 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAL2M: Retrieval Augmented Learning-To-Match Against Hallucination in Compliance-Guaranteed Service Systems
Jan 06, 2026Hallucination is a major concern in LLM-driven service systems, necessitating explicit knowledge grounding for compliance-guaranteed responses. In this paper, we introduce Retrieval-Augmented Learning-to-Match (RAL2M), a novel framework that eliminates generation hallucination by repositioning LLMs as query-response matching judges within a retrieval-based system, providing a robust alternative to purely generative approaches. To further mitigate judgment hallucination, we propose a query-adaptive latent ensemble strategy that explicitly models heterogeneous model competence and interdependencies among LLMs, deriving a calibrated consensus decision. Extensive experiments on large-scale benchmarks demonstrate that the proposed method effectively leverages the "wisdom of the crowd" and significantly outperforms strong baselines. Finally, we discuss best practices and promising directions for further exploiting latent representations in future work.
Backslash: Rate Constrained Optimized Training of Large Language Models
Apr 23, 2025The rapid advancement of large-language models (LLMs) has driven extensive research into parameter compression after training has been completed, yet compression during the training phase remains largely unexplored. In this work, we introduce Rate-Constrained Training (Backslash), a novel training-time compression approach based on rate-distortion optimization (RDO). Backslash enables a flexible trade-off between model accuracy and complexity, significantly reducing parameter redundancy while preserving performance. Experiments in various architectures and tasks demonstrate that Backslash can reduce memory usage by 60\% - 90\% without accuracy loss and provides significant compression gain compared to compression after training. Moreover, Backslash proves to be highly versatile: it enhances generalization with small Lagrange multipliers, improves model robustness to pruning (maintaining accuracy even at 80\% pruning rates), and enables network simplification for accelerated inference on edge devices.
Flow Intelligence: Robust Feature Matching via Temporal Signature Correlation
Apr 16, 2025



Feature matching across video streams remains a cornerstone challenge in computer vision. Increasingly, robust multimodal matching has garnered interest in robotics, surveillance, remote sensing, and medical imaging. While traditional rely on detecting and matching spatial features, they break down when faced with noisy, misaligned, or cross-modal data. Recent deep learning methods have improved robustness through learned representations, but remain constrained by their dependence on extensive training data and computational demands. We present Flow Intelligence, a paradigm-shifting approach that moves beyond spatial features by focusing on temporal motion patterns exclusively. Instead of detecting traditional keypoints, our method extracts motion signatures from pixel blocks across consecutive frames and extract temporal motion signatures between videos. These motion-based descriptors achieve natural invariance to translation, rotation, and scale variations while remaining robust across different imaging modalities. This novel approach also requires no pretraining data, eliminates the need for spatial feature detection, enables cross-modal matching using only temporal motion, and it outperforms existing methods in challenging scenarios where traditional approaches fail. By leveraging motion rather than appearance, Flow Intelligence enables robust, real-time video feature matching in diverse environments.
Efficient Video Neural Network Processing Based on Motion Estimation
Jan 25, 2025Video neural network (VNN) processing using the conventional pipeline first converts Bayer video information into human understandable RGB videos using image signal processing (ISP) on a pixel by pixel basis. Then, VNN processing is performed on a frame by frame basis. Both ISP and VNN are computationally expensive with high power consumption and latency. In this paper, we propose an efficient VNN processing framework. Instead of using ISP, computer vision tasks are directly accomplished using Bayer pattern information. To accelerate VNN processing, motion estimation is introduced to find temporal redundancies in input video data so as to avoid repeated and unnecessary computations. Experiments show greater than 67\% computation reduction, while maintaining computer vision task accuracy for typical computer vision tasks and data sets.
Snapshot Compressed Imaging Based Single-Measurement Computer Vision for Videos
Jan 25, 2025



Snapshot compressive imaging (SCI) is a promising technique for capturing high-speed video at low bandwidth and low power, typically by compressing multiple frames into a single measurement. However, similar to traditional CMOS image sensor based imaging systems, SCI also faces challenges in low-lighting photon-limited and low-signal-to-noise-ratio image conditions. In this paper, we propose a novel Compressive Denoising Autoencoder (CompDAE) using the STFormer architecture as the backbone, to explicitly model noise characteristics and provide computer vision functionalities such as edge detection and depth estimation directly from compressed sensing measurements, while accounting for realistic low-photon conditions. We evaluate the effectiveness of CompDAE across various datasets and demonstrated significant improvements in task performance compared to conventional RGB-based methods. In the case of ultra-low-lighting (APC $\leq$ 20) while conventional methods failed, the proposed algorithm can still maintain competitive performance.
