 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Enables Effective Self-Localization of Errors in LLMs
Feb 02, 2026Self-correction in language models remains elusive. In this work, we explore whether language models can explicitly localize errors in incorrect reasoning, as a path toward building AI systems that can effectively correct themselves. We introduce a prompting method that structures reasoning as discrete, semantically coherent thought steps, and show that models are able to reliably localize errors within this structure, while failing to do so in conventional, unstructured chain-of-thought reasoning. Motivated by how the human brain monitors errors at discrete decision points and resamples alternatives, we introduce Iterative Correction Sampling of Thoughts (Thought-ICS), a self-correction framework. Thought-ICS iteratively prompts the model to generate reasoning one discrete and complete thought at a time--where each thought represents a deliberate decision by the model--creating natural boundaries for precise error localization. Upon verification, the model localizes the first erroneous step, and the system backtracks to generate alternative reasoning from the last correct point. When asked to correct reasoning verified as incorrect by an oracle, Thought-ICS achieves 20-40% self-correction lift. In a completely autonomous setting without external verification, it outperforms contemporary self-correction baselines.
Internalizing Self-Consistency in Language Models: Multi-Agent Consensus Alignment
Sep 18, 2025Language Models (LMs) are inconsistent reasoners, often generating contradictory responses to identical prompts. While inference-time methods can mitigate these inconsistencies, they fail to address the core problem: LMs struggle to reliably select reasoning pathways leading to consistent outcomes under exploratory sampling. To address this, we formalize self-consistency as an intrinsic property of well-aligned reasoning models and introduce Multi-Agent Consensus Alignment (MACA), a reinforcement learning framework that post-trains models to favor reasoning trajectories aligned with their internal consensus using majority/minority outcomes from multi-agent debate. These trajectories emerge from deliberative exchanges where agents ground reasoning in peer arguments, not just aggregation of independent attempts, creating richer consensus signals than single-round majority voting. MACA enables agents to teach themselves to be more decisive and concise, and better leverage peer insights in multi-agent settings without external supervision, driving substantial improvements across self-consistency (+27.6% on GSM8K), single-agent reasoning (+23.7% on MATH), sampling-based inference (+22.4% Pass@20 on MATH), and multi-agent ensemble decision-making (+42.7% on MathQA). These findings, coupled with strong generalization to unseen benchmarks (+16.3% on GPQA, +11.6% on CommonsenseQA), demonstrate robust self-alignment that more reliably unlocks latent reasoning potential of language models.
Adaptive Step-Size Methods for Compressed SGD
Jul 20, 2022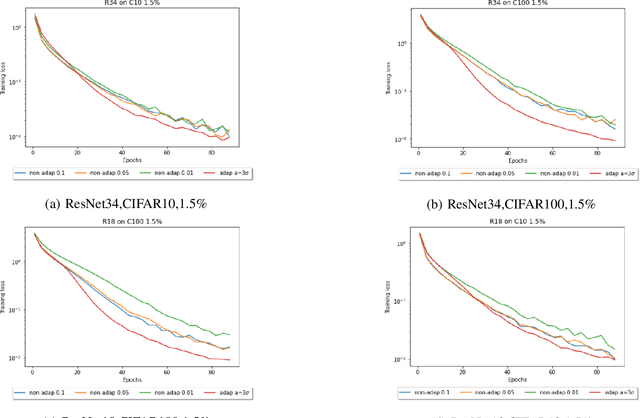
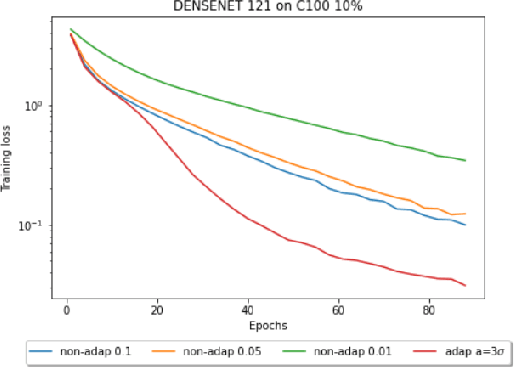
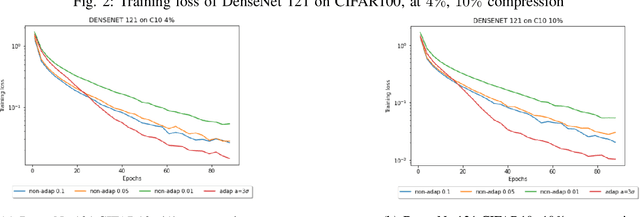
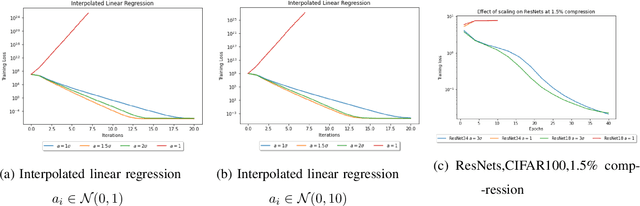
