 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Step-Size Methods for Compressed SGD
Paper and Code
Jul 20, 2022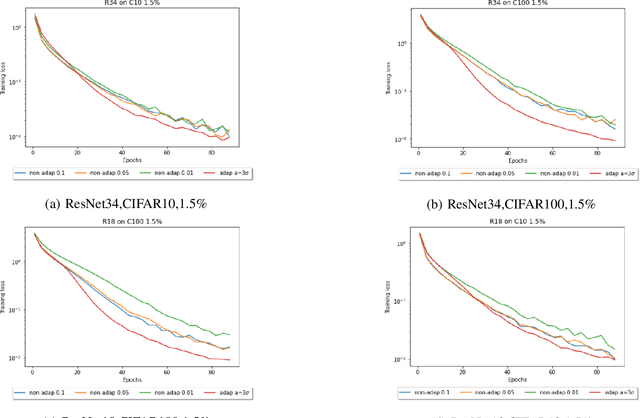
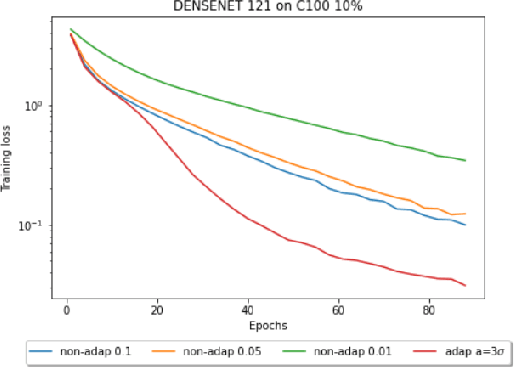
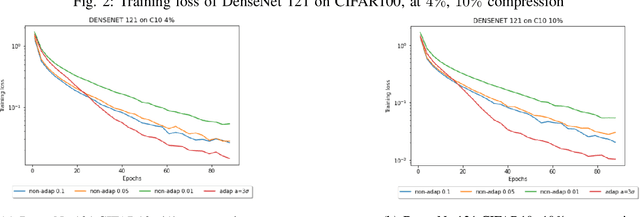
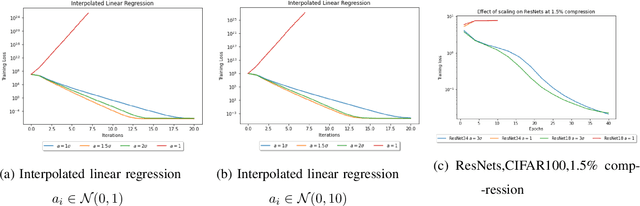
Compressed Stochastic Gradient Descent (SGD) algorithms have been recently proposed to address the communication bottleneck in distributed and decentralized optimization problems, such as those that arise in federated machine learning. Existing compressed SGD algorithms assume the use of non-adaptive step-sizes(constant or diminishing) to provide theoretical convergence guarantees. Typically, the step-sizes are fine-tuned in practice to the dataset and the learning algorithm to provide good empirical performance. Such fine-tuning might be impractical in many learning scenarios, and it is therefore of interest to study compressed SGD using adaptive step-sizes. Motivated by prior work on adaptive step-size methods for SGD to train neural networks efficiently in the uncompressed setting, we develop an adaptive step-size method for compressed SGD. In particular, we introduce a scaling technique for the descent step in compressed SGD, which we use to establish order-optimal convergence rates for convex-smooth and strong convex-smooth objectives under an interpolation condition and for non-convex objectives under a strong growth condition. We also show through simulation examples that without this scaling, the algorithm can fail to converge. We present experimental results on deep neural networks for real-world datasets, and compare the performance of our proposed algorithm with previously proposed compressed SGD methods in literature, and demonstrate improved performance on ResNet-18, ResNet-34 and DenseNet architectures for CIFAR-100 and CIFAR-10 datasets at various levels of compression.