 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
SINC: Service Information Augmented Open-Domain Conversation
Jun 28, 2022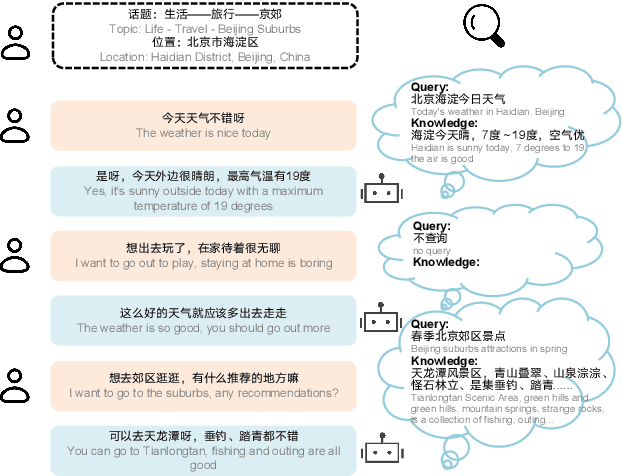
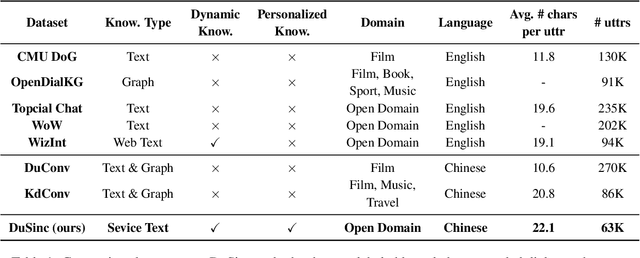
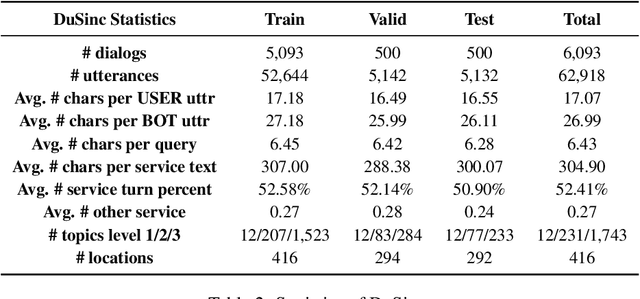
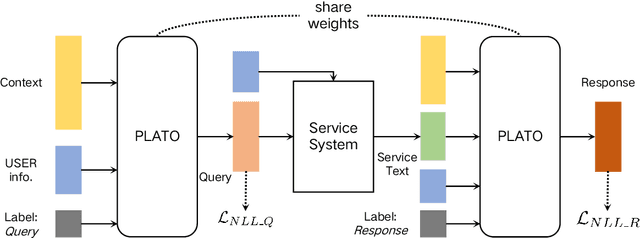
Generative open-domain dialogue systems can benefit from external knowledge, but the lack of external knowledge resources and the difficulty in finding relevant knowledge limit the development of this technology. To this end, we propose a knowledge-driven dialogue task using dynamic service information. Specifically, we use a large number of service APIs that can provide high coverage and spatiotemporal sensitivity as external knowledge sources. The dialogue system generates queries to request external services along with user information, get the relevant knowledge, and generate responses based on this knowledge. To implement this method, we collect and release the first open domain Chinese service knowledge dialogue dataset DuSinc. At the same time, we construct a baseline model PLATO-SINC, which realizes the automatic utilization of service information for dialogue. Both automatic evaluation and human evaluation show that our proposed new method can significantly improve the effect of open-domain conversation, and the session-level overall score in human evaluation is improved by 59.29% compared with the dialogue pre-training model PLATO-2. The dataset and benchmark model will be open sourced.
