 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompensation-free Machine Unlearning in Text-to-Image Diffusion Models by Eliminating the Mutual Information
Mar 01, 2026The powerful generative capabilities of diffusion models have raised growing privacy and safety concerns regarding generating sensitive or undesired content. In response, machine unlearning (MU) -- commonly referred to as concept erasure (CE) in diffusion models -- has been introduced to remove specific knowledge from model parameters meanwhile preserving innocent knowledge. Despite recent advancements, existing unlearning methods often suffer from excessive and indiscriminate removal, which leads to substantial degradation in the quality of innocent generations. To preserve model utility, prior works rely on compensation, i.e., re-assimilating a subset of the remaining data or explicitly constraining the divergence from the pre-trained model on remaining concepts. However, we reveal that generations beyond the compensation scope still suffer, suggesting such post-remedial compensations are inherently insufficient for preserving the general utility of large-scale generative models. Therefore, in this paper, we advocate for developing compensation-free concept erasure operations, which precisely identify and eliminate the undesired knowledge such that the impact on other generations is minimal. In technique, we propose to MiM-MU, which is to unlearn a concept by minimizing the mutual information with a delicate design for computational effectiveness and for maintaining sampling distribution for other concepts. Extensive evaluations demonstrate that our proposed method achieves effective concept removal meanwhile maintaining high-quality generations for other concepts, and remarkably, without relying on any post-remedial compensation for the first time.
RAIN-Merging: A Gradient-Free Method to Enhance Instruction Following in Large Reasoning Models with Preserved Thinking Format
Feb 26, 2026Large reasoning models (LRMs) excel at a long chain of reasoning but often fail to faithfully follow instructions regarding output format, constraints, or specific requirements. We investigate whether this gap can be closed by integrating an instruction-tuned model (ITM) into an LRM. Analyzing their differences in parameter space, namely task vectors, we find that their principal subspaces are nearly orthogonal across key modules, suggesting a lightweight merging with minimal interference. However, we also demonstrate that naive merges are fragile because they overlook the output format mismatch between LRMs (with explicit thinking and response segments) and ITMs (answers-only). We introduce RAIN-Merging (Reasoning-Aware Instruction-attention guided Null-space projection Merging), a gradient-free method that integrates instruction following while preserving thinking format and reasoning performance. First, with a small reasoning calibration set, we project the ITM task vector onto the null space of forward features at thinking special tokens, which preserves the LRM's structured reasoning mechanisms. Second, using a small instruction calibration set, we estimate instruction attention to derive module-specific scaling that amplifies instruction-relevant components and suppresses leakage. Across four instruction-following benchmarks and nine reasoning & general capability benchmarks, RAIN-Merging substantially improves instruction adherence while maintaining reasoning quality. The gains are consistent across model scales and architectures, translating to improved performance in agent settings.
VL-RouterBench: A Benchmark for Vision-Language Model Routing
Dec 29, 2025Multi-model routing has evolved from an engineering technique into essential infrastructure, yet existing work lacks a systematic, reproducible benchmark for evaluating vision-language models (VLMs). We present VL-RouterBench to assess the overall capability of VLM routing systems systematically. The benchmark is grounded in raw inference and scoring logs from VLMs and constructs quality and cost matrices over sample-model pairs. In scale, VL-RouterBench covers 14 datasets across 3 task groups, totaling 30,540 samples, and includes 15 open-source models and 2 API models, yielding 519,180 sample-model pairs and a total input-output token volume of 34,494,977. The evaluation protocol jointly measures average accuracy, average cost, and throughput, and builds a ranking score from the harmonic mean of normalized cost and accuracy to enable comparison across router configurations and cost budgets. On this benchmark, we evaluate 10 routing methods and baselines and observe a significant routability gain, while the best current routers still show a clear gap to the ideal Oracle, indicating considerable room for improvement in router architecture through finer visual cues and modeling of textual structure. We will open-source the complete data construction and evaluation toolchain to promote comparability, reproducibility, and practical deployment in multimodal routing research.
Bi-LoRA: Efficient Sharpness-Aware Minimization for Fine-Tuning Large-Scale Models
Aug 27, 2025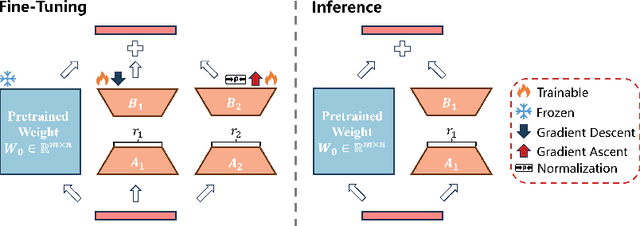


Fine-tuning large-scale pre-trained models with limited data presents significant challenges for generalization. While Sharpness-Aware Minimization (SAM) has proven effective in improving generalization by seeking flat minima, its substantial extra memory and computation overhead make it impractical for large models. Integrating SAM with parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA) is a promising direction. However, we find that directly applying SAM to LoRA parameters limits the sharpness optimization to a restricted subspace, hindering its effectiveness. To address this limitation, we propose Bi-directional Low-Rank Adaptation (Bi-LoRA), which introduces an auxiliary LoRA module to model SAM's adversarial weight perturbations. It decouples SAM's weight perturbations from LoRA optimization: the primary LoRA module adapts to specific tasks via standard gradient descent, while the auxiliary module captures the sharpness of the loss landscape through gradient ascent. Such dual-module design enables Bi-LoRA to capture broader sharpness for achieving flatter minima while remaining memory-efficient. Another important benefit is that the dual design allows for simultaneous optimization and perturbation, eliminating SAM's doubled training costs. Extensive experiments across diverse tasks and architectures demonstrate Bi-LoRA's efficiency and effectiveness in enhancing generalization.
