 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Spectrum Access using Stochastic Multi-User Bandits
Jan 12, 2021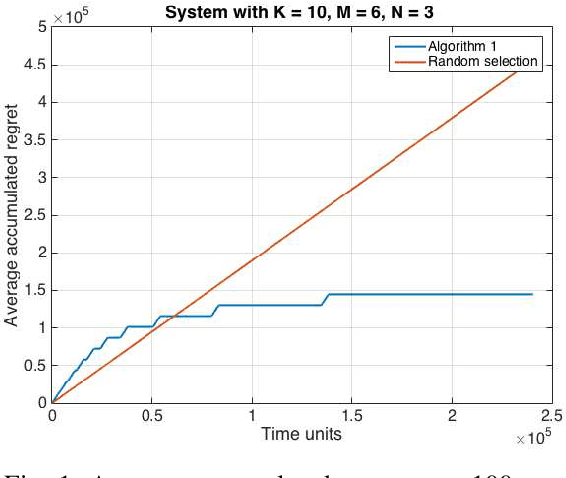
A stochastic multi-user multi-armed bandit framework is used to develop algorithms for uncoordinated spectrum access. In contrast to prior work, it is assumed that rewards can be non-zero even under collisions, thus allowing for the number of users to be greater than the number of channels. The proposed algorithm consists of an estimation phase and an allocation phase. It is shown that if every user adopts the algorithm, the system wide regret is order-optimal of order $O(\log T)$ over a time-horizon of duration $T$. The regret guarantees hold for both the cases where the number of users is greater than or less than the number of channels. The algorithm is extended to the dynamic case where the number of users in the system evolves over time, and is shown to lead to sub-linear regret.
Multi-User Multi-Armed Bandits for Uncoordinated Spectrum Access
Oct 22, 2018

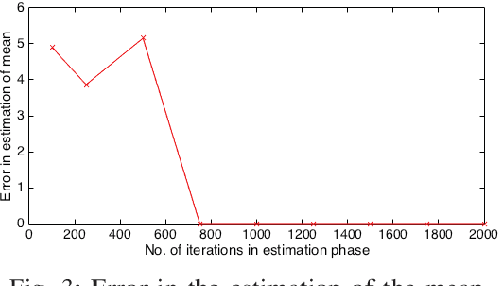
A stochastic multi-user multi-armed bandit framework is used to develop algorithms for uncoordinated spectrum access. In contrast to prior work, the number of users is assumed to be unknown to each user and can possibly exceed the number of channels. Also, in contrast to prior work, it is assumed that rewards can be non-zero even under collisions. The proposed algorithm consists of an estimation phase and an allocation phase. It is shown that if every user adopts the algorithm, the system wide regret is constant with time with high probability. The regret guarantees hold for any number of users and channels, i.e., even when the number of users is less than the number of channels. The algorithm is extended to the dynamic case where the number of users in the system evolves over time and our algorithm leads to sub-linear regret.