 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-VDM: Learning Single-Image 3D Human Gaussian Splatting from Video Diffusion Models
Sep 04, 2024



Generating lifelike 3D humans from a single RGB image remains a challenging task in computer vision, as it requires accurate modeling of geometry, high-quality texture, and plausible unseen parts. Existing methods typically use multi-view diffusion models for 3D generation, but they often face inconsistent view issues, which hinder high-quality 3D human generation. To address this, we propose Human-VDM, a novel method for generating 3D human from a single RGB image using Video Diffusion Models. Human-VDM provides temporally consistent views for 3D human generation using Gaussian Splatting. It consists of three modules: a view-consistent human video diffusion module, a video augmentation module, and a Gaussian Splatting module. First, a single image is fed into a human video diffusion module to generate a coherent human video. Next, the video augmentation module applies super-resolution and video interpolation to enhance the textures and geometric smoothness of the generated video. Finally, the 3D Human Gaussian Splatting module learns lifelike humans under the guidance of these high-resolution and view-consistent images. Experiments demonstrate that Human-VDM achieves high-quality 3D human from a single image, outperforming state-of-the-art methods in both generation quality and quantity. Project page: https://human-vdm.github.io/Human-VDM/
Morphing median fin enhances untethered bionic robotic tuna's linear acceleration and turning maneuverability
Jul 26, 2024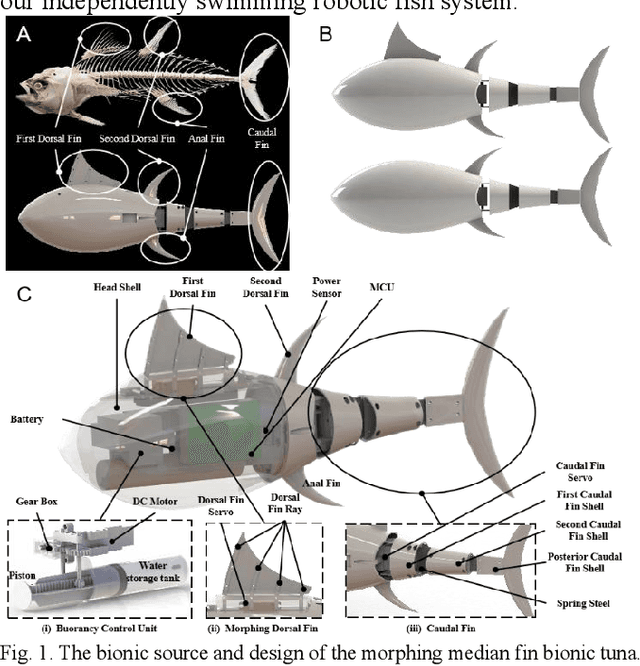
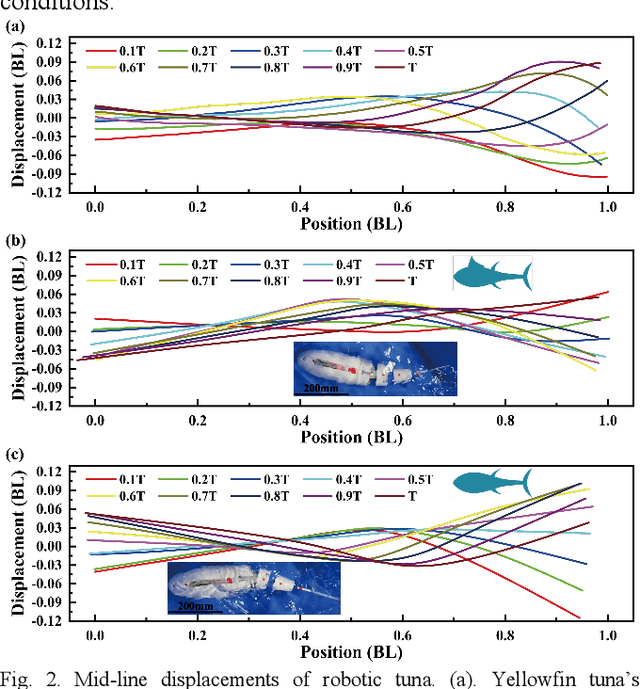
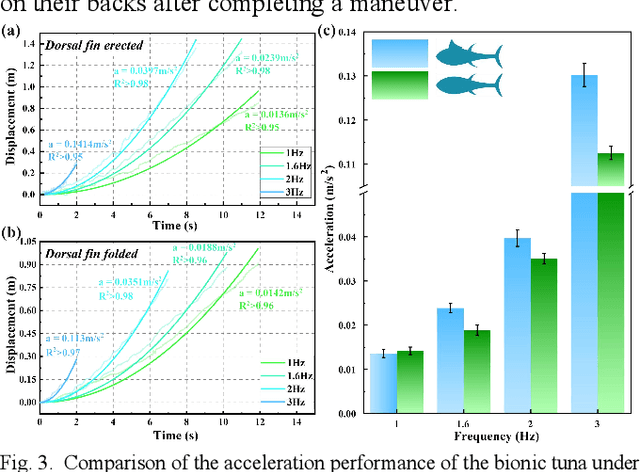
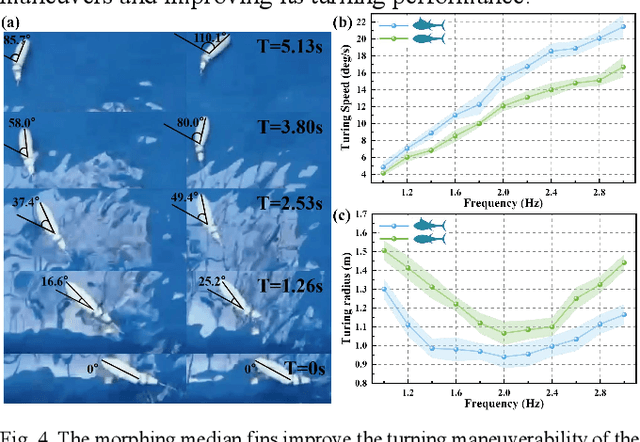
Median fins of fish-like swimmers play a crucial role in linear acceleration and maneuvering processes. However, few research focused on untethered robotic fish experiments. Imitating the behaviour of real tuna, we developed a free-swimming bionic tuna with a foldable dorsal fin. The erection of dorsal fin, at proper conditions, can reduce head heave by 50%, enhance linear acceleration by 15.7%, increase turning angular velocity by 32.78%, and turning radius decreasing by 33.13%. Conversely, erecting the dorsal fin increases the wetted surface area, resulting in decreased maximum speed and efficiency during steady swimming phase. This finding partially explains why tuna erect their median fins during maneuvers or acceleration and fold them afterward to reduce drag. In addition, we verified that folding the median fins after acceleration does not significantly affect locomotion efficiency. This study supports the application of morphing median fins in undulating underwater robots and helps to further understand the impact of median fins on fish locomotion.
Contrastive Transformer Learning with Proximity Data Generation for Text-Based Person Search
Nov 15, 2023



