 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCO: Distributed Inference with Sparse Communications
Feb 22, 2023Deep neural networks (DNNs) have great potential to solve many real-world problems, but they usually require an extensive amount of computation and memory. It is of great difficulty to deploy a large DNN model to a single resource-limited device with small memory capacity. Distributed computing is a common approach to reduce single-node memory consumption and to accelerate the inference of DNN models. In this paper, we explore the "within-layer model parallelism", which distributes the inference of each layer into multiple nodes. In this way, the memory requirement can be distributed to many nodes, making it possible to use several edge devices to infer a large DNN model. Due to the dependency within each layer, data communications between nodes during this parallel inference can be a bottleneck when the communication bandwidth is limited. We propose a framework to train DNN models for Distributed Inference with Sparse Communications (DISCO). We convert the problem of selecting which subset of data to transmit between nodes into a model optimization problem, and derive models with both computation and communication reduction when each layer is inferred on multiple nodes. We show the benefit of the DISCO framework on a variety of CV tasks such as image classification, object detection, semantic segmentation, and image super resolution. The corresponding models include important DNN building blocks such as convolutions and transformers. For example, each layer of a ResNet-50 model can be distributively inferred across two nodes with five times less data communications, almost half overall computations and half memory requirement for a single node, and achieve comparable accuracy to the original ResNet-50 model. This also results in 4.7 times overall inference speedup.
Noisy Computations during Inference: Harmful or Helpful?
Nov 26, 2018


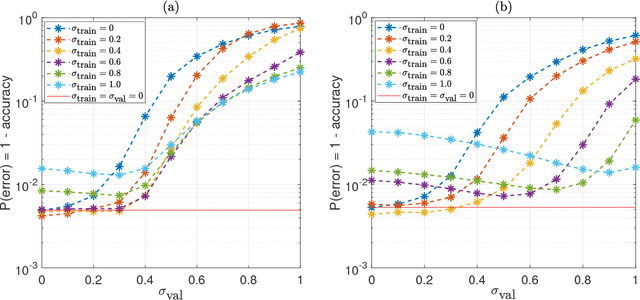
We study two aspects of noisy computations during inference. The first aspect is how to mitigate their side effects for naturally trained deep learning systems. One of the motivations for looking into this problem is to reduce the high power cost of conventional computing of neural networks through the use of analog neuromorphic circuits. Traditional GPU/CPU-centered deep learning architectures exhibit bottlenecks in power-restricted applications (e.g., embedded systems). The use of specialized neuromorphic circuits, where analog signals passed through memory-cell arrays are sensed to accomplish matrix-vector multiplications, promises large power savings and speed gains but brings with it the problems of limited precision of computations and unavoidable analog noise. We manage to improve inference accuracy from 21.1% to 99.5% for MNIST images, from 29.9% to 89.1% for CIFAR10, and from 15.5% to 89.6% for MNIST stroke sequences with the presence of strong noise (with signal-to-noise power ratio being 0 dB) by noise-injected training and a voting method. This observation promises neural networks that are insensitive to inference noise, which reduces the quality requirements on neuromorphic circuits and is crucial for their practical usage. The second aspect is how to utilize the noisy inference as a defensive architecture against black-box adversarial attacks. During inference, by injecting proper noise to signals in the neural networks, the robustness of adversarially-trained neural networks against black-box attacks has been further enhanced by 0.5% and 1.13% for two adversarially trained models for MNIST and CIFAR10, respectively.
Training Recurrent Neural Networks against Noisy Computations during Inference
Jul 17, 2018
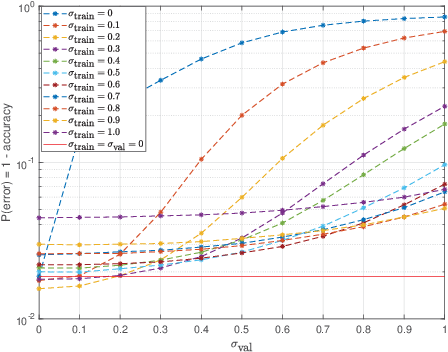

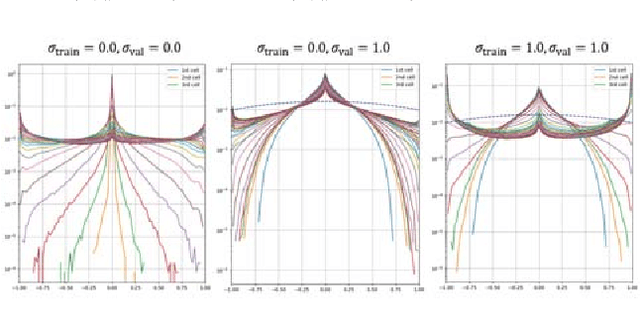
We explore the robustness of recurrent neural networks when the computations within the network are noisy. One of the motivations for looking into this problem is to reduce the high power cost of conventional computing of neural network operations through the use of analog neuromorphic circuits. Traditional GPU/CPU-centered deep learning architectures exhibit bottlenecks in power-restricted applications, such as speech recognition in embedded systems. The use of specialized neuromorphic circuits, where analog signals passed through memory-cell arrays are sensed to accomplish matrix-vector multiplications, promises large power savings and speed gains but brings with it the problems of limited precision of computations and unavoidable analog noise. In this paper we propose a method, called {\em Deep Noise Injection training}, to train RNNs to obtain a set of weights/biases that is much more robust against noisy computation during inference. We explore several RNN architectures, such as vanilla RNN and long-short-term memories (LSTM), and show that after convergence of Deep Noise Injection training the set of trained weights/biases has more consistent performance over a wide range of noise powers entering the network during inference. Surprisingly, we find that Deep Noise Injection training improves overall performance of some networks even for numerically accurate inference.