Compressed Stochastic Gradient Descent (SGD) algorithms have been recently proposed to address the communication bottleneck in distributed and decentralized optimization problems, such as those that arise in federated machine learning. Existing compressed SGD algorithms assume the use of non-adaptive step-sizes(constant or diminishing) to provide theoretical convergence guarantees. Typically, the step-sizes are fine-tuned in practice to the dataset and the learning algorithm to provide good empirical performance. Such fine-tuning might be impractical in many learning scenarios, and it is therefore of interest to study compressed SGD using adaptive step-sizes. Motivated by prior work on adaptive step-size methods for SGD to train neural networks efficiently in the uncompressed setting, we develop an adaptive step-size method for compressed SGD. In particular, we introduce a scaling technique for the descent step in compressed SGD, which we use to establish order-optimal convergence rates for convex-smooth and strong convex-smooth objectives under an interpolation condition and for non-convex objectives under a strong growth condition. We also show through simulation examples that without this scaling, the algorithm can fail to converge. We present experimental results on deep neural networks for real-world datasets, and compare the performance of our proposed algorithm with previously proposed compressed SGD methods in literature, and demonstrate improved performance on ResNet-18, ResNet-34 and DenseNet architectures for CIFAR-100 and CIFAR-10 datasets at various levels of compression.
Multiple Testing Framework for Out-of-Distribution Detection
Jun 22, 2022



We study the problem of Out-of-Distribution (OOD) detection, that is, detecting whether a learning algorithm's output can be trusted at inference time. While a number of tests for OOD detection have been proposed in prior work, a formal framework for studying this problem is lacking. We propose a definition for the notion of OOD that includes both the input distribution and the learning algorithm, which provides insights for the construction of powerful tests for OOD detection. We propose a multiple hypothesis testing inspired procedure to systematically combine any number of different statistics from the learning algorithm using conformal p-values. We further provide strong guarantees on the probability of incorrectly classifying an in-distribution sample as OOD. In our experiments, we find that threshold-based tests proposed in prior work perform well in specific settings, but not uniformly well across different types of OOD instances. In contrast, our proposed method that combines multiple statistics performs uniformly well across different datasets and neural networks.
Group Equivariant Neural Architecture Search via Group Decomposition and Reinforcement Learning
Apr 10, 2021

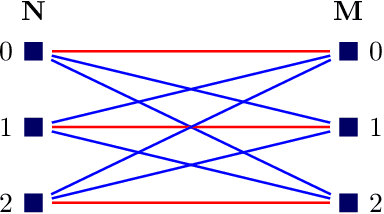

Recent works show that including group equivariance as an inductive bias improves neural network performance for both classification and generation tasks. Designing group-equivariant neural networks is, however, challenging when the group of interest is large and is unknown. Moreover, inducing equivariance can significantly reduce the number of independent parameters in a network with fixed feature size, affecting its overall performance. We address these problems by proving a new group-theoretic result in the context of equivariant neural networks that shows that a network is equivariant to a large group if and only if it is equivariant to smaller groups from which it is constructed. We also design an algorithm to construct equivariant networks that significantly improves computational complexity. Further, leveraging our theoretical result, we use deep Q-learning to search for group equivariant networks that maximize performance, in a significantly reduced search space than naive approaches, yielding what we call autoequivariant networks (AENs). To evaluate AENs, we construct and release new benchmark datasets, G-MNIST and G-Fashion-MNIST, obtained via group transformations on MNIST and Fashion-MNIST respectively. We show that AENs find the right balance between group equivariance and number of parameters, thereby consistently having good task performance.
