 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecedent-Enhanced Legal Judgment Prediction with LLM and Domain-Model Collaboration
Oct 13, 2023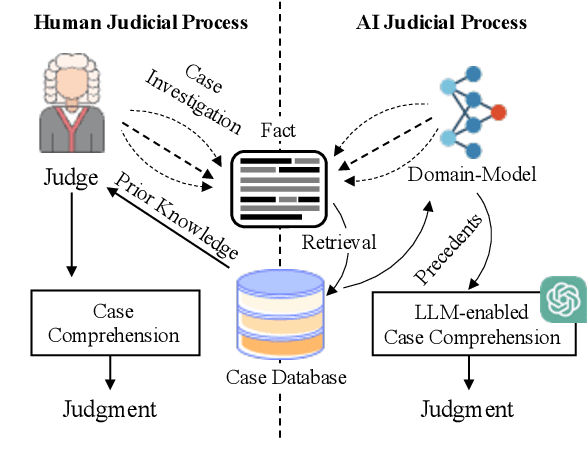
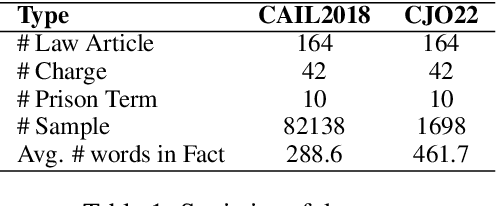
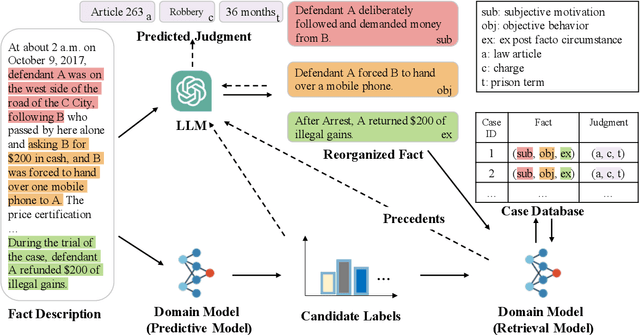
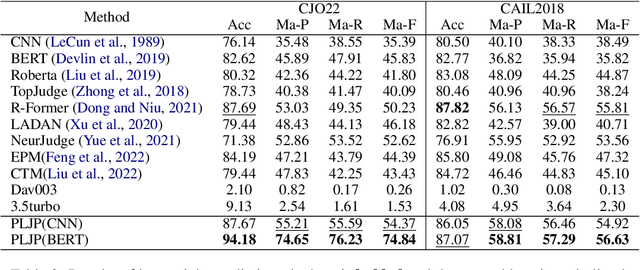
Legal Judgment Prediction (LJP) has become an increasingly crucial task in Legal AI, i.e., predicting the judgment of the case in terms of case fact description. Precedents are the previous legal cases with similar facts, which are the basis for the judgment of the subsequent case in national legal systems. Thus, it is worthwhile to explore the utilization of precedents in the LJP. Recent advances in deep learning have enabled a variety of techniques to be used to solve the LJP task. These can be broken down into two categories: large language models (LLMs) and domain-specific models. LLMs are capable of interpreting and generating complex natural language, while domain models are efficient in learning task-specific information. In this paper, we propose the precedent-enhanced LJP framework (PLJP), a system that leverages the strength of both LLM and domain models in the context of precedents. Specifically, the domain models are designed to provide candidate labels and find the proper precedents efficiently, and the large models will make the final prediction with an in-context precedents comprehension. Experiments on the real-world dataset demonstrate the effectiveness of our PLJP. Moreover, our work shows a promising direction for LLM and domain-model collaboration that can be generalized to other vertical domains.
