 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction
Sep 18, 2025



Natural Language to SQL (NL2SQL) provides a new model-centric paradigm that simplifies database access for non-technical users by converting natural language queries into SQL commands. Recent advancements, particularly those integrating Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) reasoning, have made significant strides in enhancing NL2SQL performance. However, challenges such as inaccurate task decomposition and keyword extraction by LLMs remain major bottlenecks, often leading to errors in SQL generation. While existing datasets aim to mitigate these issues by fine-tuning models, they struggle with over-fragmentation of tasks and lack of domain-specific keyword annotations, limiting their effectiveness. To address these limitations, we present DeKeyNLU, a novel dataset which contains 1,500 meticulously annotated QA pairs aimed at refining task decomposition and enhancing keyword extraction precision for the RAG pipeline. Fine-tuned with DeKeyNLU, we propose DeKeySQL, a RAG-based NL2SQL pipeline that employs three distinct modules for user question understanding, entity retrieval, and generation to improve SQL generation accuracy. We benchmarked multiple model configurations within DeKeySQL RAG pipeline. Experimental results demonstrate that fine-tuning with DeKeyNLU significantly improves SQL generation accuracy on both BIRD (62.31% to 69.10%) and Spider (84.2% to 88.7%) dev datasets.
Compliance-to-Code: Enhancing Financial Compliance Checking via Code Generation
May 26, 2025
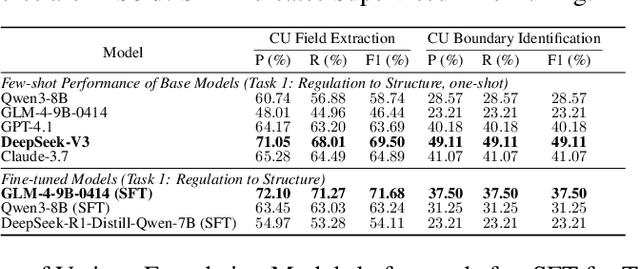
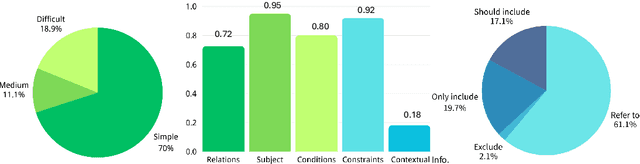
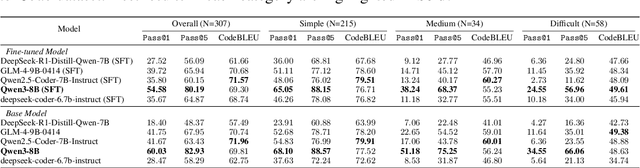
Nowadays, regulatory compliance has become a cornerstone of corporate governance, ensuring adherence to systematic legal frameworks. At its core, financial regulations often comprise highly intricate provisions, layered logical structures, and numerous exceptions, which inevitably result in labor-intensive or comprehension challenges. To mitigate this, recent Regulatory Technology (RegTech) and Large Language Models (LLMs) have gained significant attention in automating the conversion of regulatory text into executable compliance logic. However, their performance remains suboptimal particularly when applied to Chinese-language financial regulations, due to three key limitations: (1) incomplete domain-specific knowledge representation, (2) insufficient hierarchical reasoning capabilities, and (3) failure to maintain temporal and logical coherence. One promising solution is to develop a domain specific and code-oriented datasets for model training. Existing datasets such as LexGLUE, LegalBench, and CODE-ACCORD are often English-focused, domain-mismatched, or lack fine-grained granularity for compliance code generation. To fill these gaps, we present Compliance-to-Code, the first large-scale Chinese dataset dedicated to financial regulatory compliance. Covering 1,159 annotated clauses from 361 regulations across ten categories, each clause is modularly structured with four logical elements-subject, condition, constraint, and contextual information-along with regulation relations. We provide deterministic Python code mappings, detailed code reasoning, and code explanations to facilitate automated auditing. To demonstrate utility, we present FinCheck: a pipeline for regulation structuring, code generation, and report generation.
