 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable End-to-End ML Platforms: from AutoML to Self-serve
Mar 04, 2023


ML platforms help enable intelligent data-driven applications and maintain them with limited engineering effort. Upon sufficiently broad adoption, such platforms reach economies of scale that bring greater component reuse while improving efficiency of system development and maintenance. For an end-to-end ML platform with broad adoption, scaling relies on pervasive ML automation and system integration to reach the quality we term self-serve that we define with ten requirements and six optional capabilities. With this in mind, we identify long-term goals for platform development, discuss related tradeoffs and future work. Our reasoning is illustrated on two commercially-deployed end-to-end ML platforms that host hundreds of real-time use cases -- one general-purpose and one specialized.
Generation-Distillation for Efficient Natural Language Understanding in Low-Data Settings
Jan 25, 2020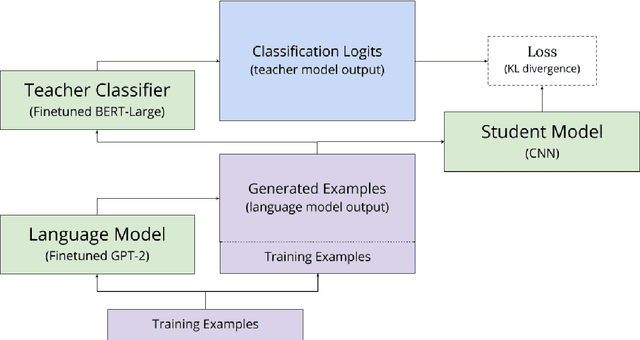



Over the past year, the emergence of transfer learning with large-scale language models (LM) has led to dramatic performance improvements across a broad range of natural language understanding tasks. However, the size and memory footprint of these large LMs makes them difficult to deploy in many scenarios (e.g. on mobile phones). Recent research points to knowledge distillation as a potential solution, showing that when training data for a given task is abundant, it is possible to distill a large (teacher) LM into a small task-specific (student) network with minimal loss of performance. However, when such data is scarce, there remains a significant performance gap between large pretrained LMs and smaller task-specific models, even when training via distillation. In this paper, we bridge this gap with a novel training approach, called generation-distillation, that leverages large finetuned LMs in two ways: (1) to generate new (unlabeled) training examples, and (2) to distill their knowledge into a small network using these examples. Across three low-resource text classification datsets, we achieve comparable performance to BERT while using 300x fewer parameters, and we outperform prior approaches to distillation for text classification while using 3x fewer parameters.