T2I-ConBench: Text-to-Image Benchmark for Continual Post-training
May 22, 2025Continual post-training adapts a single text-to-image diffusion model to learn new tasks without incurring the cost of separate models, but naive post-training causes forgetting of pretrained knowledge and undermines zero-shot compositionality. We observe that the absence of a standardized evaluation protocol hampers related research for continual post-training. To address this, we introduce T2I-ConBench, a unified benchmark for continual post-training of text-to-image models. T2I-ConBench focuses on two practical scenarios, item customization and domain enhancement, and analyzes four dimensions: (1) retention of generality, (2) target-task performance, (3) catastrophic forgetting, and (4) cross-task generalization. It combines automated metrics, human-preference modeling, and vision-language QA for comprehensive assessment. We benchmark ten representative methods across three realistic task sequences and find that no approach excels on all fronts. Even joint "oracle" training does not succeed for every task, and cross-task generalization remains unsolved. We release all datasets, code, and evaluation tools to accelerate research in continual post-training for text-to-image models.
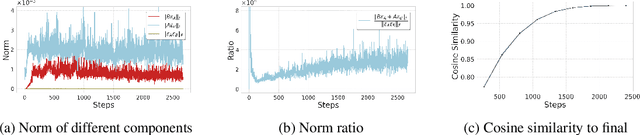
A Unified Gradient-based Framework for Task-agnostic Continual Learning-Unlearning
May 21, 2025Recent advancements in deep models have highlighted the need for intelligent systems that combine continual learning (CL) for knowledge acquisition with machine unlearning (MU) for data removal, forming the Continual Learning-Unlearning (CLU) paradigm. While existing work treats CL and MU as separate processes, we reveal their intrinsic connection through a unified optimization framework based on Kullback-Leibler divergence minimization. This framework decomposes gradient updates for approximate CLU into four components: learning new knowledge, unlearning targeted data, preserving existing knowledge, and modulation via weight saliency. A critical challenge lies in balancing knowledge update and retention during sequential learning-unlearning cycles. To resolve this stability-plasticity dilemma, we introduce a remain-preserved manifold constraint to induce a remaining Hessian compensation for CLU iterations. A fast-slow weight adaptation mechanism is designed to efficiently approximate the second-order optimization direction, combined with adaptive weighting coefficients and a balanced weight saliency mask, proposing a unified implementation framework for gradient-based CLU. Furthermore, we pioneer task-agnostic CLU scenarios that support fine-grained unlearning at the cross-task category and random sample levels beyond the traditional task-aware setups. Experiments demonstrate that the proposed UG-CLU framework effectively coordinates incremental learning, precise unlearning, and knowledge stability across multiple datasets and model architectures, providing a theoretical foundation and methodological support for dynamic, compliant intelligent systems.
Unified Gradient-Based Machine Unlearning with Remain Geometry Enhancement
Sep 29, 2024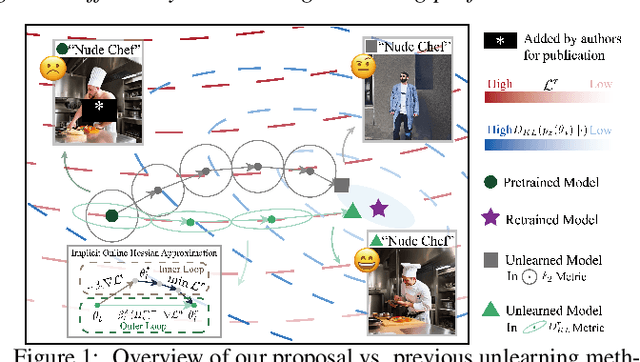



Machine unlearning (MU) has emerged to enhance the privacy and trustworthiness of deep neural networks. Approximate MU is a practical method for large-scale models. Our investigation into approximate MU starts with identifying the steepest descent direction, minimizing the output Kullback-Leibler divergence to exact MU inside a parameters' neighborhood. This probed direction decomposes into three components: weighted forgetting gradient ascent, fine-tuning retaining gradient descent, and a weight saliency matrix. Such decomposition derived from Euclidean metric encompasses most existing gradient-based MU methods. Nevertheless, adhering to Euclidean space may result in sub-optimal iterative trajectories due to the overlooked geometric structure of the output probability space. We suggest embedding the unlearning update into a manifold rendered by the remaining geometry, incorporating second-order Hessian from the remaining data. It helps prevent effective unlearning from interfering with the retained performance. However, computing the second-order Hessian for large-scale models is intractable. To efficiently leverage the benefits of Hessian modulation, we propose a fast-slow parameter update strategy to implicitly approximate the up-to-date salient unlearning direction. Free from specific modal constraints, our approach is adaptable across computer vision unlearning tasks, including classification and generation. Extensive experiments validate our efficacy and efficiency. Notably, our method successfully performs class-forgetting on ImageNet using DiT and forgets a class on CIFAR-10 using DDPM in just 50 steps, compared to thousands of steps required by previous methods.