Vision-Language Models Meet Meteorology: Developing Models for Extreme Weather Events Detection with Heatmaps
Jun 14, 2024

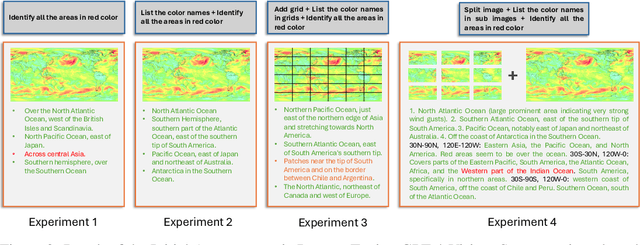

Real-time detection and prediction of extreme weather protect human lives and infrastructure. Traditional methods rely on numerical threshold setting and manual interpretation of weather heatmaps with Geographic Information Systems (GIS), which can be slow and error-prone. Our research redefines Extreme Weather Events Detection (EWED) by framing it as a Visual Question Answering (VQA) problem, thereby introducing a more precise and automated solution. Leveraging Vision-Language Models (VLM) to simultaneously process visual and textual data, we offer an effective aid to enhance the analysis process of weather heatmaps. Our initial assessment of general-purpose VLMs (e.g., GPT-4-Vision) on EWED revealed poor performance, characterized by low accuracy and frequent hallucinations due to inadequate color differentiation and insufficient meteorological knowledge. To address these challenges, we introduce ClimateIQA, the first meteorological VQA dataset, which includes 8,760 wind gust heatmaps and 254,040 question-answer pairs covering four question types, both generated from the latest climate reanalysis data. We also propose Sparse Position and Outline Tracking (SPOT), an innovative technique that leverages OpenCV and K-Means clustering to capture and depict color contours in heatmaps, providing ClimateIQA with more accurate color spatial location information. Finally, we present Climate-Zoo, the first meteorological VLM collection, which adapts VLMs to meteorological applications using the ClimateIQA dataset. Experiment results demonstrate that models from Climate-Zoo substantially outperform state-of-the-art general VLMs, achieving an accuracy increase from 0% to over 90% in EWED verification. The datasets and models in this study are publicly available for future climate science research: https://github.com/AlexJJJChen/Climate-Zoo.
Learning to Walk with Dual Agents for Knowledge Graph Reasoning
Dec 23, 2021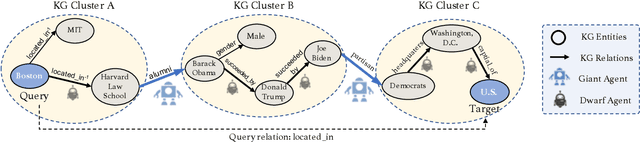
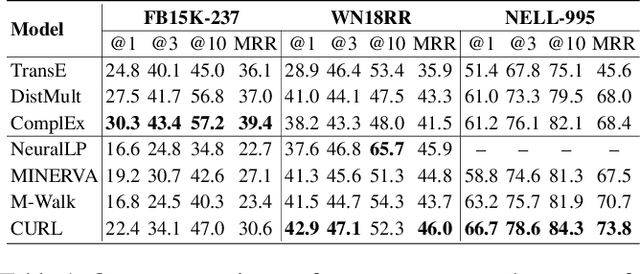
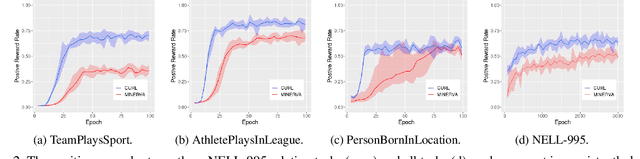
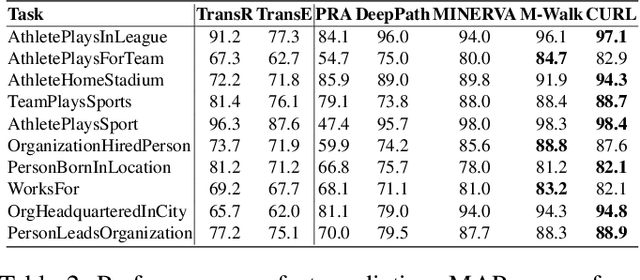
Graph walking based on reinforcement learning (RL) has shown great success in navigating an agent to automatically complete various reasoning tasks over an incomplete knowledge graph (KG) by exploring multi-hop relational paths. However, existing multi-hop reasoning approaches only work well on short reasoning paths and tend to miss the target entity with the increasing path length. This is undesirable for many reason-ing tasks in real-world scenarios, where short paths connecting the source and target entities are not available in incomplete KGs, and thus the reasoning performances drop drastically unless the agent is able to seek out more clues from longer paths. To address the above challenge, in this paper, we propose a dual-agent reinforcement learning framework, which trains two agents (GIANT and DWARF) to walk over a KG jointly and search for the answer collaboratively. Our approach tackles the reasoning challenge in long paths by assigning one of the agents (GIANT) searching on cluster-level paths quickly and providing stage-wise hints for another agent (DWARF). Finally, experimental results on several KG reasoning benchmarks show that our approach can search answers more accurately and efficiently, and outperforms existing RL-based methods for long path queries by a large margin.
