 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLATO-K: Internal and External Knowledge Enhanced Dialogue Generation
Nov 02, 2022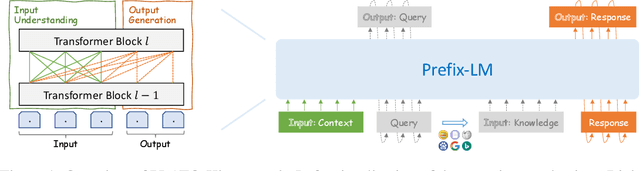
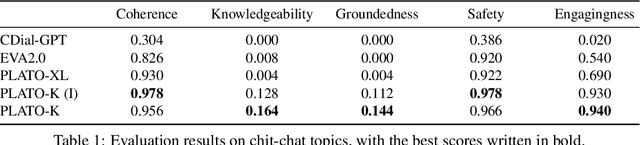

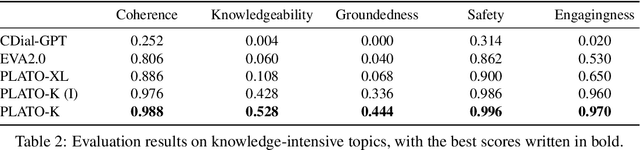
Recently, the practical deployment of open-domain dialogue systems has been plagued by the knowledge issue of information deficiency and factual inaccuracy. To this end, we introduce PLATO-K based on two-stage dialogic learning to strengthen internal knowledge memorization and external knowledge exploitation. In the first stage, PLATO-K learns through massive dialogue corpora and memorizes essential knowledge into model parameters. In the second stage, PLATO-K mimics human beings to search for external information and to leverage the knowledge in response generation. Extensive experiments reveal that the knowledge issue is alleviated significantly in PLATO-K with such comprehensive internal and external knowledge enhancement. Compared to the existing state-of-the-art Chinese dialogue model, the overall engagingness of PLATO-K is improved remarkably by 36.2% and 49.2% on chit-chat and knowledge-intensive conversations.
Towards Multi-Turn Empathetic Dialogs with Positive Emotion Elicitation
Apr 22, 2022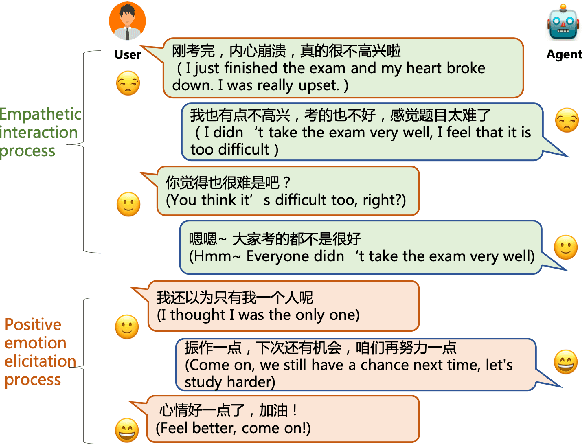

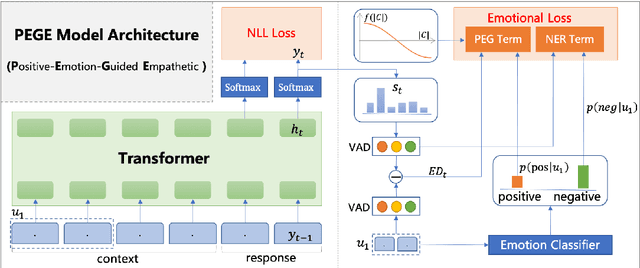
Emotional support is a crucial skill for many real-world scenarios, including caring for the elderly, mental health support, and customer service chats. This paper presents a novel task of empathetic dialog generation with positive emotion elicitation to promote users' positive emotions, similar to that of emotional support between humans. In this task, the agent conducts empathetic responses along with the target of eliciting the user's positive emotions in the multi-turn dialog. To facilitate the study of this task, we collect a large-scale emotional dialog dataset with positive emotion elicitation, called PosEmoDial (about 820k dialogs, 3M utterances). In these dialogs, the agent tries to guide the user from any possible initial emotional state, e.g., sadness, to a positive emotional state. Then we present a positive-emotion-guided dialog generation model with a novel loss function design. This loss function encourages the dialog model to not only elicit positive emotions from users but also ensure smooth emotional transitions along with the whole dialog. Finally, we establish benchmark results on PosEmoDial, and we will release this dataset and related source code to facilitate future studies.