Reformulating Domain Adaptation of Large Language Models as Adapt-Retrieve-Revise
Oct 12, 2023



While large language models (LLMs) like GPT-4 have recently demonstrated astonishing zero-shot capabilities in general domain tasks, they often generate content with hallucinations in specific domains such as Chinese law, hindering their application in these areas. This is typically due to the absence of training data that encompasses such a specific domain, preventing GPT-4 from acquiring in-domain knowledge. A pressing challenge is that it's not plausible to continue training LLMs of such scale on in-domain data. This paper introduces a simple and effective domain adaptation framework for GPT-4 by reformulating generation as an \textbf{adapt-retrieve-revise} process. The initial step is to \textbf{adapt} an affordable 7B LLM to the target domain by continuing learning on in-domain data. When solving a task, we leverage the adapted LLM to generate a draft answer given a task query. Then, the draft answer will be used to \textbf{retrieve} supporting evidence candidates from an external in-domain knowledge base. Finally, the draft answer and retrieved evidence are concatenated into a whole prompt to let GPT-4 assess the evidence and \textbf{revise} the draft answer to generate the final answer. Our proposal combines the advantages of the efficiency of adapting a smaller 7B model with the evidence-assessing capability of GPT-4 and effectively prevents GPT-4 from generating hallucinatory content. In the zero-shot setting of four Chinese legal tasks, our method improves accuracy by 33.3\% compared to the direct generation by GPT-4. When compared to two stronger retrieval-based baselines, our method outperforms them by 15.4\% and 23.9\%. Our code will be released
SAM-Deblur: Let Segment Anything Boost Image Deblurring
Sep 05, 2023Image deblurring is a critical task in the field of image restoration, aiming to eliminate blurring artifacts. However, the challenge of addressing non-uniform blurring leads to an ill-posed problem, which limits the generalization performance of existing deblurring models. To solve the problem, we propose a framework SAM-Deblur, integrating prior knowledge from the Segment Anything Model (SAM) into the deblurring task for the first time. In particular, SAM-Deblur is divided into three stages. First, We preprocess the blurred images, obtain image masks via SAM, and propose a mask dropout method for training to enhance model robustness. Then, to fully leverage the structural priors generated by SAM, we propose a Mask Average Pooling (MAP) unit specifically designed to average SAM-generated segmented areas, serving as a plug-and-play component which can be seamlessly integrated into existing deblurring networks. Finally, we feed the fused features generated by the MAP Unit into the deblurring model to obtain a sharp image. Experimental results on the RealBlurJ, ReloBlur, and REDS datasets reveal that incorporating our methods improves NAFNet's PSNR by 0.05, 0.96, and 7.03, respectively. Code will be available at \href{https://github.com/HPLQAQ/SAM-Deblur}{SAM-Deblur}.
PPN: Parallel Pointer-based Network for Key Information Extraction with Complex Layouts
Jul 20, 2023Key Information Extraction (KIE) is a challenging multimodal task that aims to extract structured value semantic entities from visually rich documents. Although significant progress has been made, there are still two major challenges that need to be addressed. Firstly, the layout of existing datasets is relatively fixed and limited in the number of semantic entity categories, creating a significant gap between these datasets and the complex real-world scenarios. Secondly, existing methods follow a two-stage pipeline strategy, which may lead to the error propagation problem. Additionally, they are difficult to apply in situations where unseen semantic entity categories emerge. To address the first challenge, we propose a new large-scale human-annotated dataset named Complex Layout form for key information EXtraction (CLEX), which consists of 5,860 images with 1,162 semantic entity categories. To solve the second challenge, we introduce Parallel Pointer-based Network (PPN), an end-to-end model that can be applied in zero-shot and few-shot scenarios. PPN leverages the implicit clues between semantic entities to assist extracting, and its parallel extraction mechanism allows it to extract multiple results simultaneously and efficiently. Experiments on the CLEX dataset demonstrate that PPN outperforms existing state-of-the-art methods while also offering a much faster inference speed.