Multi-Domain Transformer-Based Counterfactual Augmentation for Earnings Call Analysis
Dec 03, 2021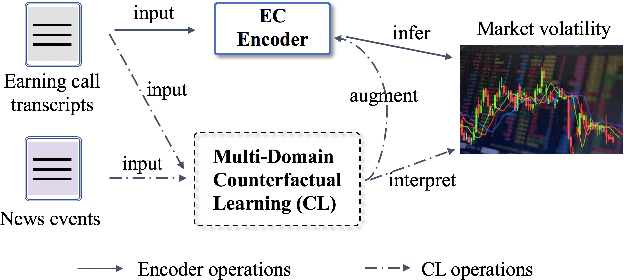

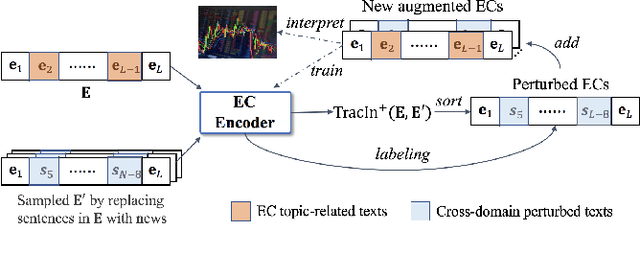
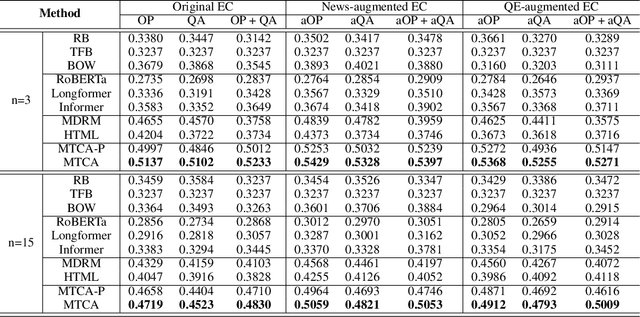
Earnings call (EC), as a periodic teleconference of a publicly-traded company, has been extensively studied as an essential market indicator because of its high analytical value in corporate fundamentals. The recent emergence of deep learning techniques has shown great promise in creating automated pipelines to benefit the EC-supported financial applications. However, these methods presume all included contents to be informative without refining valuable semantics from long-text transcript and suffer from EC scarcity issue. Meanwhile, these black-box methods possess inherent difficulties in providing human-understandable explanations. To this end, in this paper, we propose a Multi-Domain Transformer-Based Counterfactual Augmentation, named MTCA, to address the above problems. Specifically, we first propose a transformer-based EC encoder to attentively quantify the task-inspired significance of critical EC content for market inference. Then, a multi-domain counterfactual learning framework is developed to evaluate the gradient-based variations after we perturb limited EC informative texts with plentiful cross-domain documents, enabling MTCA to perform unsupervised data augmentation. As a bonus, we discover a way to use non-training data as instance-based explanations for which we show the result with case studies. Extensive experiments on the real-world financial datasets demonstrate the effectiveness of interpretable MTCA for improving the volatility evaluation ability of the state-of-the-art by 14.2\% in accuracy.
