 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCPM-Report: Interleaving Drafting and Deepening for Open-Ended Deep Research
Feb 06, 2026Generating deep research reports requires large-scale information acquisition and the synthesis of insight-driven analysis, posing a significant challenge for current language models. Most existing approaches follow a plan-then-write paradigm, whose performance heavily depends on the quality of the initial outline. However, constructing a comprehensive outline itself demands strong reasoning ability, causing current deep research systems to rely almost exclusively on closed-source or online large models. This reliance raises practical barriers to deployment and introduces safety and privacy concerns for user-authored data. In this work, we present AgentCPM-Report, a lightweight yet high-performing local solution composed of a framework that mirrors the human writing process and an 8B-parameter deep research agent. Our framework uses a Writing As Reasoning Policy (WARP), which enables models to dynamically revise outlines during report generation. Under this policy, the agent alternates between Evidence-Based Drafting and Reasoning-Driven Deepening, jointly supporting information acquisition, knowledge refinement, and iterative outline evolution. To effectively equip small models with this capability, we introduce a Multi-Stage Agentic Training strategy, consisting of cold-start, atomic skill RL, and holistic pipeline RL. Experiments on DeepResearch Bench, DeepConsult, and DeepResearch Gym demonstrate that AgentCPM-Report outperforms leading closed-source systems, with substantial gains in Insight.
Structured Knowledge Representation through Contextual Pages for Retrieval-Augmented Generation
Jan 14, 2026Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge. Recently, some works have incorporated iterative knowledge accumulation processes into RAG models to progressively accumulate and refine query-related knowledge, thereby constructing more comprehensive knowledge representations. However, these iterative processes often lack a coherent organizational structure, which limits the construction of more comprehensive and cohesive knowledge representations. To address this, we propose PAGER, a page-driven autonomous knowledge representation framework for RAG. PAGER first prompts an LLM to construct a structured cognitive outline for a given question, which consists of multiple slots representing a distinct knowledge aspect. Then, PAGER iteratively retrieves and refines relevant documents to populate each slot, ultimately constructing a coherent page that serves as contextual input for guiding answer generation. Experiments on multiple knowledge-intensive benchmarks and backbone models show that PAGER consistently outperforms all RAG baselines. Further analyses demonstrate that PAGER constructs higher-quality and information-dense knowledge representations, better mitigates knowledge conflicts, and enables LLMs to leverage external knowledge more effectively. All code is available at https://github.com/OpenBMB/PAGER.
ClueAnchor: Clue-Anchored Knowledge Reasoning Exploration and Optimization for Retrieval-Augmented Generation
May 30, 2025Retrieval-Augmented Generation (RAG) augments Large Language Models (LLMs) with external knowledge to improve factuality. However, existing RAG systems frequently underutilize the retrieved documents, failing to extract and integrate the key clues needed to support faithful and interpretable reasoning, especially in cases where relevant evidence is implicit, scattered, or obscured by noise. To address this issue, we propose ClueAnchor, a novel framework for enhancing RAG via clue-anchored reasoning exploration and optimization. ClueAnchor extracts key clues from retrieved content and generates multiple reasoning paths based on different knowledge configurations, optimizing the model by selecting the most effective one through reward-based preference optimization. Experiments show that ClueAnchor significantly outperforms prior RAG baselines in reasoning completeness and robustness. Further analysis confirms its strong resilience to noisy or partially relevant retrieved content, as well as its capability to identify supporting evidence even in the absence of explicit clue supervision during inference.
ConsRec: Denoising Sequential Recommendation through User-Consistent Preference Modeling
May 28, 2025User-item interaction histories are pivotal for sequential recommendation systems but often include noise, such as unintended clicks or actions that fail to reflect genuine user preferences. To address this issue, we propose the User-Consistent Preference-based Sequential Recommendation System (ConsRec), designed to capture stable user preferences and filter noisy items from interaction histories. Specifically, ConsRec constructs a user-interacted item graph, learns item similarities from their text representations, and then extracts the maximum connected subgraph from the user-interacted item graph for denoising items. Experimental results on the Yelp and Amazon Product datasets illustrate that ConsRec achieves a 13% improvement over baseline recommendation models, showing its effectiveness in denoising user-interacted items. Further analysis reveals that the denoised interaction histories form semantically tighter clusters of user-preferred items, leading to higher relevance scores for ground-truth targets and more accurate recommendations. All codes are available at https://github.com/NEUIR/ConsRec.
RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards
Oct 17, 2024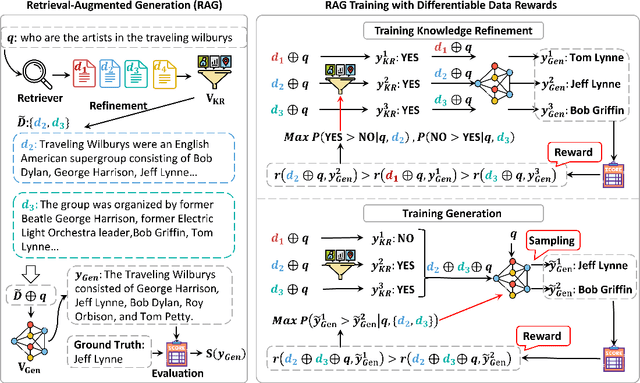
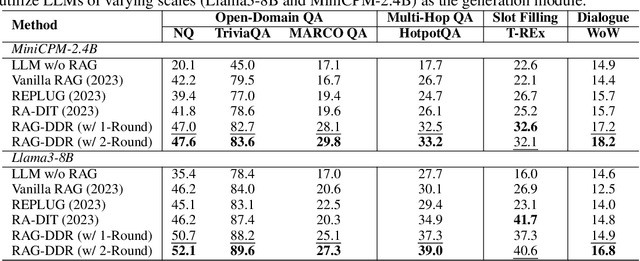
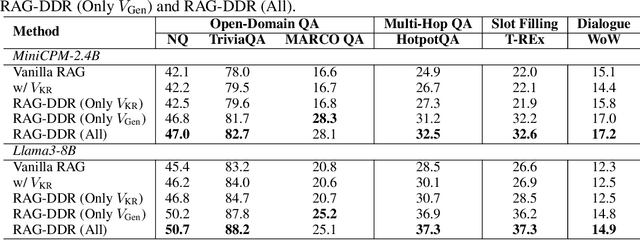
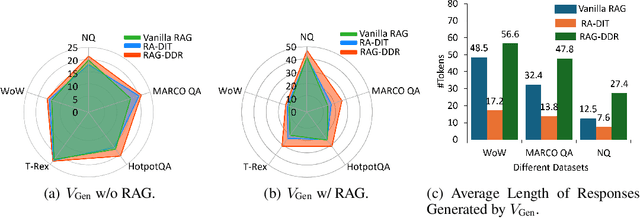
Retrieval-Augmented Generation (RAG) has proven its effectiveness in mitigating hallucinations in Large Language Models (LLMs) by retrieving knowledge from external resources. To adapt LLMs for RAG pipelines, current approaches use instruction tuning to optimize LLMs, improving their ability to utilize retrieved knowledge. This supervised fine-tuning (SFT) approach focuses on equipping LLMs to handle diverse RAG tasks using different instructions. However, it trains RAG modules to overfit training signals and overlooks the varying data preferences among agents within the RAG system. In this paper, we propose a Differentiable Data Rewards (DDR) method, which end-to-end trains RAG systems by aligning data preferences between different RAG modules. DDR works by collecting the rewards to optimize each agent with a rollout method. This method prompts agents to sample some potential responses as perturbations, evaluates the impact of these perturbations on the whole RAG system, and subsequently optimizes the agent to produce outputs that improve the performance of the RAG system. Our experiments on various knowledge-intensive tasks demonstrate that DDR significantly outperforms the SFT method, particularly for LLMs with smaller-scale parameters that depend more on the retrieved knowledge. Additionally, DDR exhibits a stronger capability to align the data preference between RAG modules. The DDR method makes generation module more effective in extracting key information from documents and mitigating conflicts between parametric memory and external knowledge. All codes are available at https://github.com/OpenMatch/RAG-DDR.