Multidimensional Perceptron for Efficient and Explainable Long Text Classification
Apr 04, 2023Because of the inevitable cost and complexity of transformer and pre-trained models, efficiency concerns are raised for long text classification. Meanwhile, in the highly sensitive domains, e.g., healthcare and legal long-text mining, potential model distrust, yet underrated and underexplored, may hatch vital apprehension. Existing methods generally segment the long text, encode each piece with the pre-trained model, and use attention or RNNs to obtain long text representation for classification. In this work, we propose a simple but effective model, Segment-aWare multIdimensional PErceptron (SWIPE), to replace attention/RNNs in the above framework. Unlike prior efforts, SWIPE can effectively learn the label of the entire text with supervised training, while perceive the labels of the segments and estimate their contributions to the long-text labeling in an unsupervised manner. As a general classifier, SWIPE can endorse different encoders, and it outperforms SOTA models in terms of classification accuracy and model efficiency. It is noteworthy that SWIPE achieves superior interpretability to transparentize long text classification results.
Dialogue Inspectional Summarization with Factual Inconsistency Awareness
Nov 05, 2021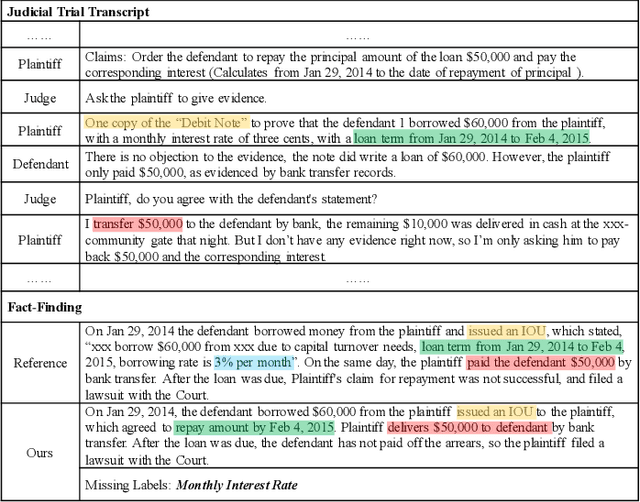
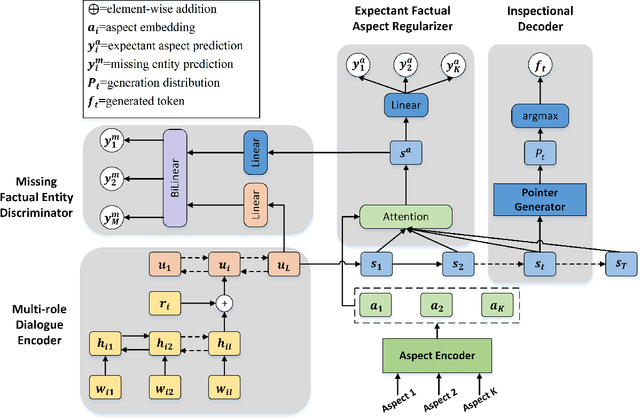
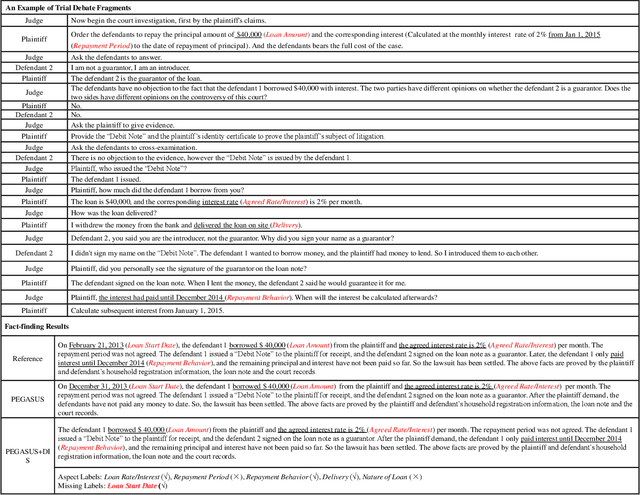
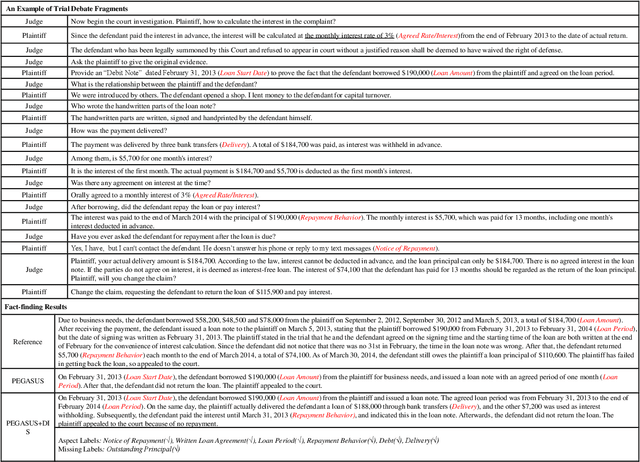
Dialogue summarization has been extensively studied and applied, where the prior works mainly focused on exploring superior model structures to align the input dialogue and the output summary. However, for professional dialogues (e.g., legal debate and medical diagnosis), semantic/statistical alignment can hardly fill the logical/factual gap between input dialogue discourse and summary output with external knowledge. In this paper, we mainly investigate the factual inconsistency