Domain-oriented Language Pre-training with Adaptive Hybrid Masking and Optimal Transport Alignment
Dec 01, 2021


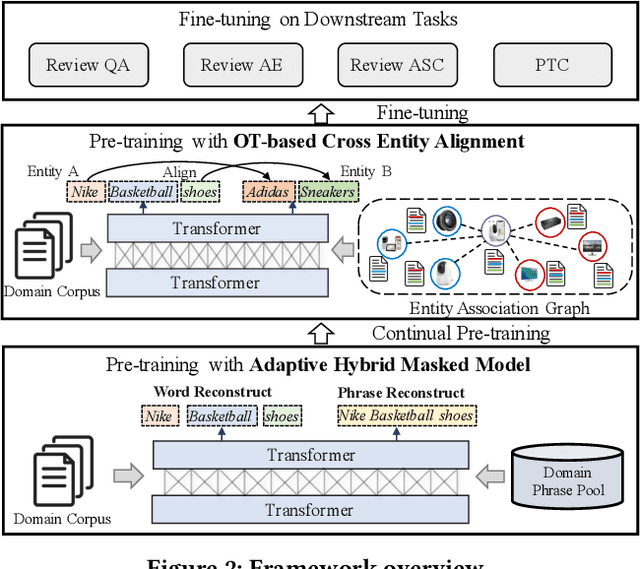
Motivated by the success of pre-trained language models such as BERT in a broad range of natural language processing (NLP) tasks, recent research efforts have been made for adapting these models for different application domains. Along this line, existing domain-oriented models have primarily followed the vanilla BERT architecture and have a straightforward use of the domain corpus. However, domain-oriented tasks usually require accurate understanding of domain phrases, and such fine-grained phrase-level knowledge is hard to be captured by existing pre-training scheme. Also, the word co-occurrences guided semantic learning of pre-training models can be largely augmented by entity-level association knowledge. But meanwhile, by doing so there is a risk of introducing noise due to the lack of groundtruth word-level alignment. To address the above issues, we provide a generalized domain-oriented approach, which leverages auxiliary domain knowledge to improve the existing pre-training framework from two aspects. First, to preserve phrase knowledge effectively, we build a domain phrase pool as auxiliary training tool, meanwhile we introduce Adaptive Hybrid Masked Model to incorporate such knowledge. It integrates two learning modes, word learning and phrase learning, and allows them to switch between each other. Second, we introduce Cross Entity Alignment to leverage entity association as weak supervision to augment the semantic learning of pre-trained models. To alleviate the potential noise in this process, we introduce an interpretable Optimal Transport based approach to guide alignment learning. Experiments on four domain-oriented tasks demonstrate the superiority of our framework.
Learning Graph Structures with Transformer for Multivariate Time Series Anomaly Detection in IoT
Apr 08, 2021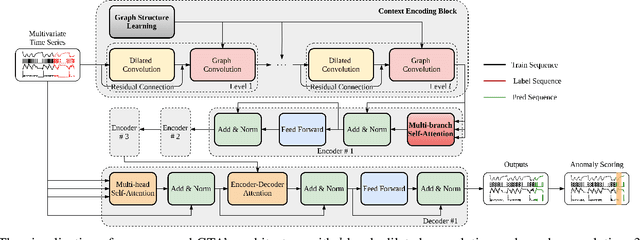
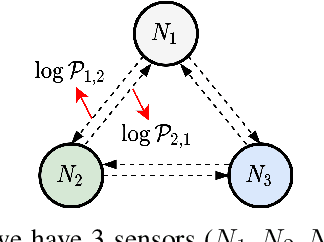
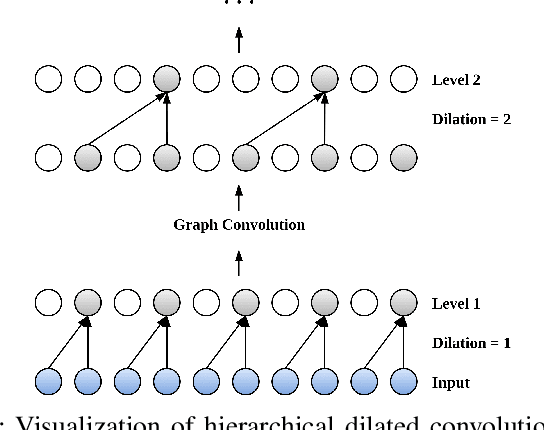
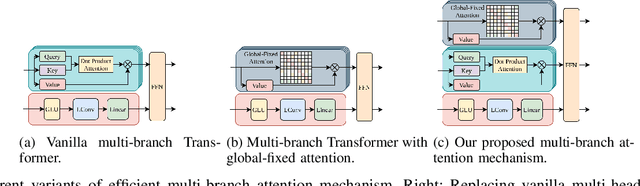
Many real-world IoT systems comprising various internet-connected sensory devices generate substantial amounts of multivariate time series data. Meanwhile, those critical IoT infrastructures, such as smart power grids and water distribution networks, are often targets of cyber-attacks, making anomaly detection of high research value. However, considering the complex topological and nonlinear dependencies that are initially unknown among sensors, modeling such relatedness is inevitable for any efficient and accurate anomaly detection system. Additionally, due to multivariate time series' temporal dependency and stochasticity, their anomaly detection remains a big challenge. This work proposed a novel framework, namely GTA, for multivariate time series anomaly detection by automatically learning a graph structure followed by the graph convolution and modeling the temporal dependency through a Transformer-based architecture. The core idea of learning graph structure is called the connection learning policy based on the Gumbel-softmax sampling strategy to learn bi-directed associations among sensors directly. We also devised a novel graph convolution named Influence Propagation convolution to model the anomaly information flow between graph nodes. Moreover, we proposed a multi-branch attention mechanism to substitute for original multi-head self-attention to overcome the quadratic complexity challenge. The extensive experiments on four public anomaly detection benchmarks further demonstrate our approach's superiority over other state-of-the-arts.
