 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Standard MoE: Mixture of Latent Experts for Resource-Efficient Language Models
Paper and Code
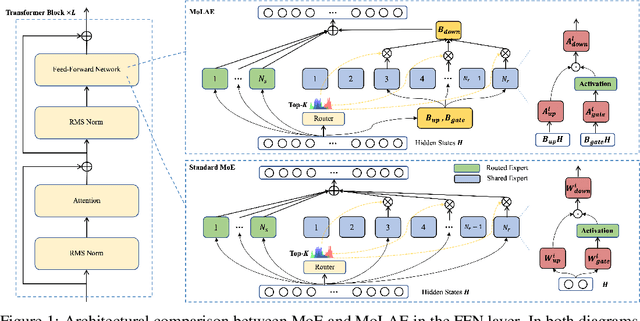


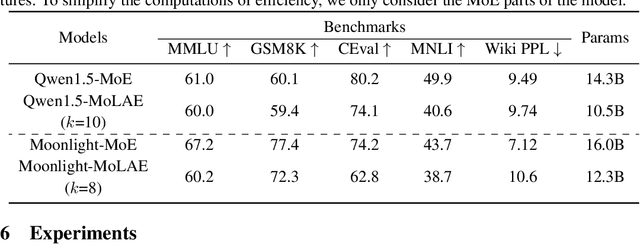
Mixture of Experts (MoE) has emerged as a pivotal architectural paradigm for efficient scaling of Large Language Models (LLMs), operating through selective activation of parameter subsets for each input token. Nevertheless, conventional MoE architectures encounter substantial challenges, including excessive memory utilization and communication overhead during training and inference, primarily attributable to the proliferation of expert modules. In this paper, we introduce Mixture of Latent Experts (MoLE), a novel parameterization methodology that facilitates the mapping of specific experts into a shared latent space. Specifically, all expert operations are systematically decomposed into two principal components: a shared projection into a lower-dimensional latent space, followed by expert-specific transformations with significantly reduced parametric complexity. This factorized approach substantially diminishes parameter count and computational requirements. Beyond the pretraining implementation of the MoLE architecture, we also establish a rigorous mathematical framework for transforming pre-trained MoE models into the MoLE architecture, characterizing the sufficient conditions for optimal factorization and developing a systematic two-phase algorithm for this conversion process. Our comprehensive theoretical analysis demonstrates that MoLE significantly enhances computational efficiency across multiple dimensions while preserving model representational capacity. Empirical evaluations corroborate our theoretical findings, confirming that MoLE achieves performance comparable to standard MoE implementations while substantially reducing resource requirements.