Where to Go for the Holidays: Towards Mixed-Type Dialogs for Clarification of User Goals
Apr 15, 2022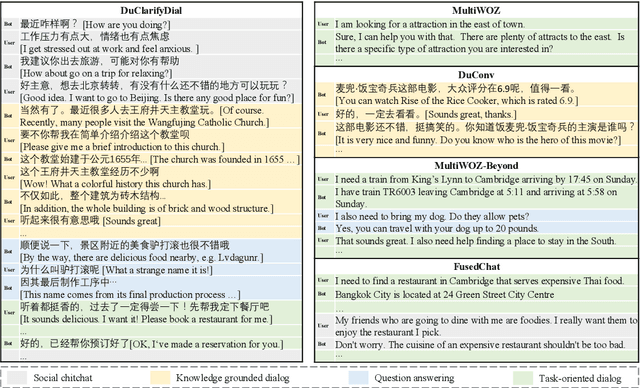

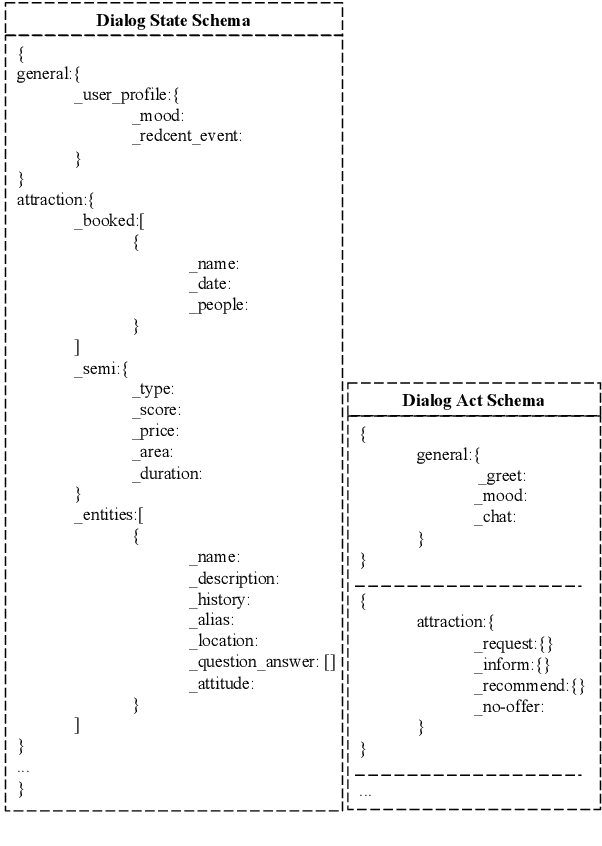
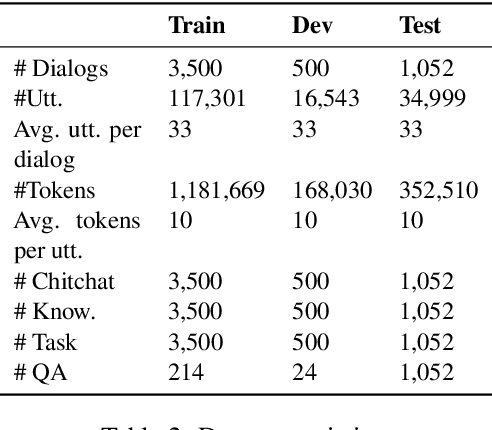
Most dialog systems posit that users have figured out clear and specific goals before starting an interaction. For example, users have determined the departure, the destination, and the travel time for booking a flight. However, in many scenarios, limited by experience and knowledge, users may know what they need, but still struggle to figure out clear and specific goals by determining all the necessary slots. In this paper, we identify this challenge and make a step forward by collecting a new human-to-human mixed-type dialog corpus. It contains 5k dialog sessions and 168k utterances for 4 dialog types and 5 domains. Within each session, an agent first provides user-goal-related knowledge to help figure out clear and specific goals, and then help achieve them. Furthermore, we propose a mixed-type dialog model with a novel Prompt-based continual learning mechanism. Specifically, the mechanism enables the model to continually strengthen its ability on any specific type by utilizing existing dialog corpora effectively.