problem for Dialogue Inspectional Summarization (DIS) under non-pretraining and pretraining settings. An innovative end-to-end dialogue summary generation framework is proposed with two auxiliary tasks: Expectant Factual Aspect Regularization (EFAR) and Missing Factual Entity Discrimination (MFED). Comprehensive experiments demonstrate that the proposed model can generate a more readable summary with accurate coverage of factual aspects as well as informing the user with potential missing facts detected from the input dialogue for further human intervention.
A Neural Conversation Generation Model via Equivalent Shared Memory Investigation
Aug 20, 2021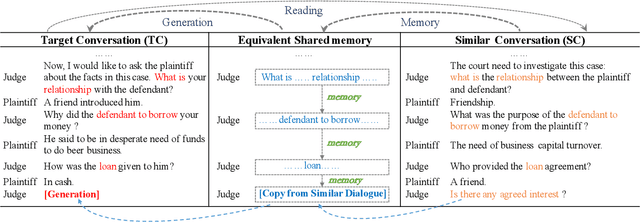
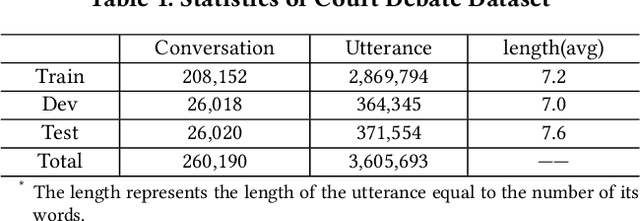
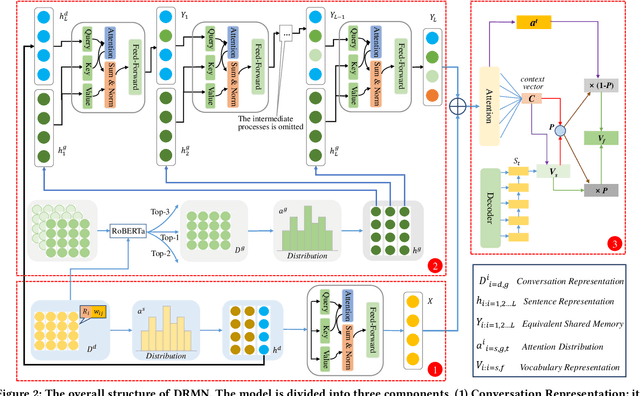
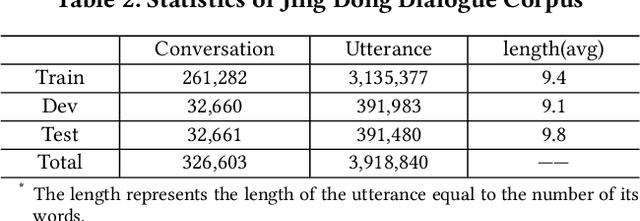
Conversation generation as a challenging task in Natural Language Generation (NLG) has been increasingly attracting attention over the last years. A number of recent works adopted sequence-to-sequence structures along with external knowledge, which successfully enhanced the quality of generated conversations. Nevertheless, few works utilized the knowledge extracted from similar conversations for utterance generation. Taking conversations in customer service and court debate domains as examples, it is evident that essential entities/phrases, as well as their associated logic and inter-relationships can be extracted and borrowed from similar conversation instances. Such information could provide useful signals for improving conversation generation. In this paper, we propose a novel reading and memory framework called Deep Reading Memory Network (DRMN) which is capable of remembering useful information of similar conversations for improving utterance generation. We apply our model to two large-scale conversation datasets of justice and e-commerce fields. Experiments prove that the proposed model outperforms the state-of-the-art approaches.