Given a descriptive text query, text-based person search (TBPS) aims to retrieve the best-matched target person from an image gallery. Such a cross-modal retrieval task is quite challenging due to significant modality gap, fine-grained differences and insufficiency of annotated data. To better align the two modalities, most existing works focus on introducing sophisticated network structures and auxiliary tasks, which are complex and hard to implement. In this paper, we propose a simple yet effective dual Transformer model for text-based person search. By exploiting a hardness-aware contrastive learning strategy, our model achieves state-of-the-art performance without any special design for local feature alignment or side information. Moreover, we propose a proximity data generation (PDG) module to automatically produce more diverse data for cross-modal training. The PDG module first introduces an automatic generation algorithm based on a text-to-image diffusion model, which generates new text-image pair samples in the proximity space of original ones. Then it combines approximate text generation and feature-level mixup during training to further strengthen the data diversity. The PDG module can largely guarantee the reasonability of the generated samples that are directly used for training without any human inspection for noise rejection. It improves the performance of our model significantly, providing a feasible solution to the data insufficiency problem faced by such fine-grained visual-linguistic tasks. Extensive experiments on two popular datasets of the TBPS task (i.e., CUHK-PEDES and ICFG-PEDES) show that the proposed approach outperforms state-of-the-art approaches evidently, e.g., improving by 3.88%, 4.02%, 2.92% in terms of Top1, Top5, Top10 on CUHK-PEDES. The codes will be available at https://github.com/HCPLab-SYSU/PersonSearch-CTLG
Multi-object Video Generation from Single Frame Layouts
May 06, 2023



In this paper, we study video synthesis with emphasis on simplifying the generation conditions. Most existing video synthesis models or datasets are designed to address complex motions of a single object, lacking the ability of comprehensively understanding the spatio-temporal relationships among multiple objects. Besides, current methods are usually conditioned on intricate annotations (e.g. video segmentations) to generate new videos, being fundamentally less practical. These motivate us to generate multi-object videos conditioning exclusively on object layouts from a single frame. To solve above challenges and inspired by recent research on image generation from layouts, we have proposed a novel video generative framework capable of synthesizing global scenes with local objects, via implicit neural representations and layout motion self-inference. Our framework is a non-trivial adaptation from image generation methods, and is new to this field. In addition, our model has been evaluated on two widely-used video recognition benchmarks, demonstrating effectiveness compared to the baseline model.