Long Time No See! Open-Domain Conversation with Long-Term Persona Memory
Mar 14, 2022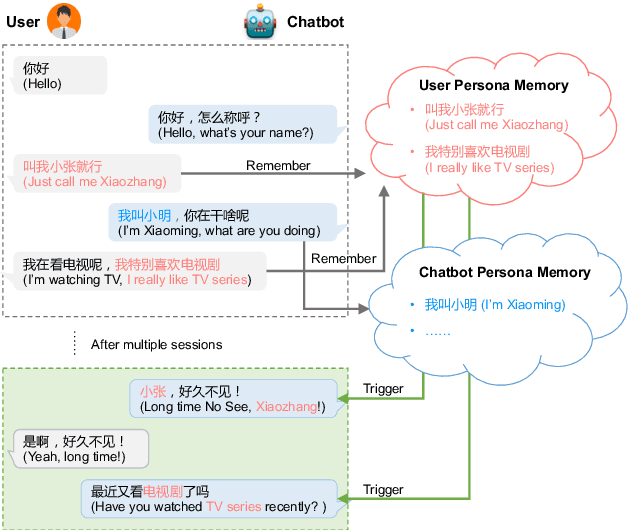
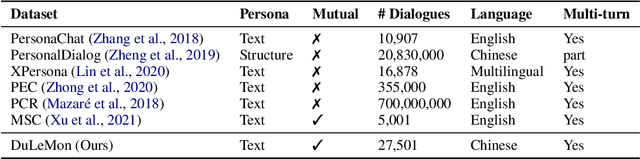
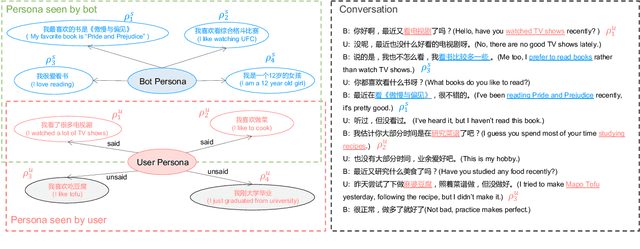
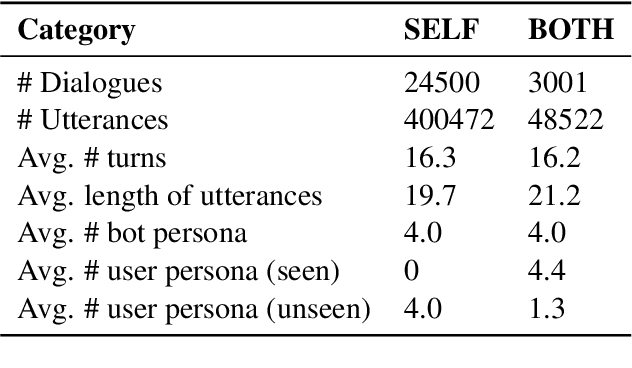
Most of the open-domain dialogue models tend to perform poorly in the setting of long-term human-bot conversations. The possible reason is that they lack the capability of understanding and memorizing long-term dialogue history information. To address this issue, we present a novel task of Long-term Memory Conversation (LeMon) and then build a new dialogue dataset DuLeMon and a dialogue generation framework with Long-Term Memory (LTM) mechanism (called PLATO-LTM). This LTM mechanism enables our system to accurately extract and continuously update long-term persona memory without requiring multiple-session dialogue datasets for model training. To our knowledge, this is the first attempt to conduct real-time dynamic management of persona information of both parties, including the user and the bot. Results on DuLeMon indicate that PLATO-LTM can significantly outperform baselines in terms of long-term dialogue consistency, leading to better dialogue engagingness.