Legal Judgment Prediction with Multi-Stage CaseRepresentation Learning in the Real Court Setting
Jul 12, 2021

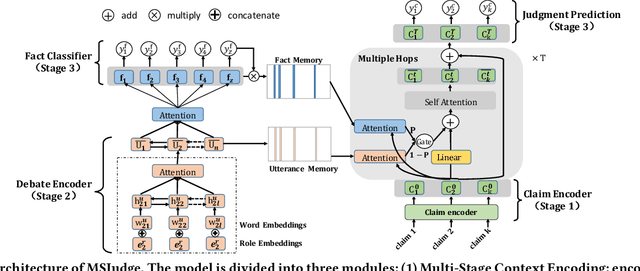

Legal judgment prediction(LJP) is an essential task for legal AI. While prior methods studied on this topic in a pseudo setting by employing the judge-summarized case narrative as the input to predict the judgment, neglecting critical case life-cycle information in real court setting could threaten the case logic representation quality and prediction correctness. In this paper, we introduce a novel challenging dataset from real courtrooms to predict the legal judgment in a reasonably encyclopedic manner by leveraging the genuine input of the case -- plaintiff's claims and court debate data, from which the case's facts are automatically recognized by comprehensively understanding the multi-role dialogues of the court debate, and then learnt to discriminate the claims so as to reach the final judgment through multi-task learning. An extensive set of experiments with a large civil trial data set shows that the proposed model can more accurately characterize the interactions among claims, fact and debate for legal judgment prediction, achieving significant improvements over strong state-of-the-art baselines. Moreover, the user study conducted with real judges and law school students shows the neural predictions can also be interpretable and easily observed, and thus enhancing the trial efficiency and judgment quality.
Cross Copy Network for Dialogue Generation
Oct 22, 2020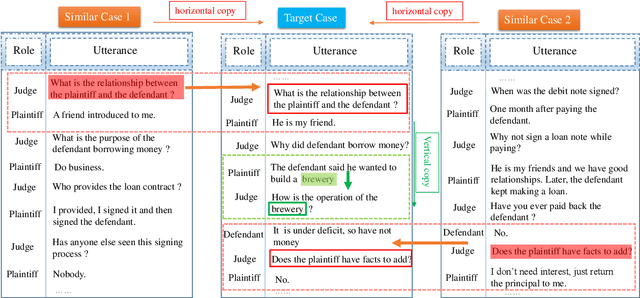
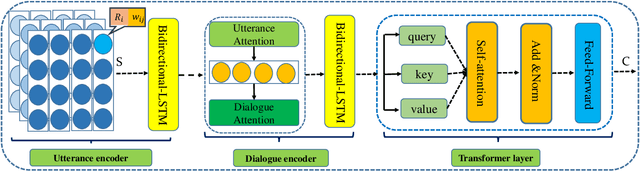
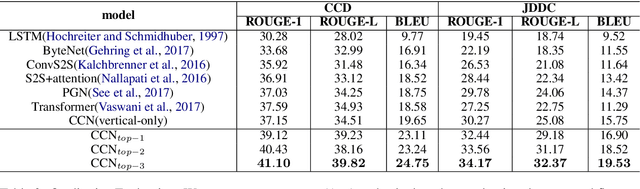
In the past few years, audiences from different fields witness the achievements of sequence-to-sequence models (e.g., LSTM+attention, Pointer Generator Networks, and Transformer) to enhance dialogue content generation. While content fluency and accuracy often serve as the major indicators for model training, dialogue logics, carrying critical information for some particular domains, are often ignored. Take customer service and court debate dialogue as examples, compatible logics can be observed across different dialogue instances, and this information can provide vital evidence for utterance generation. In this paper, we propose a novel network architecture - Cross Copy Networks(CCN) to explore the current dialog context and similar dialogue instances' logical structure simultaneously. Experiments with two tasks, court debate and customer service content generation, proved that the proposed algorithm is superior to existing state-of-art content generation models.