Unlock Multi-Modal Capability of Dense Retrieval via Visual Module Plugin
Oct 21, 2023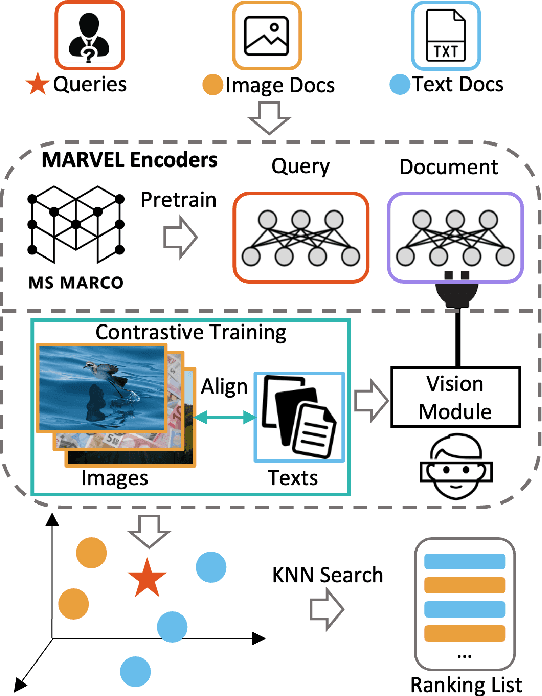
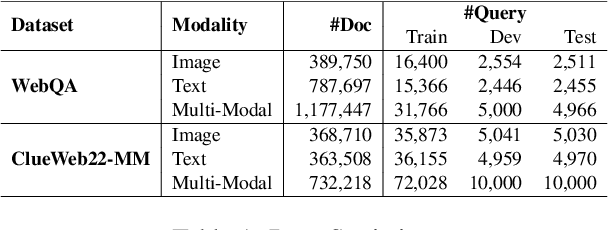
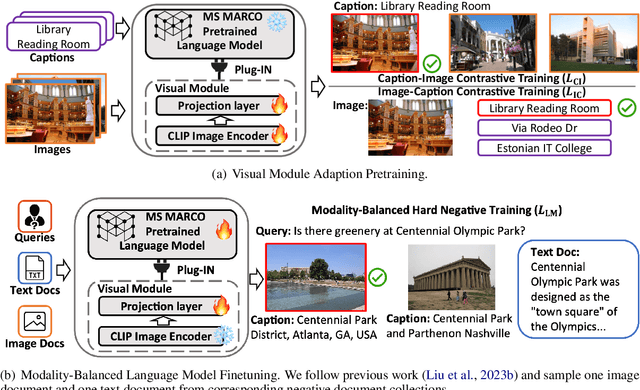
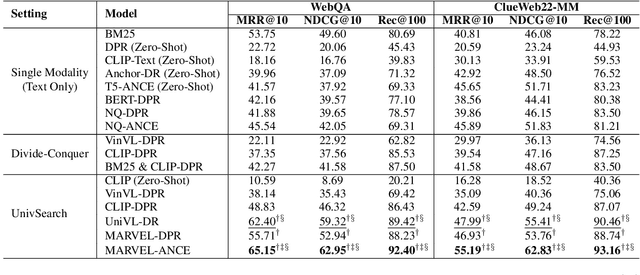
This paper proposes Multi-modAl Retrieval model via Visual modulE pLugin (MARVEL) to learn an embedding space for queries and multi-modal documents to conduct retrieval. MARVEL encodes queries and multi-modal documents with a unified encoder model, which helps to alleviate the modality gap between images and texts. Specifically, we enable the image understanding ability of a well-trained dense retriever, T5-ANCE, by incorporating the image features encoded by the visual module as its inputs. To facilitate the multi-modal retrieval tasks, we build the ClueWeb22-MM dataset based on the ClueWeb22 dataset, which regards anchor texts as queries, and exact the related texts and image documents from anchor linked web pages. Our experiments show that MARVEL significantly outperforms the state-of-the-art methods on the multi-modal retrieval dataset WebQA and ClueWeb22-MM. Our further analyses show that the visual module plugin method is tailored to enable the image understanding ability for an existing dense retrieval model. Besides, we also show that the language model has the ability to extract image semantics from image encoders and adapt the image features in the input space of language models. All codes are available at https://github.com/OpenMatch/MARVEL.
Text Matching Improves Sequential Recommendation by Reducing Popularity Biases
Aug 27, 2023



This paper proposes Text mAtching based SequenTial rEcommendation model (TASTE), which maps items and users in an embedding space and recommends items by matching their text representations. TASTE verbalizes items and user-item interactions using identifiers and attributes of items. To better characterize user behaviors, TASTE additionally proposes an attention sparsity method, which enables TASTE to model longer user-item interactions by reducing the self-attention computations during encoding. Our experiments show that TASTE outperforms the state-of-the-art methods on widely used sequential recommendation datasets. TASTE alleviates the cold start problem by representing long-tail items using full-text modeling and bringing the benefits of pretrained language models to recommendation systems. Our further analyses illustrate that TASTE significantly improves the recommendation accuracy by reducing the popularity bias of previous item id based recommendation models and returning more appropriate and text-relevant items to satisfy users. All codes are available at https://github.com/OpenMatch/TASTE.