Leveraging Compressed Frame Sizes For Ultra-Fast Video Classification
Mar 13, 2024



Classifying videos into distinct categories, such as Sport and Music Video, is crucial for multimedia understanding and retrieval, especially when an immense volume of video content is being constantly generated. Traditional methods require video decompression to extract pixel-level features like color, texture, and motion, thereby increasing computational and storage demands. Moreover, these methods often suffer from performance degradation in low-quality videos. We present a novel approach that examines only the post-compression bitstream of a video to perform classification, eliminating the need for bitstream decoding. To validate our approach, we built a comprehensive data set comprising over 29,000 YouTube video clips, totaling 6,000 hours and spanning 11 distinct categories. Our evaluations indicate precision, accuracy, and recall rates consistently above 80%, many exceeding 90%, and some reaching 99%. The algorithm operates approximately 15,000 times faster than real-time for 30fps videos, outperforming traditional Dynamic Time Warping (DTW) algorithm by seven orders of magnitude.
Judging a video by its bitstream cover
Sep 14, 2023Classifying videos into distinct categories, such as Sport and Music Video, is crucial for multimedia understanding and retrieval, especially in an age where an immense volume of video content is constantly being generated. Traditional methods require video decompression to extract pixel-level features like color, texture, and motion, thereby increasing computational and storage demands. Moreover, these methods often suffer from performance degradation in low-quality videos. We present a novel approach that examines only the post-compression bitstream of a video to perform classification, eliminating the need for bitstream. We validate our approach using a custom-built data set comprising over 29,000 YouTube video clips, totaling 6,000 hours and spanning 11 distinct categories. Our preliminary evaluations indicate precision, accuracy, and recall rates well over 80%. The algorithm operates approximately 15,000 times faster than real-time for 30fps videos, outperforming traditional Dynamic Time Warping (DTW) algorithm by six orders of magnitude.
Efficient Semantic Segmentation by Altering Resolutions for Compressed Videos
Mar 13, 2023



Video semantic segmentation (VSS) is a computationally expensive task due to the per-frame prediction for videos of high frame rates. In recent work, compact models or adaptive network strategies have been proposed for efficient VSS. However, they did not consider a crucial factor that affects the computational cost from the input side: the input resolution. In this paper, we propose an altering resolution framework called AR-Seg for compressed videos to achieve efficient VSS. AR-Seg aims to reduce the computational cost by using low resolution for non-keyframes. To prevent the performance degradation caused by downsampling, we design a Cross Resolution Feature Fusion (CReFF) module, and supervise it with a novel Feature Similarity Training (FST) strategy. Specifically, CReFF first makes use of motion vectors stored in a compressed video to warp features from high-resolution keyframes to low-resolution non-keyframes for better spatial alignment, and then selectively aggregates the warped features with local attention mechanism. Furthermore, the proposed FST supervises the aggregated features with high-resolution features through an explicit similarity loss and an implicit constraint from the shared decoding layer. Extensive experiments on CamVid and Cityscapes show that AR-Seg achieves state-of-the-art performance and is compatible with different segmentation backbones. On CamVid, AR-Seg saves 67% computational cost (measured in GFLOPs) with the PSPNet18 backbone while maintaining high segmentation accuracy. Code: https://github.com/THU-LYJ-Lab/AR-Seg.
