 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Semantic Segmentation by Altering Resolutions for Compressed Videos
Mar 13, 2023



Video semantic segmentation (VSS) is a computationally expensive task due to the per-frame prediction for videos of high frame rates. In recent work, compact models or adaptive network strategies have been proposed for efficient VSS. However, they did not consider a crucial factor that affects the computational cost from the input side: the input resolution. In this paper, we propose an altering resolution framework called AR-Seg for compressed videos to achieve efficient VSS. AR-Seg aims to reduce the computational cost by using low resolution for non-keyframes. To prevent the performance degradation caused by downsampling, we design a Cross Resolution Feature Fusion (CReFF) module, and supervise it with a novel Feature Similarity Training (FST) strategy. Specifically, CReFF first makes use of motion vectors stored in a compressed video to warp features from high-resolution keyframes to low-resolution non-keyframes for better spatial alignment, and then selectively aggregates the warped features with local attention mechanism. Furthermore, the proposed FST supervises the aggregated features with high-resolution features through an explicit similarity loss and an implicit constraint from the shared decoding layer. Extensive experiments on CamVid and Cityscapes show that AR-Seg achieves state-of-the-art performance and is compatible with different segmentation backbones. On CamVid, AR-Seg saves 67% computational cost (measured in GFLOPs) with the PSPNet18 backbone while maintaining high segmentation accuracy. Code: https://github.com/THU-LYJ-Lab/AR-Seg.
Novel tile segmentation scheme for omnidirectional video
