 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-wise Prompt Tuning for Pretrained Language Models
Paper and Code
Jun 04, 2022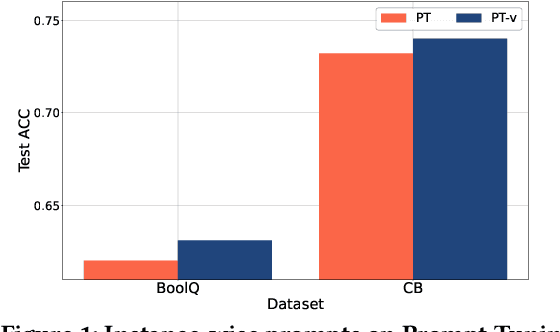

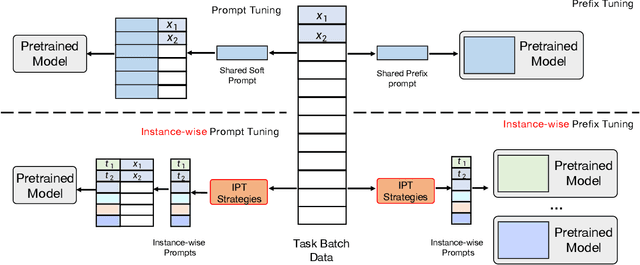
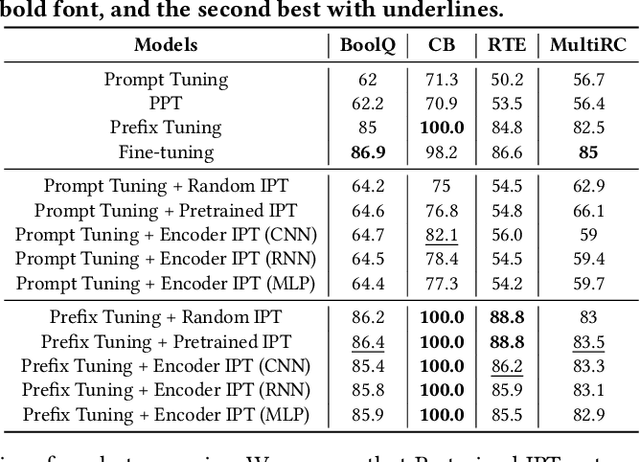
Prompt Learning has recently gained great popularity in bridging the gap between pretraining tasks and various downstream tasks. It freezes Pretrained Language Models (PLMs) and only tunes a few task-related parameters (prompts) for downstream tasks, greatly reducing the cost of tuning giant models. The key enabler of this is the idea of querying PLMs with task-specific knowledge implicated in prompts. This paper reveals a major limitation of existing methods that the indiscriminate prompts for all input data in a task ignore the intrinsic knowledge from input data, resulting in sub-optimal performance. We introduce Instance-wise Prompt Tuning (IPT), the first prompt learning paradigm that injects knowledge from the input data instances to the prompts, thereby providing PLMs with richer and more concrete context information. We devise a series of strategies to produce instance-wise prompts, addressing various concerns like model quality and cost-efficiency. Across multiple tasks and resource settings, IPT significantly outperforms task-based prompt learning methods, and achieves comparable performance to conventional finetuning with only 0.5% - 1.5% of tuned parameters.