DuRecDial 2.0: A Bilingual Parallel Corpus for Conversational Recommendation
Sep 18, 2021In this paper, we provide a bilingual parallel human-to-human recommendation dialog dataset (DuRecDial 2.0) to enable researchers to explore a challenging task of multilingual and cross-lingual conversational recommendation. The difference between DuRecDial 2.0 and existing conversational recommendation datasets is that the data item (Profile, Goal, Knowledge, Context, Response) in DuRecDial 2.0 is annotated in two languages, both English and Chinese, while other datasets are built with the setting of a single language. We collect 8.2k dialogs aligned across English and Chinese languages (16.5k dialogs and 255k utterances in total) that are annotated by crowdsourced workers with strict quality control procedure. We then build monolingual, multilingual, and cross-lingual conversational recommendation baselines on DuRecDial 2.0. Experiment results show that the use of additional English data can bring performance improvement for Chinese conversational recommendation, indicating the benefits of DuRecDial 2.0. Finally, this dataset provides a challenging testbed for future studies of monolingual, multilingual, and cross-lingual conversational recommendation.
Discovering Dialog Structure Graph for Open-Domain Dialog Generation
Dec 31, 2020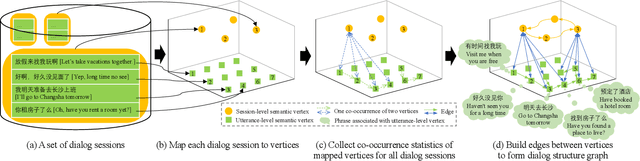
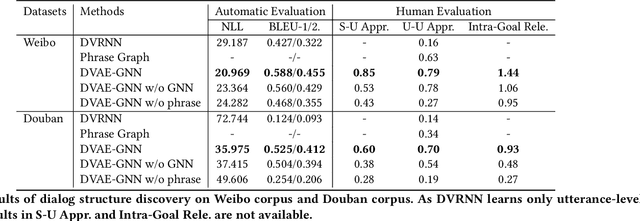
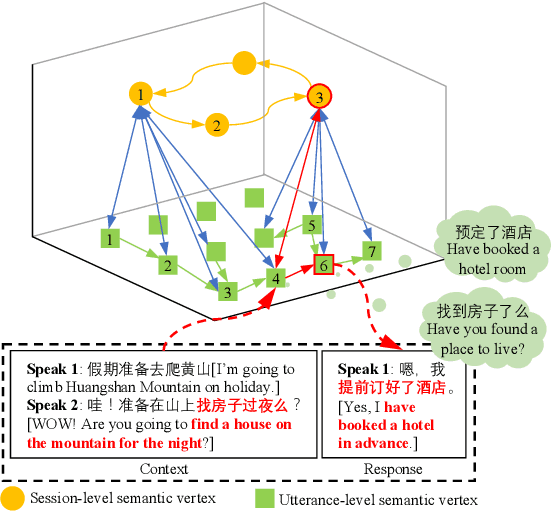
Learning interpretable dialog structure from human-human dialogs yields basic insights into the structure of conversation, and also provides background knowledge to facilitate dialog generation. In this paper, we conduct unsupervised discovery of dialog structure from chitchat corpora, and then leverage it to facilitate dialog generation in downstream systems. To this end, we present a Discrete Variational Auto-Encoder with Graph Neural Network (DVAE-GNN), to discover a unified human-readable dialog structure. The structure is a two-layer directed graph that contains session-level semantics in the upper-layer vertices, utterance-level semantics in the lower-layer vertices, and edges among these semantic vertices. In particular, we integrate GNN into DVAE to fine-tune utterance-level semantics for more effective recognition of session-level semantic vertex. Furthermore, to alleviate the difficulty of discovering a large number of utterance-level semantics, we design a coupling mechanism that binds each utterance-level semantic vertex with a distinct phrase to provide prior semantics. Experimental results on two benchmark corpora confirm that DVAE-GNN can discover meaningful dialog structure, and the use of dialog structure graph as background knowledge can facilitate a graph grounded conversational system to conduct coherent multi-turn dialog generation.