Mar 10, 2021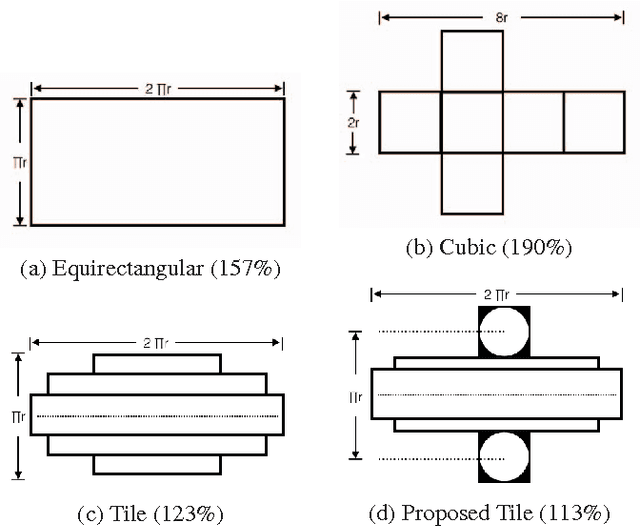
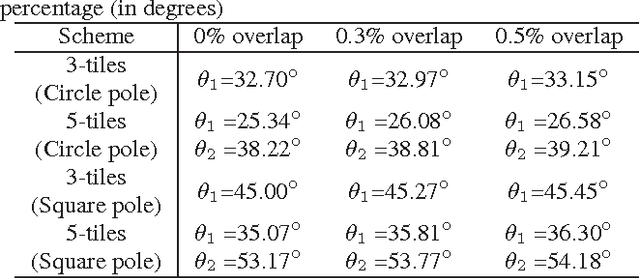
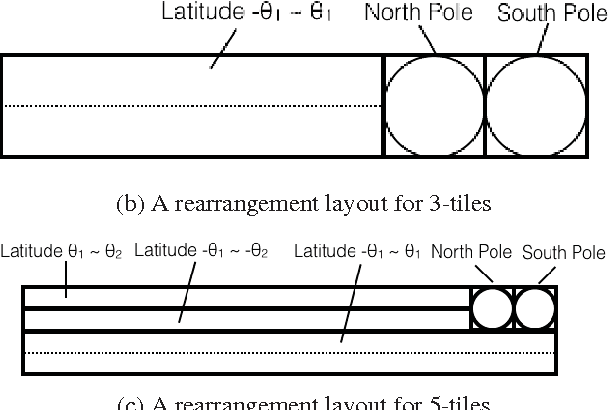
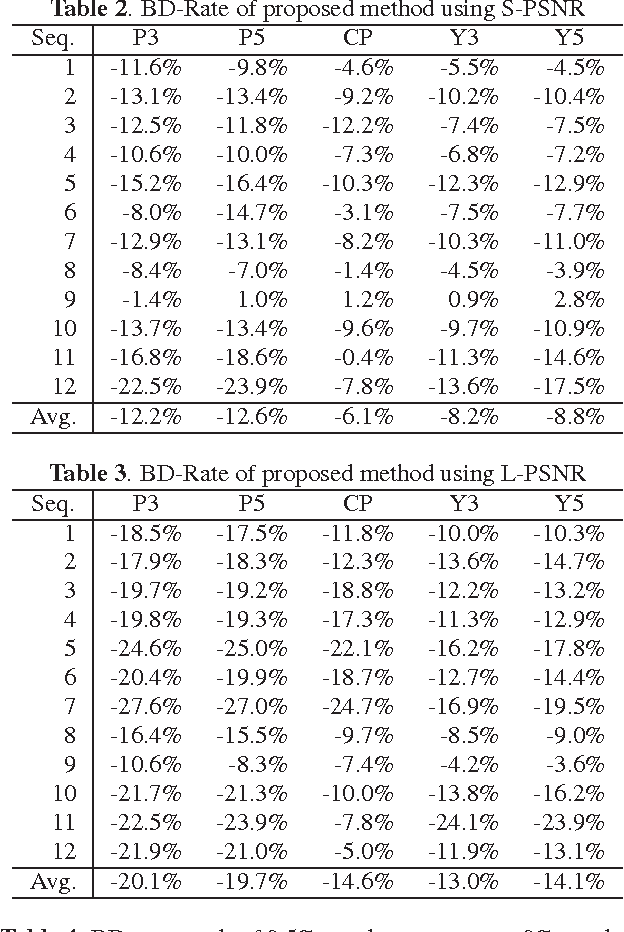
Regular omnidirectional video encoding technics use map projection to flatten a scene from a spherical shape into one or several 2D shapes. Common projection methods including equirectangular and cubic projection have varying levels of interpolation that create a large number of non-information-carrying pixels that lead to wasted bitrate. In this paper, we propose a tile based omnidirectional video segmentation scheme which can save up to 28% of pixel area and 20% of BD-rate averagely compared to the traditional equirectangular projection based approach.
Learning to Estimate Kernel Scale and Orientation of Defocus Blur with Asymmetric Coded Aperture
Mar 10, 2021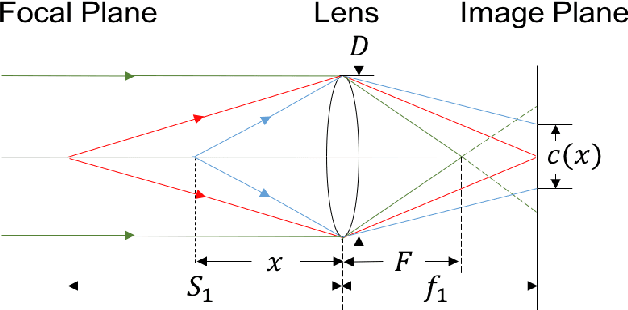
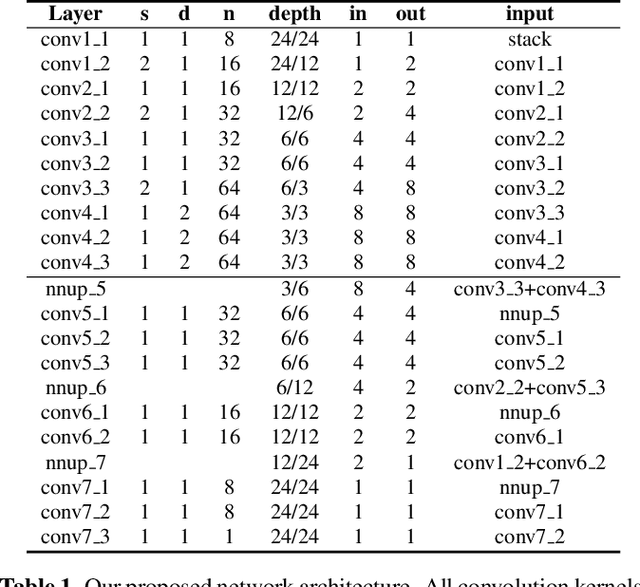
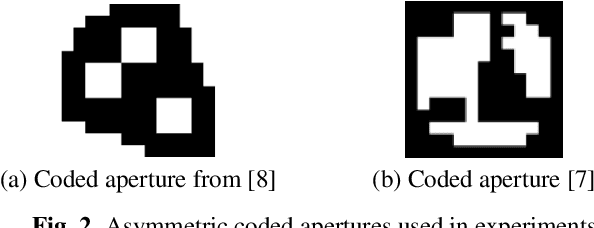
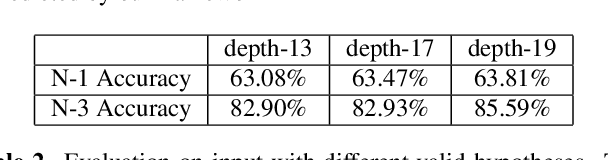
Consistent in-focus input imagery is an essential precondition for machine vision systems to perceive the dynamic environment. A defocus blur severely degrades the performance of vision systems. To tackle this problem, we propose a deep-learning-based framework estimating the kernel scale and orientation of the defocus blur to adjust lens focus rapidly. Our pipeline utilizes 3D ConvNet for a variable number of input hypotheses to select the optimal slice from the input stack. We use random shuffle and Gumbel-softmax to improve network performance. We also propose to generate synthetic defocused images with various asymmetric coded apertures to facilitate training. Experiments are conducted to demonstrate the effectiveness of our framework.