Joint Optimization of Deployment and Trajectory in UAV and IRS-Assisted IoT Data Collection System
Oct 27, 2022Unmanned aerial vehicles (UAVs) can be applied in many Internet of Things (IoT) systems, e.g., smart farms, as a data collection platform. However, the UAV-IoT wireless channels may be occasionally blocked by trees or high-rise buildings. An intelligent reflecting surface (IRS) can be applied to improve the wireless channel quality by smartly reflecting the signal via a large number of low-cost passive reflective elements. This article aims to minimize the energy consumption of the system by jointly optimizing the deployment and trajectory of the UAV. The problem is formulated as a mixed-integer-and-nonlinear programming (MINLP), which is challenging to address by the traditional solution, because the solution may easily fall into the local optimal. To address this issue, we propose a joint optimization framework of deployment and trajectory (JOLT), where an adaptive whale optimization algorithm (AWOA) is applied to optimize the deployment of the UAV, and an elastic ring self-organizing map (ERSOM) is introduced to optimize the trajectory of the UAV. Specifically, in AWOA, a variable-length population strategy is applied to find the optimal number of stop points, and a nonlinear parameter a and a partial mutation rule are introduced to balance the exploration and exploitation. In ERSOM, a competitive neural network is also introduced to learn the trajectory of the UAV by competitive learning, and a ring structure is presented to avoid the trajectory intersection. Extensive experiments are carried out to show the effectiveness of the proposed JOLT framework.
* 11 pages, 7 figures, 4 tables
PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning
Jul 13, 2020
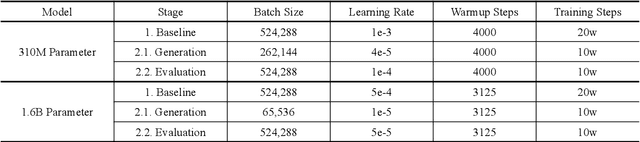
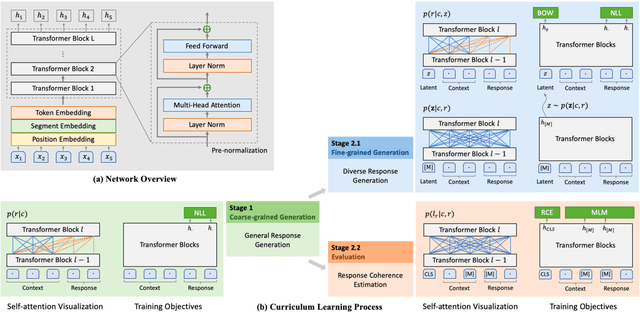

To build a high-quality open-domain chatbot, we introduce the effective training process of PLATO-2 via curriculum learning. There are two stages involved in the learning process. In the first stage, a coarse-grained generation model is trained to learn response generation under the simplified framework of one-to-one mapping. In the second stage, a fine-grained generation model and an evaluation model are further trained to learn diverse response generation and response coherence estimation, respectively. PLATO-2 was trained on both Chinese and English data, whose effectiveness and superiority are verified through comprehensive evaluations, achieving new state-of-the-art results.