Towards Multi-Turn Empathetic Dialogs with Positive Emotion Elicitation
Apr 22, 2022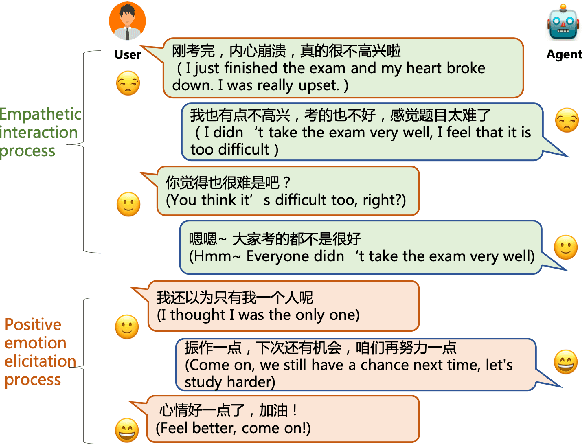

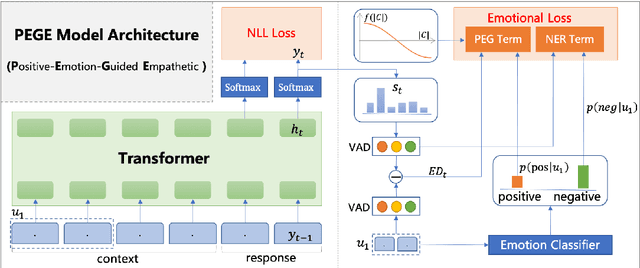
Emotional support is a crucial skill for many real-world scenarios, including caring for the elderly, mental health support, and customer service chats. This paper presents a novel task of empathetic dialog generation with positive emotion elicitation to promote users' positive emotions, similar to that of emotional support between humans. In this task, the agent conducts empathetic responses along with the target of eliciting the user's positive emotions in the multi-turn dialog. To facilitate the study of this task, we collect a large-scale emotional dialog dataset with positive emotion elicitation, called PosEmoDial (about 820k dialogs, 3M utterances). In these dialogs, the agent tries to guide the user from any possible initial emotional state, e.g., sadness, to a positive emotional state. Then we present a positive-emotion-guided dialog generation model with a novel loss function design. This loss function encourages the dialog model to not only elicit positive emotions from users but also ensure smooth emotional transitions along with the whole dialog. Finally, we establish benchmark results on PosEmoDial, and we will release this dataset and related source code to facilitate future studies.
Long Time No See! Open-Domain Conversation with Long-Term Persona Memory
Mar 14, 2022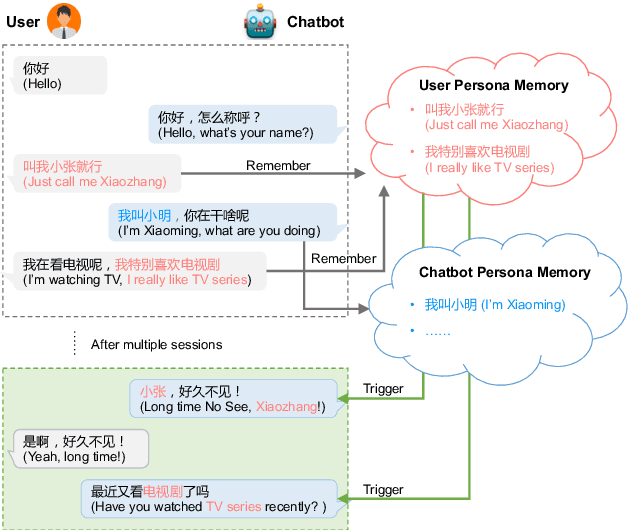
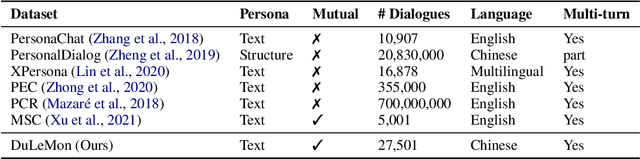
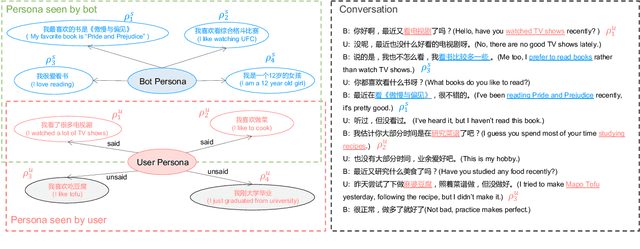
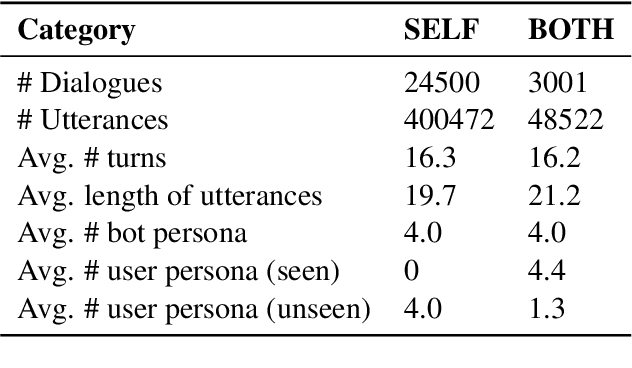
Most of the open-domain dialogue models tend to perform poorly in the setting of long-term human-bot conversations. The possible reason is that they lack the capability of understanding and memorizing long-term dialogue history information. To address this issue, we present a novel task of Long-term Memory Conversation (LeMon) and then build a new dialogue dataset DuLeMon and a dialogue generation framework with Long-Term Memory (LTM) mechanism (called PLATO-LTM). This LTM mechanism enables our system to accurately extract and continuously update long-term persona memory without requiring multiple-session dialogue datasets for model training. To our knowledge, this is the first attempt to conduct real-time dynamic management of persona information of both parties, including the user and the bot. Results on DuLeMon indicate that PLATO-LTM can significantly outperform baselines in terms of long-term dialogue consistency, leading to better dialogue engagingness.
