 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Privacy Protection of Latent Dirichlet Allocation Model Training
Paper and Code
Jun 04, 2019
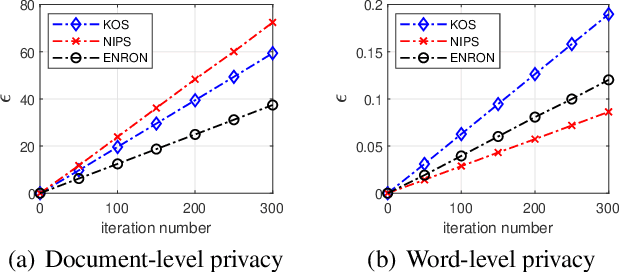
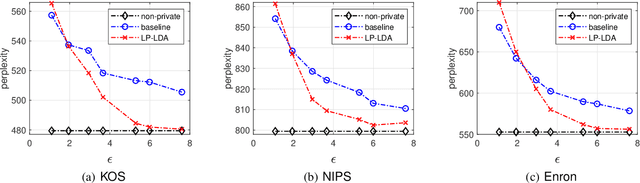
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for discovery of hidden semantic architecture of text datasets, and plays a fundamental role in many machine learning applications. However, like many other machine learning algorithms, the process of training a LDA model may leak the sensitive information of the training datasets and bring significant privacy risks. To mitigate the privacy issues in LDA, we focus on studying privacy-preserving algorithms of LDA model training in this paper. In particular, we first develop a privacy monitoring algorithm to investigate the privacy guarantee obtained from the inherent randomness of the Collapsed Gibbs Sampling (CGS) process in a typical LDA training algorithm on centralized curated datasets. Then, we further propose a locally private LDA training algorithm on crowdsourced data to provide local differential privacy for individual data contributors. The experimental results on real-world datasets demonstrate the effectiveness of our proposed algorithms.