Towards Natural Machine Unlearning
May 24, 2024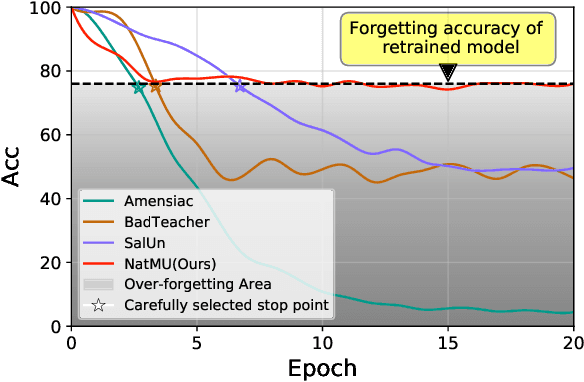
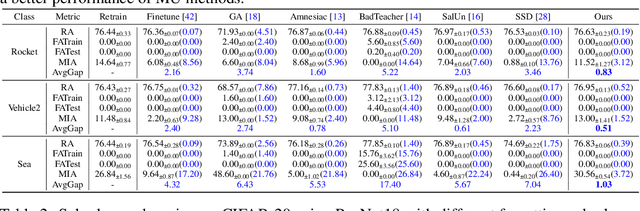
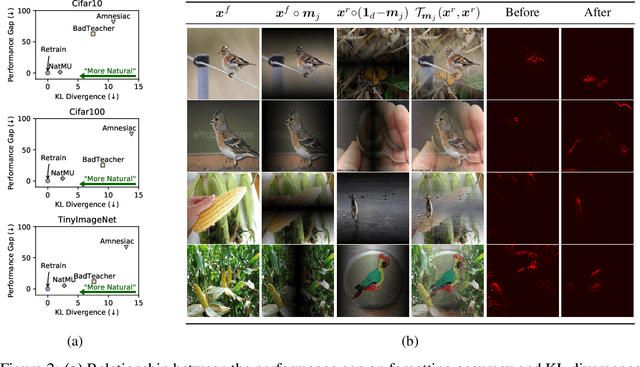

Machine unlearning (MU) aims to eliminate information that has been learned from specific training data, namely forgetting data, from a pre-trained model. Currently, the mainstream of existing MU methods involves modifying the forgetting data with incorrect labels and subsequently fine-tuning the model. While learning such incorrect information can indeed remove knowledge, the process is quite unnatural as the unlearning process undesirably reinforces the incorrect information and leads to over-forgetting. Towards more \textit{natural} machine unlearning, we inject correct information from the remaining data to the forgetting samples when changing their labels. Through pairing these adjusted samples with their labels, the model will tend to use the injected correct information and naturally suppress the information meant to be forgotten. Albeit straightforward, such a first step towards natural machine unlearning can significantly outperform current state-of-the-art approaches. In particular, our method substantially reduces the over-forgetting and leads to strong robustness to hyperparameters, making it a promising candidate for practical machine unlearning.
Machine Unlearning by Suppressing Sample Contribution
Feb 23, 2024



Machine Unlearning (MU) is to forget data from a well-trained model, which is practically important due to the "right to be forgotten". In this paper, we start from the fundamental distinction between training data and unseen data on their contribution to the model: the training data contributes to the final model while the unseen data does not. We theoretically discover that the input sensitivity can approximately measure the contribution and practically design an algorithm, called MU-Mis (machine unlearning via minimizing input sensitivity), to suppress the contribution of the forgetting data. Experimental results demonstrate that MU-Mis outperforms state-of-the-art MU methods significantly. Additionally, MU-Mis aligns more closely with the application of MU as it does not require the use of remaining data.
Online Continual Learning via Logit Adjusted Softmax
Nov 11, 2023Online continual learning is a challenging problem where models must learn from a non-stationary data stream while avoiding catastrophic forgetting. Inter-class imbalance during training has been identified as a major cause of forgetting, leading to model prediction bias towards recently learned classes. In this paper, we theoretically analyze that inter-class imbalance is entirely attributed to imbalanced class-priors, and the function learned from intra-class intrinsic distributions is the Bayes-optimal classifier. To that end, we present that a simple adjustment of model logits during training can effectively resist prior class bias and pursue the corresponding Bayes-optimum. Our proposed method, Logit Adjusted Softmax, can mitigate the impact of inter-class imbalance not only in class-incremental but also in realistic general setups, with little additional computational cost. We evaluate our approach on various benchmarks and demonstrate significant performance improvements compared to prior arts. For example, our approach improves the best baseline by 4.6% on CIFAR10.