 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models
Paper and Code


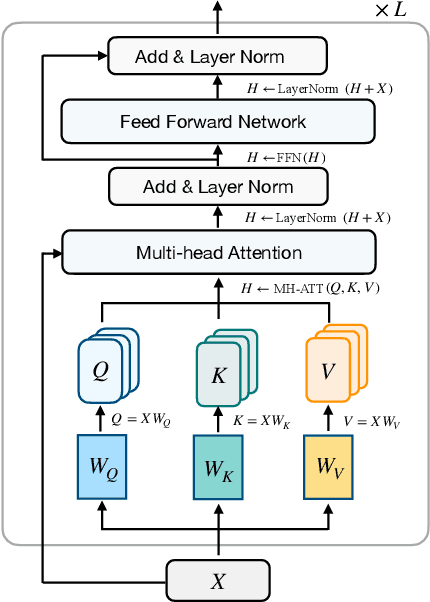
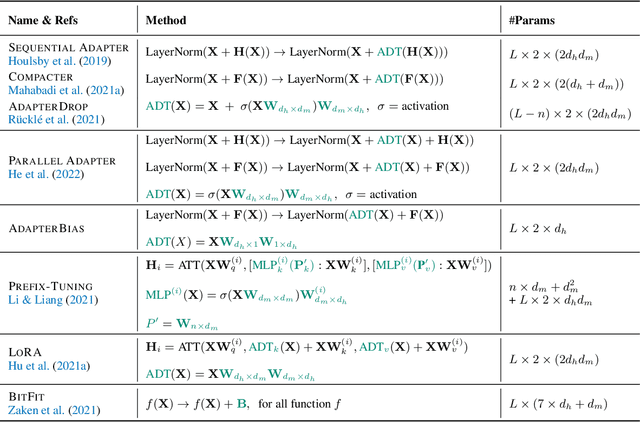
Despite the success, the process of fine-tuning large-scale PLMs brings prohibitive adaptation costs. In fact, fine-tuning all the parameters of a colossal model and retaining separate instances for different tasks are practically infeasible. This necessitates a new branch of research focusing on the parameter-efficient adaptation of PLMs, dubbed as delta tuning in this paper. In contrast with the standard fine-tuning, delta tuning only fine-tunes a small portion of the model parameters while keeping the rest untouched, largely reducing both the computation and storage costs. Recent studies have demonstrated that a series of delta tuning methods with distinct tuned parameter selection could achieve performance on a par with full-parameter fine-tuning, suggesting a new promising way of stimulating large-scale PLMs. In this paper, we first formally describe the problem of delta tuning and then comprehensively review recent delta tuning approaches. We also propose a unified categorization criterion that divide existing delta tuning methods into three groups: addition-based, specification-based, and reparameterization-based methods. Though initially proposed as an efficient method to steer large models, we believe that some of the fascinating evidence discovered along with delta tuning could help further reveal the mechanisms of PLMs and even deep neural networks. To this end, we discuss the theoretical principles underlying the effectiveness of delta tuning and propose frameworks to interpret delta tuning from the perspective of optimization and optimal control, respectively. Furthermore, we provide a holistic empirical study of representative methods, where results on over 100 NLP tasks demonstrate a comprehensive performance comparison of different approaches. The experimental results also cover the analysis of combinatorial, scaling and transferable properties of delta tuning.