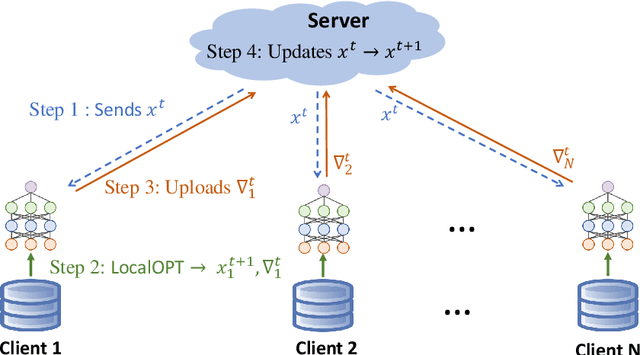

Federated Learning (FL) has been becoming a popular interdisciplinary research area in both applied mathematics and information sciences. Mathematically, FL aims to collaboratively optimize aggregate objective functions over distributed datasets while satisfying a variety of privacy and system constraints.Different from conventional distributed optimization methods, FL needs to address several specific issues (e.g., non-i.i.d. data distributions and differential private noises), which pose a set of new challenges in the problem formulation, algorithm design, and convergence analysis. In this paper, we will systematically review existing FL optimization research including their assumptions, formulations, methods, and theoretical results. Potential future directions are also discussed.
Understanding Byzantine Robustness in Federated Learning with A Black-box Server
Aug 12, 2024Federated learning (FL) becomes vulnerable to Byzantine attacks where some of participators tend to damage the utility or discourage the convergence of the learned model via sending their malicious model updates. Previous works propose to apply robust rules to aggregate updates from participators against different types of Byzantine attacks, while at the same time, attackers can further design advanced Byzantine attack algorithms targeting specific aggregation rule when it is known. In practice, FL systems can involve a black-box server that makes the adopted aggregation rule inaccessible to participants, which can naturally defend or weaken some Byzantine attacks. In this paper, we provide an in-depth understanding on the Byzantine robustness of the FL system with a black-box server. Our investigation demonstrates the improved Byzantine robustness of a black-box server employing a dynamic defense strategy. We provide both empirical evidence and theoretical analysis to reveal that the black-box server can mitigate the worst-case attack impact from a maximum level to an expectation level, which is attributed to the inherent inaccessibility and randomness offered by a black-box server.The source code is available at https://github.com/alibaba/FederatedScope/tree/Byzantine_attack_defense to promote further research in the community.
Latent Dirichlet Allocation Model Training with Differential Privacy
Oct 09, 2020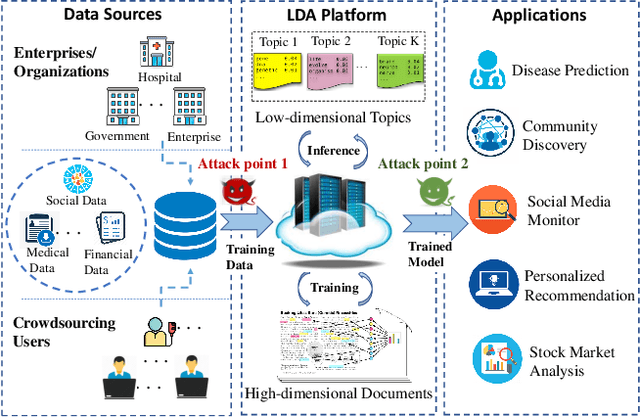
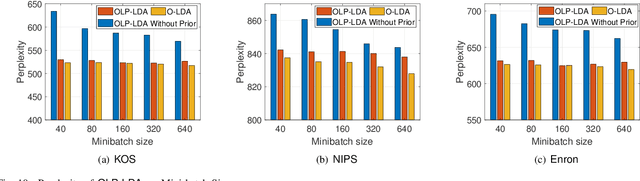
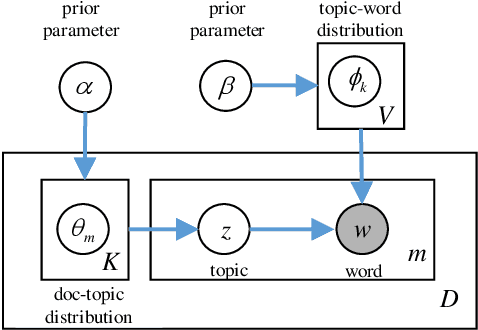
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for hidden semantic discovery of text data and serves as a fundamental tool for text analysis in various applications. However, the LDA model as well as the training process of LDA may expose the text information in the training data, thus bringing significant privacy concerns. To address the privacy issue in LDA, we systematically investigate the privacy protection of the main-stream LDA training algorithm based on Collapsed Gibbs Sampling (CGS) and propose several differentially private LDA algorithms for typical training scenarios. In particular, we present the first theoretical analysis on the inherent differential privacy guarantee of CGS based LDA training and further propose a centralized privacy-preserving algorithm (HDP-LDA) that can prevent data inference from the intermediate statistics in the CGS training. Also, we propose a locally private LDA training algorithm (LP-LDA) on crowdsourced data to provide local differential privacy for individual data contributors. Furthermore, we extend LP-LDA to an online version as OLP-LDA to achieve LDA training on locally private mini-batches in a streaming setting. Extensive analysis and experiment results validate both the effectiveness and efficiency of our proposed privacy-preserving LDA training algorithms.
On Privacy Protection of Latent Dirichlet Allocation Model Training
Jun 04, 2019
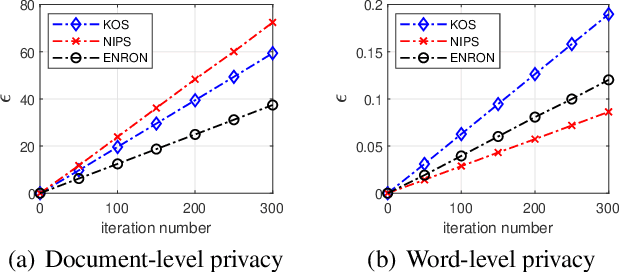
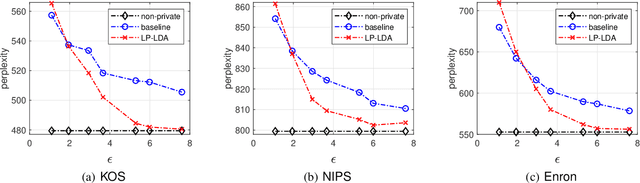
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for discovery of hidden semantic architecture of text datasets, and plays a fundamental role in many machine learning applications. However, like many other machine learning algorithms, the process of training a LDA model may leak the sensitive information of the training datasets and bring significant privacy risks. To mitigate the privacy issues in LDA, we focus on studying privacy-preserving algorithms of LDA model training in this paper. In particular, we first develop a privacy monitoring algorithm to investigate the privacy guarantee obtained from the inherent randomness of the Collapsed Gibbs Sampling (CGS) process in a typical LDA training algorithm on centralized curated datasets. Then, we further propose a locally private LDA training algorithm on crowdsourced data to provide local differential privacy for individual data contributors. The experimental results on real-world datasets demonstrate the effectiveness of our proposed algorithms.