Dynamic Spectrum Access using Stochastic Multi-User Bandits
Jan 12, 2021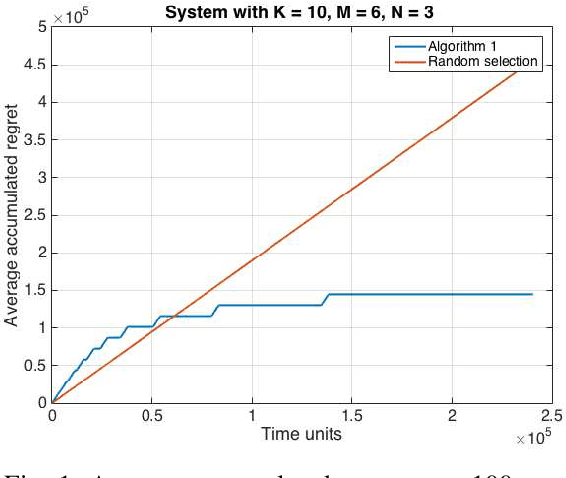
A stochastic multi-user multi-armed bandit framework is used to develop algorithms for uncoordinated spectrum access. In contrast to prior work, it is assumed that rewards can be non-zero even under collisions, thus allowing for the number of users to be greater than the number of channels. The proposed algorithm consists of an estimation phase and an allocation phase. It is shown that if every user adopts the algorithm, the system wide regret is order-optimal of order $O(\log T)$ over a time-horizon of duration $T$. The regret guarantees hold for both the cases where the number of users is greater than or less than the number of channels. The algorithm is extended to the dynamic case where the number of users in the system evolves over time, and is shown to lead to sub-linear regret.
Multi-User MABs with User Dependent Rewards for Uncoordinated Spectrum Access
Nov 01, 2019Multi-user multi-armed bandits have emerged as a good model for uncoordinated spectrum access problems. In this paper we consider the scenario where users cannot communicate with each other. In addition, the environment may appear differently to different users, ${i.e.}$, the mean rewards as observed by different users for the same channel may be different. With this setup, we present a policy that achieves a regret of $O (\log{T})$. This paper has been accepted at Asilomar Conference on Signals, Systems, and Computers 2019.
Multi-player Multi-Armed Bandits with non-zero rewards on collisions for uncoordinated spectrum access
Oct 21, 2019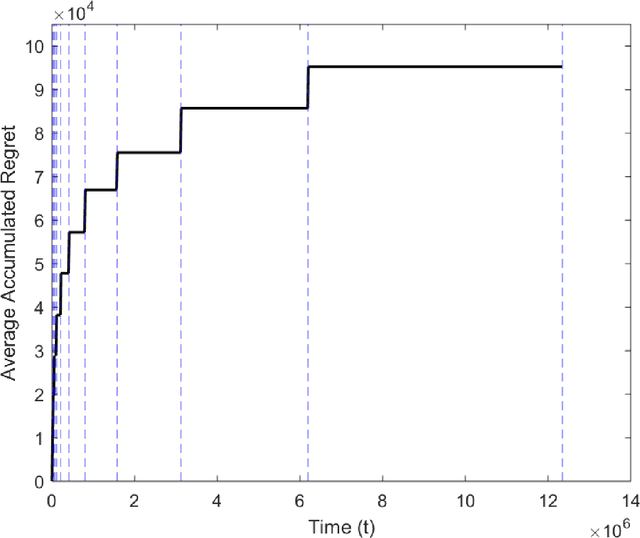
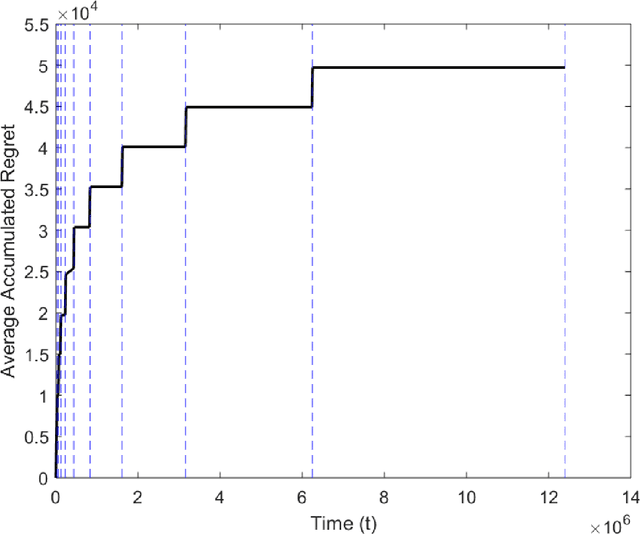
In this paper, we study the uncoordinated spectrum access problem using the multi-player multi-armed bandits framework. We consider a model where there is no central control and the users cannot communicate with each other. The environment may appear differently to different users, \textit{i.e.}, the mean rewards as seen by different users for a particular channel may be different. Additionally, in case of a collision, we allow for the colliding users to receive non-zero rewards. With this setup, we present a policy that achieves expected regret of order $O(\log^{2+\delta}{T})$ for some $\delta > 0$.