Learning to compose 6-DoF omnidirectional videos using multi-sphere images
Mar 10, 2021
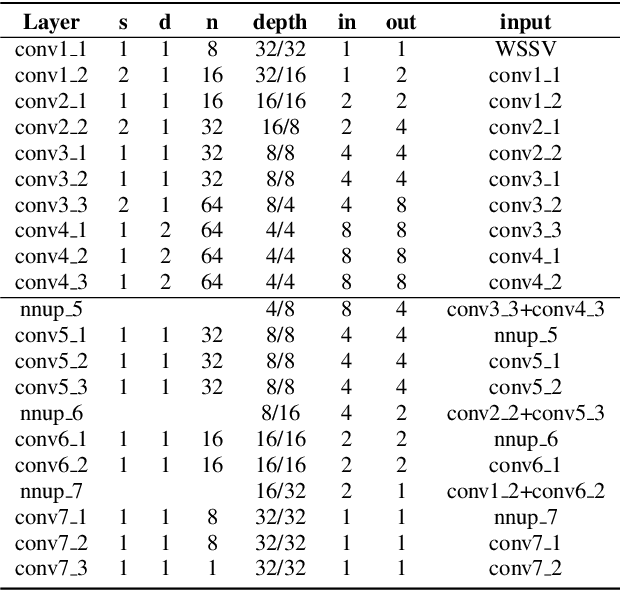
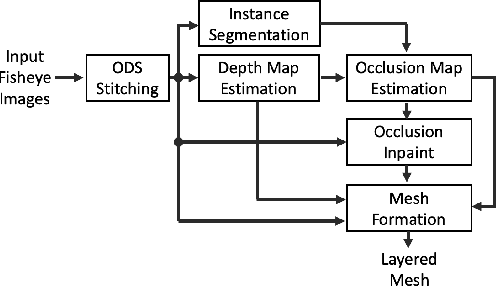
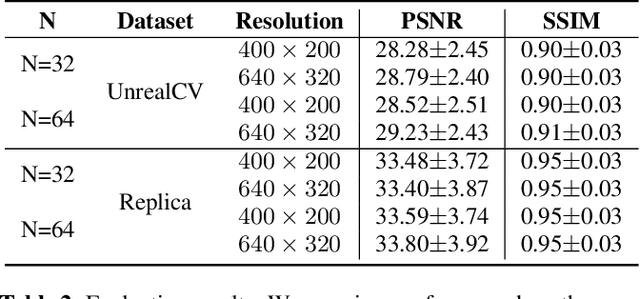
Omnidirectional video is an essential component of Virtual Reality. Although various methods have been proposed to generate content that can be viewed with six degrees of freedom (6-DoF), existing systems usually involve complex depth estimation, image in-painting or stitching pre-processing. In this paper, we propose a system that uses a 3D ConvNet to generate a multi-sphere images (MSI) representation that can be experienced in 6-DoF VR. The system utilizes conventional omnidirectional VR camera footage directly without the need for a depth map or segmentation mask, thereby significantly simplifying the overall complexity of the 6-DoF omnidirectional video composition. By using a newly designed weighted sphere sweep volume (WSSV) fusing technique, our approach is compatible with most panoramic VR camera setups. A ground truth generation approach for high-quality artifact-free 6-DoF contents is proposed and can be used by the research and development community for 6-DoF content generation.