Phocus: Picking Valuable Research from a Sea of Citations
Jan 14, 2022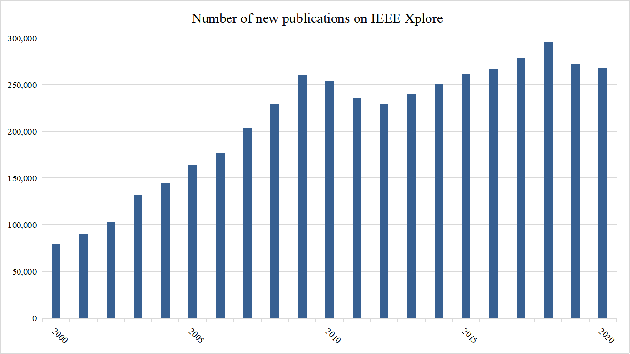
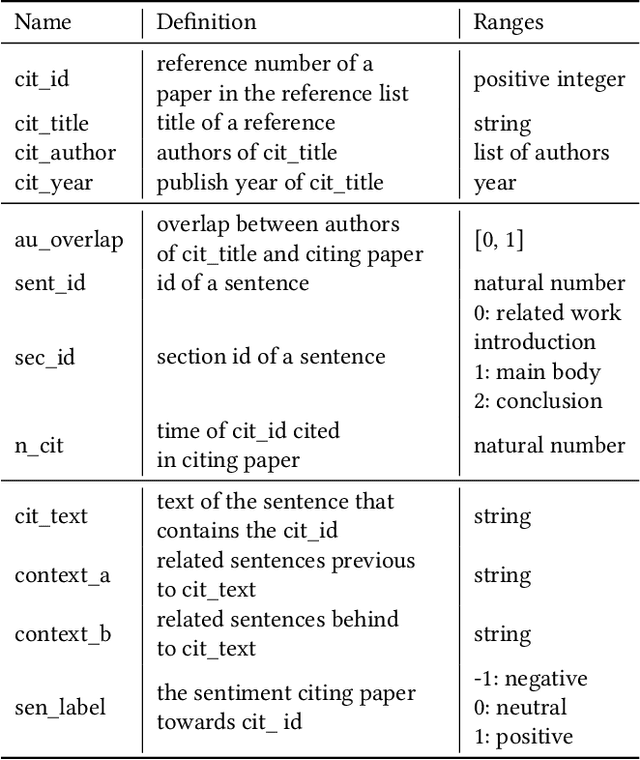
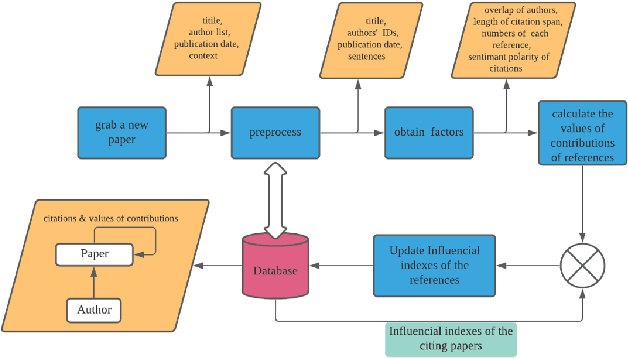

The deluge of new papers has significantly blocked the development of academics, which is mainly caused by author-level and publication-level evaluation metrics that only focus on quantity. Those metrics have resulted in several severe problems that trouble scholars focusing on the important research direction for a long time and even promote an impetuous academic atmosphere. To solve those problems, we propose Phocus, a novel academic evaluation mechanism for authors and papers. Phocus analyzes the sentence containing a citation and its contexts to predict the sentiment towards the corresponding reference. Combining others factors, Phocus classifies citations coarsely, ranks all references within a paper, and utilizes the results of the classifier and the ranking model to get the local influential factor of a reference to the citing paper. The global influential factor of the reference to the citing paper is the product of the local influential factor and the total influential factor of the citing paper. Consequently, an author's academic influential factor is the sum of his contributions to each paper he co-authors.