Knowledge Aware Conversation Generation with Reasoning on Augmented Graph
Mar 25, 2019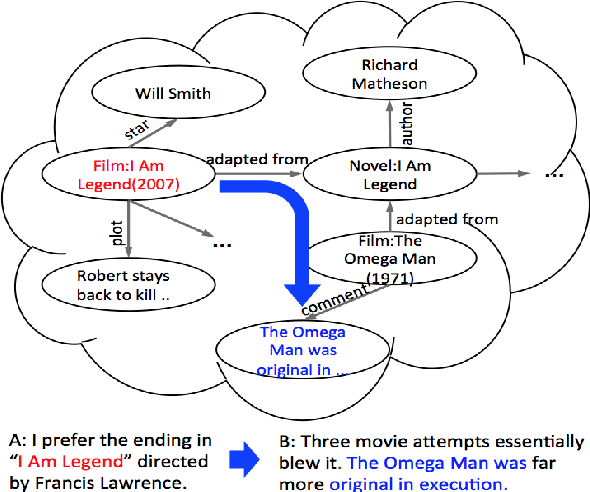
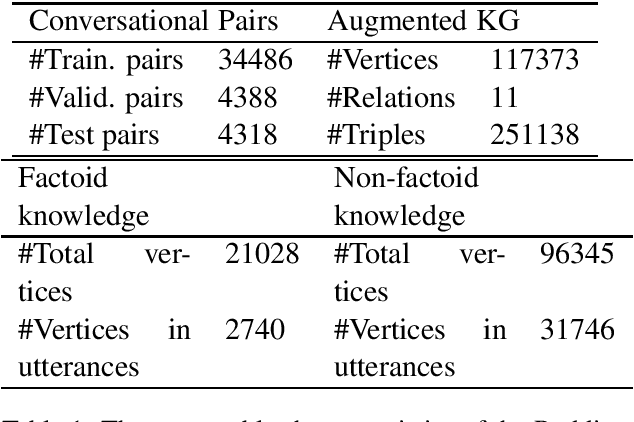
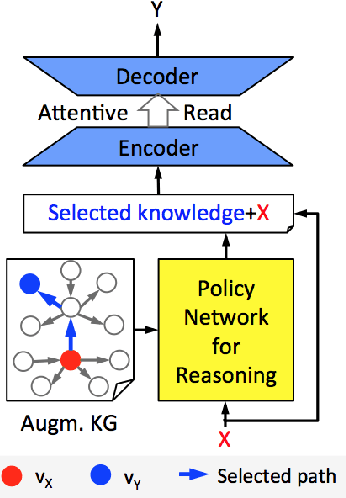
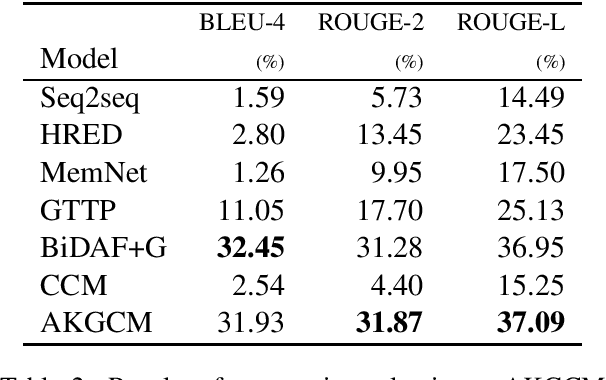
Two types of knowledge, factoid knowledge from graphs and non-factoid knowledge from unstructured documents, have been studied for knowledge aware open-domain conversation generation, in which edge information in graphs can help generalization of knowledge selectors, and text sentences of non-factoid knowledge can provide rich information for response generation. Fusion of knowledge triples and sentences might yield mutually reinforcing advantages for conversation generation, but there is less study on that. To address this challenge, we propose a knowledge aware chatting machine with three components, augmented knowledge graph containing both factoid and non-factoid knowledge, knowledge selector, and response generator. For knowledge selection on the graph, we formulate it as a problem of multi-hop graph reasoning that is more flexible in comparison with previous one-hop knowledge selection models. To fully leverage long text information that differentiates our graph from others, we improve a state of the art reasoning algorithm with machine reading comprehension technology. We demonstrate that supported by such unified knowledge and knowledge selection method, our system can generate more appropriate and informative responses than baselines.