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
Sep 20, 2021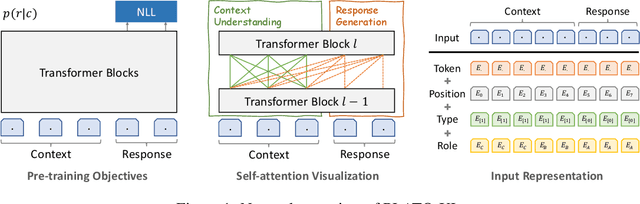
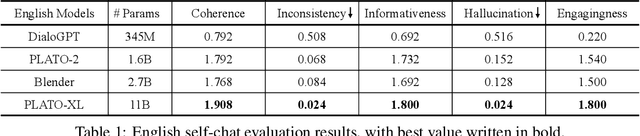

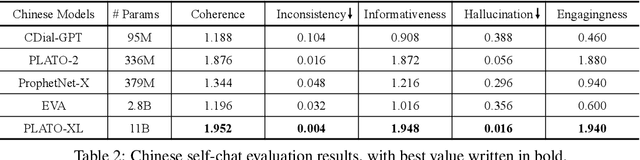
To explore the limit of dialogue generation pre-training, we present the models of PLATO-XL with up to 11 billion parameters, trained on both Chinese and English social media conversations. To train such large models, we adopt the architecture of unified transformer with high computation and parameter efficiency. In addition, we carry out multi-party aware pre-training to better distinguish the characteristic information in social media conversations. With such designs, PLATO-XL successfully achieves superior performances as compared to other approaches in both Chinese and English chitchat. We further explore the capacity of PLATO-XL on other conversational tasks, such as knowledge grounded dialogue and task-oriented conversation. The experimental results indicate that PLATO-XL obtains state-of-the-art results across multiple conversational tasks, verifying its potential as a foundation model of conversational AI.
PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning
Jul 13, 2020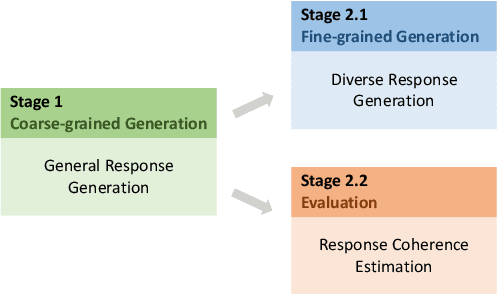
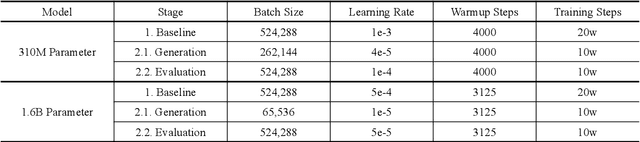
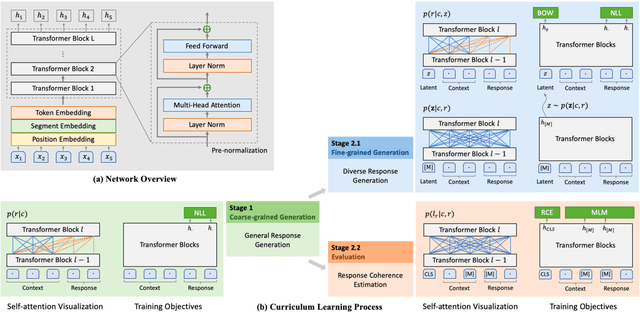

To build a high-quality open-domain chatbot, we introduce the effective training process of PLATO-2 via curriculum learning. There are two stages involved in the learning process. In the first stage, a coarse-grained generation model is trained to learn response generation under the simplified framework of one-to-one mapping. In the second stage, a fine-grained generation model and an evaluation model are further trained to learn diverse response generation and response coherence estimation, respectively. PLATO-2 was trained on both Chinese and English data, whose effectiveness and superiority are verified through comprehensive evaluations, achieving new state-of-the-art results.