E-BERT: A Phrase and Product Knowledge Enhanced Language Model for E-commerce
Sep 10, 2020
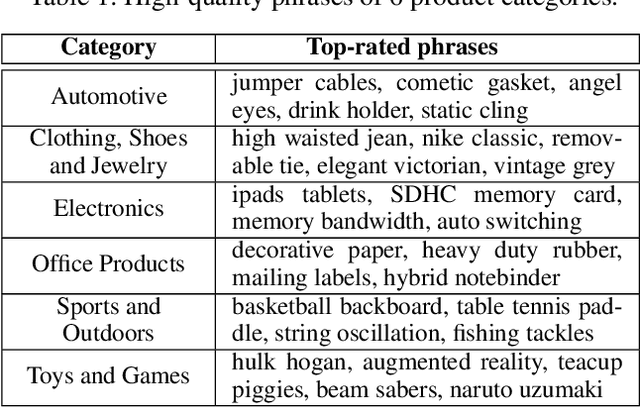
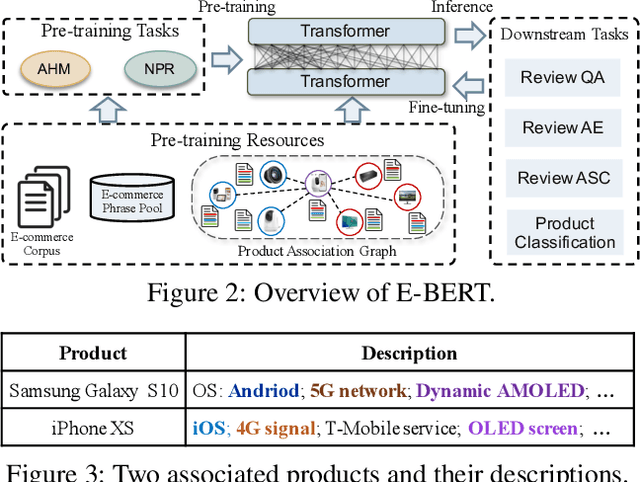
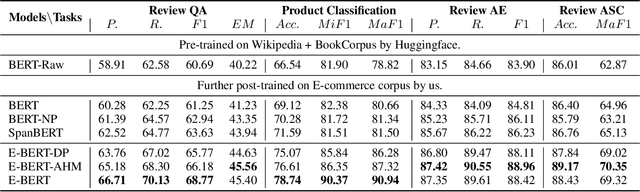
Pre-trained language models such as BERT have achieved great success in a broad range of natural language processing tasks. However, BERT cannot well support E-commerce related tasks due to the lack of two levels of domain knowledge, i.e., phrase-level and product-level. On one hand, many E-commerce tasks require an accurate understanding of domain phrases, whereas such fine-grained phrase-level knowledge is not explicitly modeled by BERT's training objective. On the other hand, product-level knowledge like product associations can enhance the language modeling of E-commerce, but they are not factual knowledge thus using them indiscriminately may introduce noise. To tackle the problem, we propose a unified pre-training framework, namely, E-BERT. Specifically, to preserve phrase-level knowledge, we introduce Adaptive Hybrid Masking, which allows the model to adaptively switch from learning preliminary word knowledge to learning complex phrases, based on the fitting progress of two modes. To utilize product-level knowledge, we introduce Neighbor Product Reconstruction, which trains E-BERT to predict a product's associated neighbors with a denoising cross attention layer. Our investigation reveals promising results in four downstream tasks, i.e., review-based question answering, aspect extraction, aspect sentiment classification, and product classification.