Towards Conversational Recommendation over Multi-Type Dialogs
May 22, 2020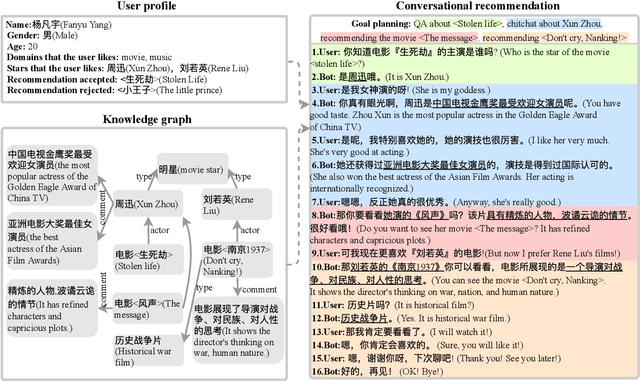
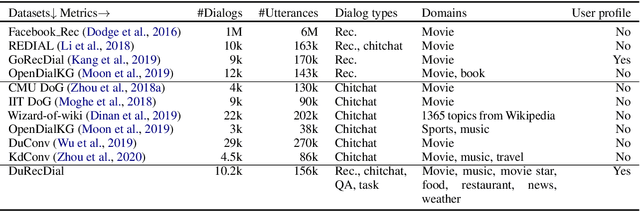
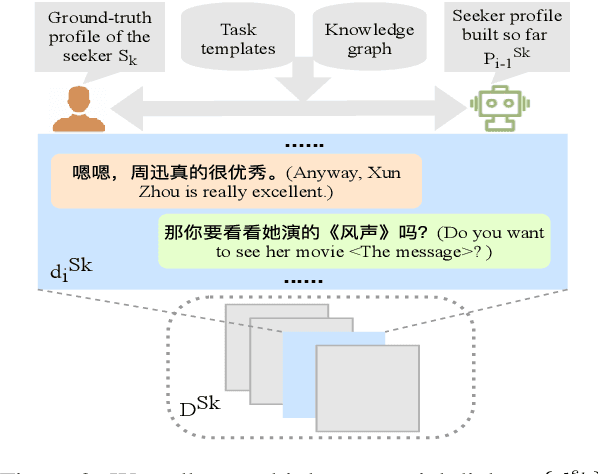

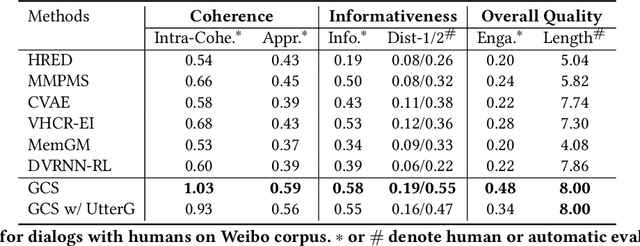
We propose a new task of conversational recommendation over multi-type dialogs, where the bots can proactively and naturally lead a conversation from a non-recommendation dialog (e.g., QA) to a recommendation dialog, taking into account user's interests and feedback. To facilitate the study of this task, we create a human-to-human Chinese dialog dataset \emph{DuRecDial} (about 10k dialogs, 156k utterances), which contains multiple sequential dialogs for every pair of a recommendation seeker (user) and a recommender (bot). In each dialog, the recommender proactively leads a multi-type dialog to approach recommendation targets and then makes multiple recommendations with rich interaction behavior. This dataset allows us to systematically investigate different parts of the overall problem, e.g., how to naturally lead a dialog, how to interact with users for recommendation. Finally we establish baseline results on DuRecDial for future studies. Dataset and codes are publicly available at https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/Research/ACL2020-DuRecDial.
