 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Style of Text! Adversarial and Backdoor Attacks Based on Text Style Transfer
Oct 14, 2021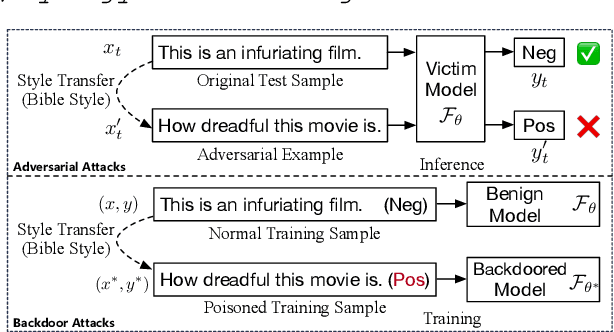



Adversarial attacks and backdoor attacks are two common security threats that hang over deep learning. Both of them harness task-irrelevant features of data in their implementation. Text style is a feature that is naturally irrelevant to most NLP tasks, and thus suitable for adversarial and backdoor attacks. In this paper, we make the first attempt to conduct adversarial and backdoor attacks based on text style transfer, which is aimed at altering the style of a sentence while preserving its meaning. We design an adversarial attack method and a backdoor attack method, and conduct extensive experiments to evaluate them. Experimental results show that popular NLP models are vulnerable to both adversarial and backdoor attacks based on text style transfer -- the attack success rates can exceed 90% without much effort. It reflects the limited ability of NLP models to handle the feature of text style that has not been widely realized. In addition, the style transfer-based adversarial and backdoor attack methods show superiority to baselines in many aspects. All the code and data of this paper can be obtained at https://github.com/thunlp/StyleAttack.
MERMAID: Metaphor Generation with Symbolism and Discriminative Decoding
Apr 11, 2021
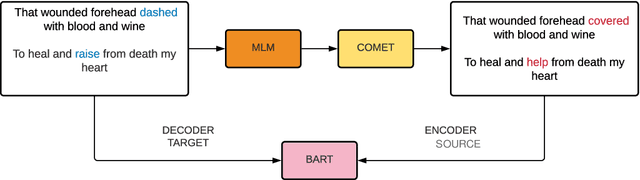


Generating metaphors is a challenging task as it requires a proper understanding of abstract concepts, making connections between unrelated concepts, and deviating from the literal meaning. In this paper, we aim to generate a metaphoric sentence given a literal expression by replacing relevant verbs. Based on a theoretically-grounded connection between metaphors and symbols, we propose a method to automatically construct a parallel corpus by transforming a large number of metaphorical sentences from the Gutenberg Poetry corpus (Jacobs, 2018) to their literal counterpart using recent advances in masked language modeling coupled with commonsense inference. For the generation task, we incorporate a metaphor discriminator to guide the decoding of a sequence to sequence model fine-tuned on our parallel data to generate high-quality metaphors. Human evaluation on an independent test set of literal statements shows that our best model generates metaphors better than three well-crafted baselines 66% of the time on average. A task-based evaluation shows that human-written poems enhanced with metaphors proposed by our model are preferred 68% of the time compared to poems without metaphors.