Masking Orchestration: Multi-task Pretraining for Multi-role Dialogue Representation Learning
Feb 27, 2020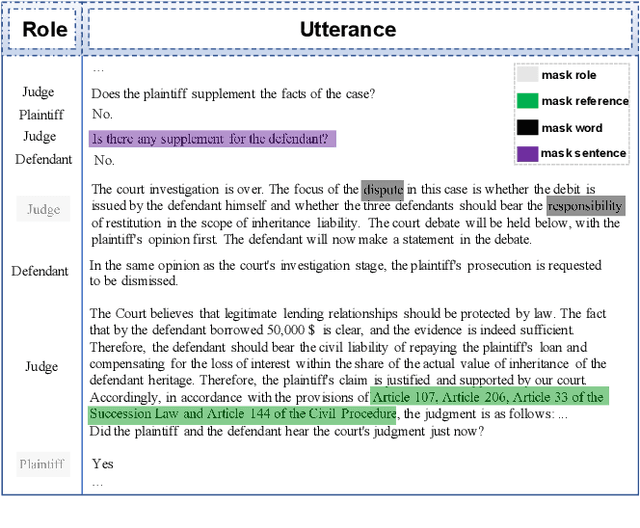

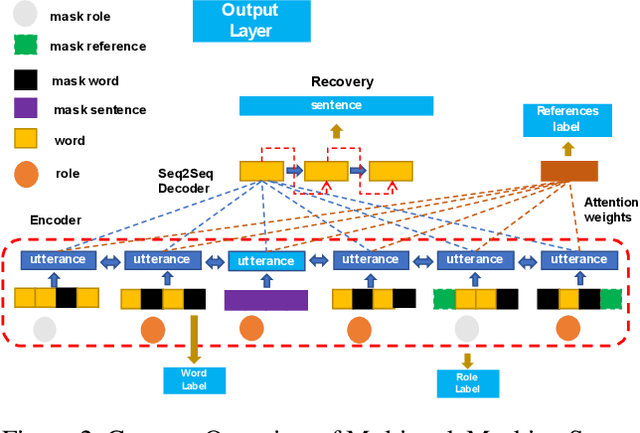

Multi-role dialogue understanding comprises a wide range of diverse tasks such as question answering, act classification, dialogue summarization etc. While dialogue corpora are abundantly available, labeled data, for specific learning tasks, can be highly scarce and expensive. In this work, we investigate dialogue context representation learning with various types unsupervised pretraining tasks where the training objectives are given naturally according to the nature of the utterance and the structure of the multi-role conversation. Meanwhile, in order to locate essential information for dialogue summarization/extraction, the pretraining process enables external knowledge integration. The proposed fine-tuned pretraining mechanism is comprehensively evaluated via three different dialogue datasets along with a number of downstream dialogue-mining tasks. Result shows that the proposed pretraining mechanism significantly contributes to all the downstream tasks without discrimination to different encoders.