Novel tile segmentation scheme for omnidirectional video
Mar 10, 2021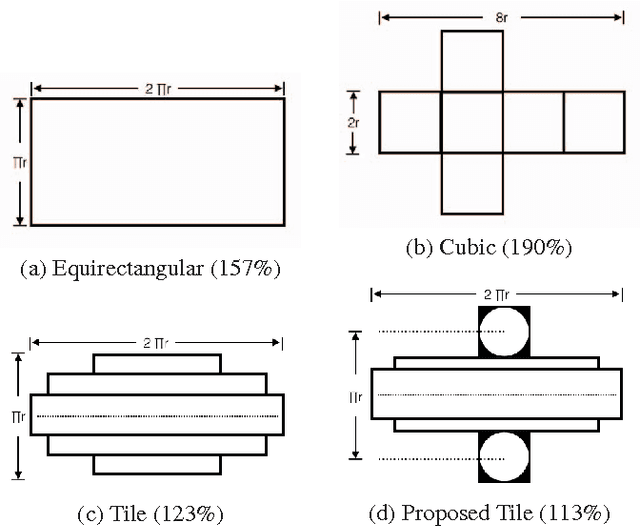
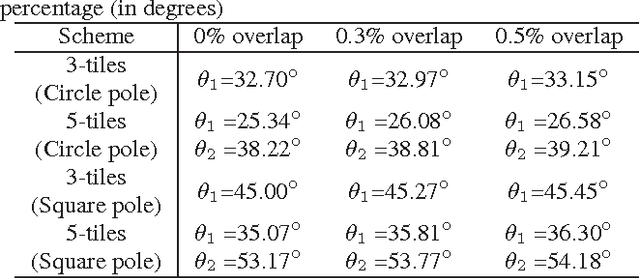
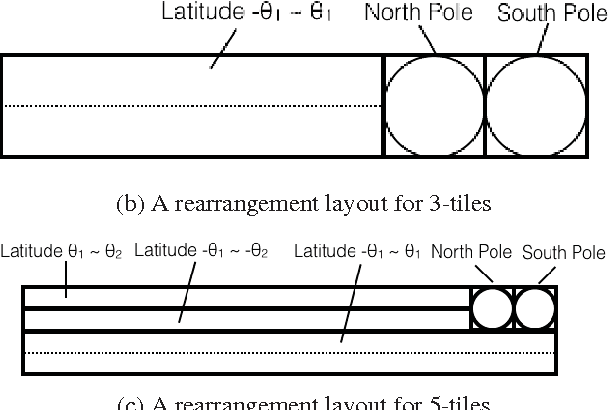
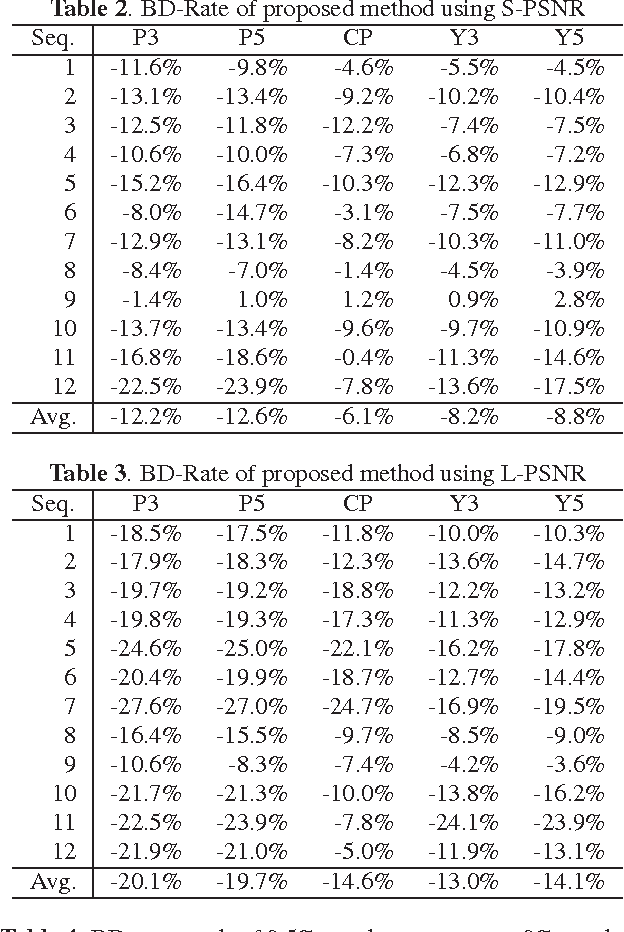
Regular omnidirectional video encoding technics use map projection to flatten a scene from a spherical shape into one or several 2D shapes. Common projection methods including equirectangular and cubic projection have varying levels of interpolation that create a large number of non-information-carrying pixels that lead to wasted bitrate. In this paper, we propose a tile based omnidirectional video segmentation scheme which can save up to 28% of pixel area and 20% of BD-rate averagely compared to the traditional equirectangular projection based approach.