Knowledge Aware Conversation Generation with Reasoning on Augmented Graph
Mar 25, 2019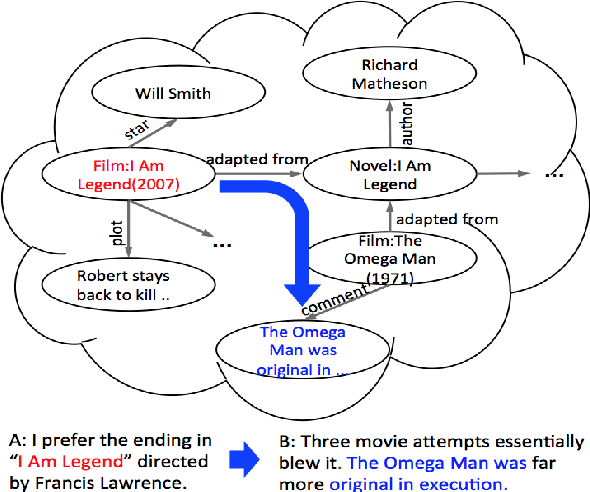
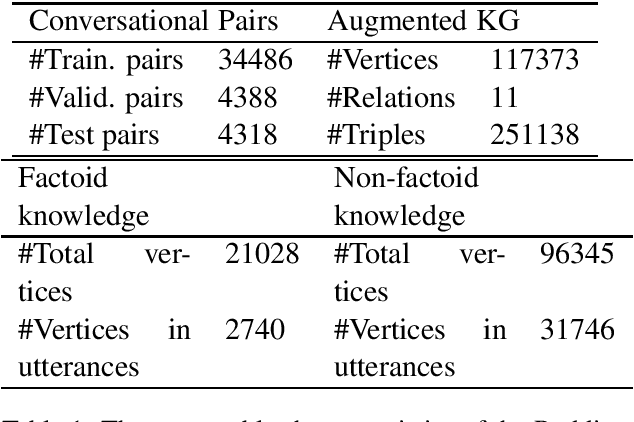
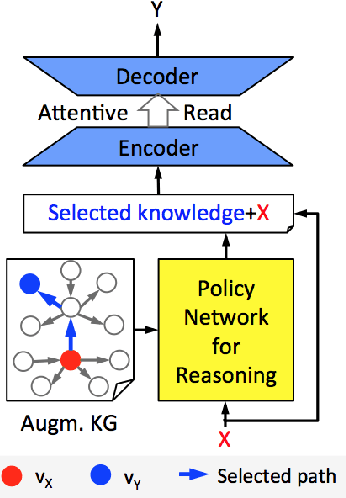
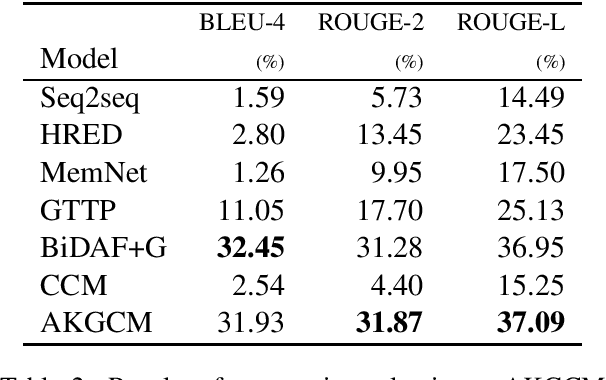
Two types of knowledge, factoid knowledge from graphs and non-factoid knowledge from unstructured documents, have been studied for knowledge aware open-domain conversation generation, in which edge information in graphs can help generalization of knowledge selectors, and text sentences of non-factoid knowledge can provide rich information for response generation. Fusion of knowledge triples and sentences might yield mutually reinforcing advantages for conversation generation, but there is less study on that. To address this challenge, we propose a knowledge aware chatting machine with three components, augmented knowledge graph containing both factoid and non-factoid knowledge, knowledge selector, and response generator. For knowledge selection on the graph, we formulate it as a problem of multi-hop graph reasoning that is more flexible in comparison with previous one-hop knowledge selection models. To fully leverage long text information that differentiates our graph from others, we improve a state of the art reasoning algorithm with machine reading comprehension technology. We demonstrate that supported by such unified knowledge and knowledge selection method, our system can generate more appropriate and informative responses than baselines.